
Claude Opus 4.6 在 Terminal Bench 2.0(一个测试 Agent 在真实终端环境中自主执行复杂任务的基准)上排名第 33,换了一个 harness 配置后排到了第 5。
同一个模型,同样的权重,同样的能力上限——排名差了 28 位。
为什么会出现这种现象?我们都知道一个事:Coding Agent = Model + Harness,大部分人把注意力放在了模型能力上,但真正决定成败的是那个模型外面的壳,也就是Harness。
到了 2026 年,模型已经是通用品了。Claude、GPT、Gemini 在基础能力上差距不大。真正拉开差距的是 Harness——模型外面那层壳怎么搭。
Harness的组成
Harness 不是什么新概念——如果你看我之前的文章,你已经学了一整套 Harness 的零件,只是没有用这个名字叫它。
回头看一下之前的东西:
模型不会自己停下来,它会在死循环里反复调工具直到 token 耗尽。所以我们加了 max_turns 和 token 预算作为保险丝。
模型面对 50 个工具会选不准,选择准确率从 90% 掉到 50%。所以我们做了 Deferred Loading 按需加载。
模型的上下文会退化,读了 50 个文件之后前面的内容就被"遗忘"了。所以我们搭了从 soft trim 到 memory flush 的多级压缩策略。
模型不会记住你,每次对话都从零开始。所以我们设计了 MEMORY.md 和 RAG 检索系统。
模型一个人的上下文装不下,200 个文件的仓库读到一半就走神。所以我们用 Multi-Agent 把上下文拆开。
每一个组件背后,都隐藏了一个"模型做不到"的假设。 保险丝假设"模型不会自己停",压缩策略假设"模型的上下文会退化",记忆系统假设"模型不会记住你"。
这就是 Harness 的本质——一组组件,每个组件对应一个模型的局限性假设,合在一起构成了模型运行的环境。
两个根本问题
Anthropic 在用 Agent 做长时间运行的应用开发时,发现了两个反复出现的根本性问题。这两个问题不是"偶尔出 bug"这种级别——它们是系统性的,不靠 Harness 设计来应对的话,Agent 几乎无法产出可用的结果。
第一个是上下文退化。
这个我们在前面讲 Context Rot 的时候就深入讨论过了。但 Anthropic 在实践中发现了一个比 Context Rot 更深的问题——上下文焦虑。模型不只是因为上下文太满而表现下降,它还会主动偷懒:感知到上下文快满的时候,开始跳过步骤、简化回答、不调用工具。它在试图"省着用"剩余的上下文空间。
这意味着光靠压缩不够。压缩是在上下文快满时"挤一挤",但模型的焦虑行为在上下文远没满的时候就开始了——前面 Context Rot 那篇里我们引过的数据,200K 窗口在 60-70% 占用率的时候表现就开始下降了。到了 80% 左右,Sonnet 就会开始"收工"——不是因为真的装不下了,而是模型自己觉得快装不下了。
Anthropic 发现,对于某些模型(特别是 Claude Sonnet 4.5),需要的是彻底重置上下文——清空对话历史,通过文件做结构化交接,让 Agent 从一个干净的上下文开始新的工作阶段。
第二个是模型容易自以为是。
你让 Agent 做完一个功能后自己检查质量,它会怎么说?
Anthropic 的经验是:它会"自信地称赞自己的工作——即使对人类观察者来说,质量明显平庸"。模型不是故意骗你,而是它在评估自己产出的时候,会不自觉地"解释"自己的意图,把问题合理化。
这在主观任务上特别严重——设计、文案、UI 这类没有硬性标准的任务。Agent 做了一个界面,你觉得很丑,但它给自己打 9 分,理由是"布局清晰、信息层级明确"。你跟它争论也没用,它会用更多的"合理化"来解释自己的决策。
解决这个问题的方法不是让 Generator 自己反省——Anthropic 试过,效果很差。有效的方案是架构层面的分离:让一个独立的 Evaluator 来评判,而且 Evaluator 不看 Generator 的推理过程,只看最终输出。调一个独立的 Evaluator 让它变得更挑剔,比让 Generator 自我批评要容易 10 倍。
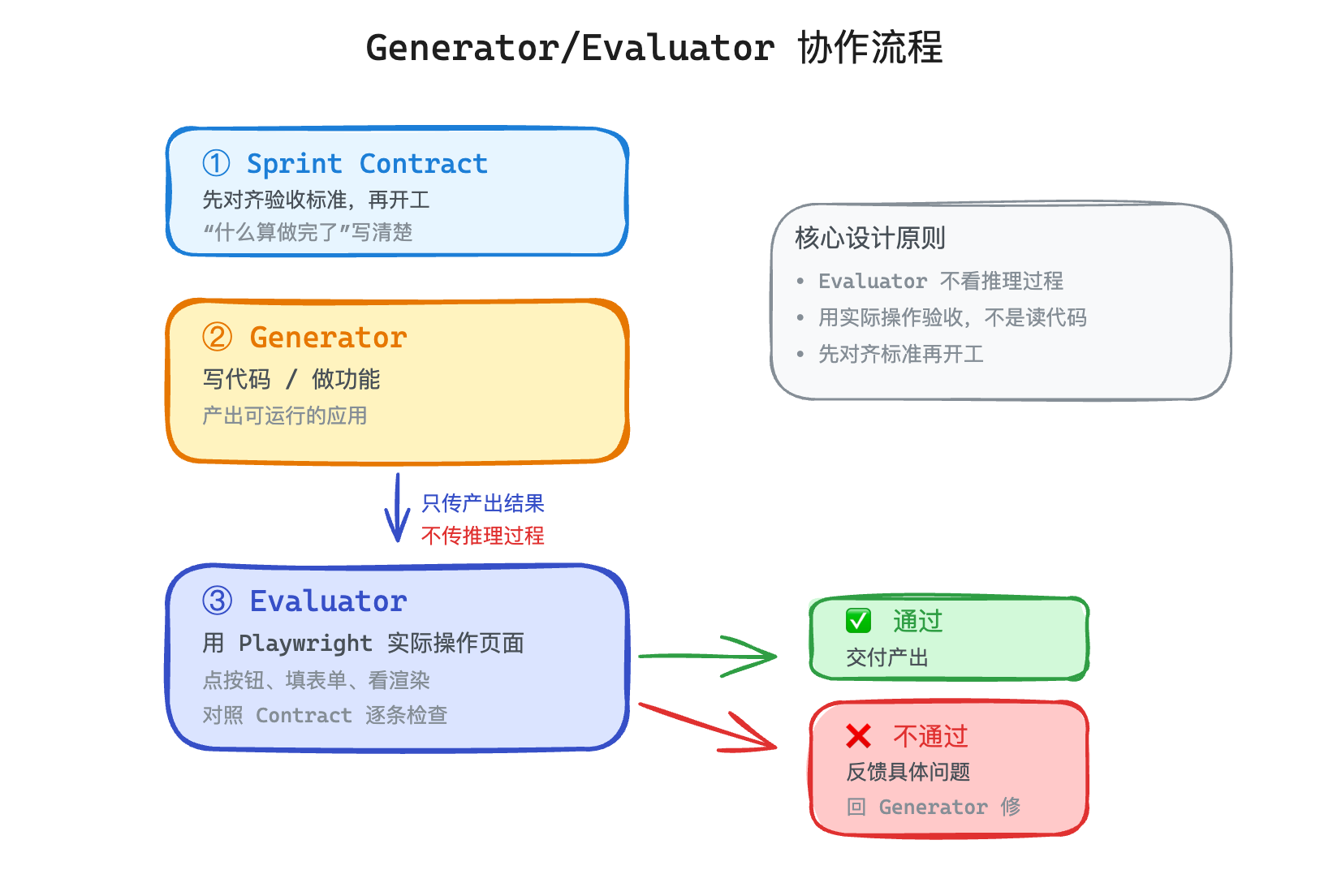
Generator/Evaluator:最经典的 Harness 模式
这就引出了 Anthropic 在实践中验证过的最核心的 Harness 模式——Generator/Evaluator 双 Agent 协作。
这个方案的灵感来自 GAN(生成对抗网络):生成和判别必须分开。Generator 负责写代码、做功能,Evaluator 负责验收。两者有几个关键的设计原则:
Evaluator 不看推理过程,只看最终输出。 这是为了防止 Evaluator 被 Generator 的推理"污染"——如果 Evaluator 看到了 Generator 的思考过程,它很容易被带跑偏,变成"理解 Generator 的意图"而不是"评判产出的质量"。
用实际操作来验收,不是读代码。 Anthropic 的 Evaluator 用 Playwright 实际操作页面——点按钮、填表单、看渲染结果。不是读代码判断"逻辑对不对",而是像真实用户一样用产品判断"体验好不好"。这个区别很重要,读代码你会不自觉地替 Generator 找借口("虽然 CSS 有点乱但逻辑是对的"),操作产品你只看到结果。
先对齐验收标准,再开始干活。 Anthropic 设计了一个叫 Sprint Contract 的机制——每个阶段开始前,Generator 和 Evaluator 先协商好"什么算做完了"。比如一个 Sprint 的 Contract 可能有 27 条验收标准,涵盖具体的功能点、交互行为、边界情况。验收标准写清楚了再动手,而不是做完了再讨论"这算不算合格"。这个思路其实跟软件工程里的 TDD(Test-Driven Development)很像——先写测试、再写代码。只不过这里的"测试"是 Evaluator 手里的验收标准。
这个模式的效果从 Anthropic 的成本数据可以看出来:单 Agent 做一个复杂应用(一个 2D 游戏制作工具),$9 跑 20 分钟,产出的东西基本不能用——勉强能跑但功能残缺、界面粗糙。用 Generator/Evaluator 完整 Harness 做同样的应用,$200 跑 6 小时,产出了一个有完整功能的可用产品。成本高了 20 倍,但产出从"不能用"变成了"能用"——这是质的区别。
他们还用同样的 Harness 做了一个数字音频工作站(DAW),总成本 $124.70,跑了 3 小时 50 分钟,其中 Planner 只花了 $0.46,三轮 Build-QA 循环花了 $115.20。几乎所有成本都在 Generator 的实际执行上,编排层的开销微乎其微——这印证了一个重要原则:编排要轻,执行要重。90% 的资源应该花在子 Agent 的实际工作上,不是花在编排层的协调上。如果你发现自己的 Harness 编排层成本占比超过了 20%,那大概率是设计过度了——你在管理 Agent 上花的精力比 Agent 干活还多。
Harness 会进化:模型变强了,壳要变薄
这是 Harness 设计里最反直觉的一条原则——你辛辛苦苦搭的 Harness 组件,可能过几个月就该删了。
Anthropic 分享了自己 Harness 的三次迭代:
V1(Claude Sonnet 4.5 时代):两个 Agent,Generator 和 Evaluator。因为 Sonnet 的上下文焦虑问题严重,Harness 里大量使用上下文重置,还借鉴了敏捷开发的做法——把大任务拆成多个小阶段(Sprint),每个 Sprint 开始前先协商好验收标准(Contract,比如"点击提交按钮后出现成功提示"),然后 Generator 做、Evaluator 按 Contract 逐条检查。这个阶段的架构还比较重。
V2(Claude Opus 4.5 时代):加到三个 Agent(Planner + Generator + Evaluator),引入了 Sprint 机制,16 个功能分成 10 个 Sprint 逐步推进。Planner 负责把用户简短的 1-4 句需求描述展开成完整的产品规格(但不过度指定技术细节),Generator 按 Sprint 逐步实现,Evaluator 每个 Sprint 后用 Playwright 走一遍验收。架构更复杂了,但产出质量也更高了。
V3(Claude Opus 4.6 时代):删掉了 Sprint 结构,删掉了上下文重置,删掉了 Contract 协商。 Evaluator 从每个 Sprint 后都跑一次,降级到最后只跑一次。整个系统变成了一个连续的工作会话,靠模型自身的 compaction(自动压缩)来管理上下文增长。架构反而更简单了。
能删的原因很直接——Opus 4.6 的 1M 上下文窗口和更强的长程一致性,让上下文焦虑不再是问题——以前需要上下文重置来"续命"的场景,现在模型自己能撑过去了。以前需要 Sprint 分段来防止模型走偏的场景,现在模型的规划能力强了,不需要人为拆分了。
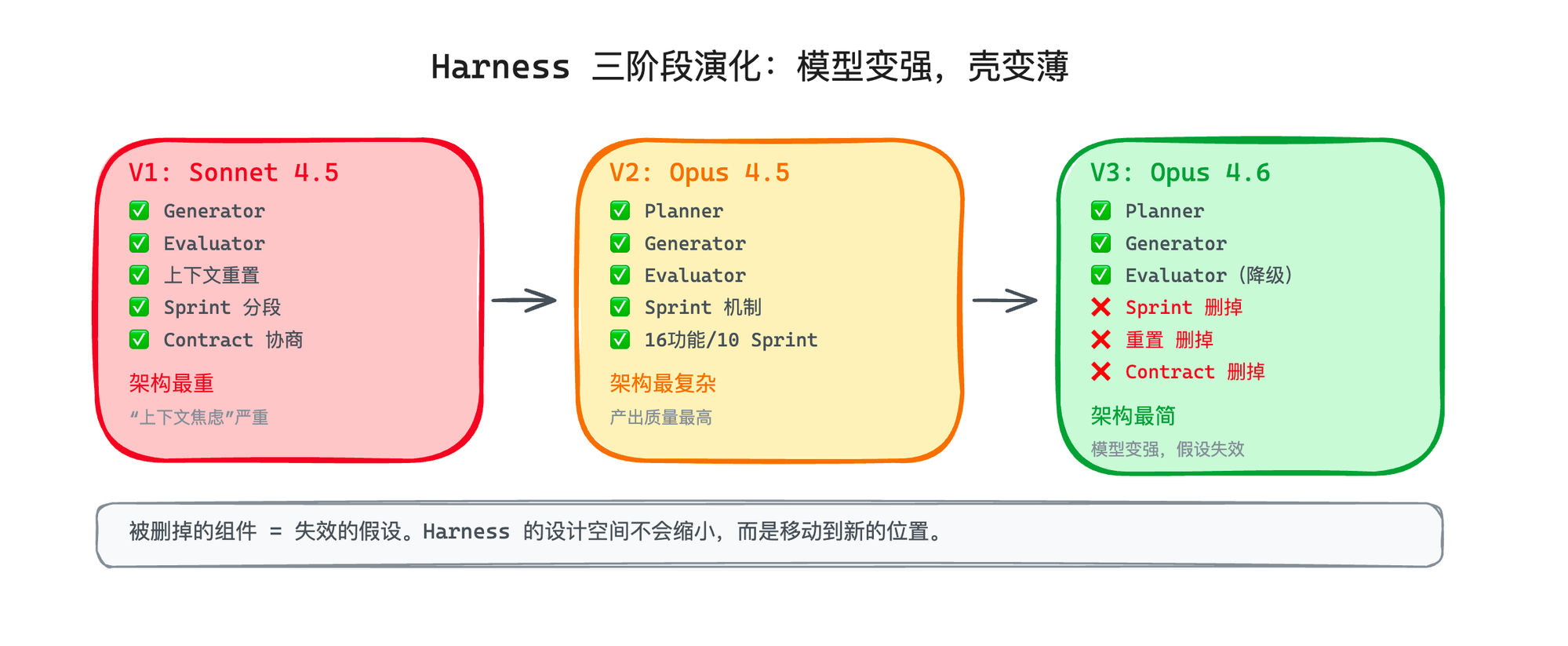
如果从更深一层去看这个变化,我们可以很容易得到这个结论:被删掉的组件 = 失效的假设。 Sprint 背后的假设是"模型没法做长程规划",Opus 4.6 推翻了这个假设,Sprint 就没必要了。
但 Anthropic 同时强调了一个重要观点:Harness 的设计重心不会缩小,而是会移动。 简单任务不再需要 Harness 了(模型直接就能做好),但新的、更复杂的任务需要新的 Harness 模式。
那好了,这对做 Agent 产品的人来说意味着什么?意味着 Harness 工程不是一次性的工作——它是一个持续演化的过程。每一次模型升级,你都需要重新审视你的 Harness,删掉失效的假设,加上新的组件来利用模型的新能力。这也是为什么 Agent 开发在 2026 年的核心竞争力从"模型能力"转移到了"搭 Harness"——模型大家都能用,但 Harness 怎么搭是真功夫。
模型足够强之后,Harness 会消失吗
看到这里你可能会想:既然模型每次升级都在删 Harness 组件,那等模型足够强了,Harness 是不是就完全不需要了?
答案是:不会消失,但会分化成两层,其中一层确实会越来越薄。
第一层是"能力补偿"——补模型做不到的事。 Sprint 分段是因为模型没法长程规划,上下文重置是因为模型有焦虑,Deferred Loading 是因为模型面对太多工具会选不准。这些组件编码的都是"模型能力不足"的假设。随着模型变强,这些假设一个一个会被推翻,对应的组件会被删掉。这一层确实在变薄。
第二层是"系统工程"——处理模型从定义上就做不了的事。 不管模型多强,有些事情它自己搞不定:
安全和权限——模型不能自己决定该不该执行
rm -rf /,这必须是外部约束。前面权限系统那篇讲过的三层防线(规则匹配、分类器判定、交互式询问),这些不会因为模型变强就不需要了。成本控制——模型不会帮你省钱。token 预算、模型路由、Prompt Cache 策略,这些是"运营"层面的事。
外部系统交互——API 有自己的规范、数据库有自己的状态、网络会超时会断连。前面 API 容错那篇讲过的 fallback 链和重试策略,这些跟模型能力无关,是物理世界的约束。
可观测性——你需要知道模型在干什么,模型自己监控不了自己。
失败恢复——进程挂了要重启、状态要持久化、要从断点恢复。
Laminar 的这篇博客也提到了这个观点:Harness 本质上不是在补偿模型的不足,而是在处理模型从定义上就做不了的事。
这跟操作系统是一个道理。CPU 越来越快、内存越来越大,但操作系统没有消失。它的某些功能简化了(比如不再需要复杂的内存换页),但核心职责——资源管理、安全隔离、进程调度,这些东西会永远存在。Harness 就是 Agent 的操作系统。 能力补偿层会越来越薄,但系统工程层会一直在,甚至随着 Agent 承担更复杂的任务而变得更重要。
怎么判断你的 Harness 该加还是该减
说了这么多,落到实操上,怎么判断你的 Harness 是不是合适?
HumanLayer 给了一条很实用的原则:每次 Agent 犯错,分析根因,加一个最小组件防止再犯。 不要提前设计——你不知道 Agent 会在哪里犯错,等它犯了再补。
反过来,每次模型升级,重新测试每个组件,删掉不再需要的。 不要让失效的假设留在系统里——它们不是无害的,多余的组件会减慢 Agent 的速度、增加复杂度、消耗额外的 token。具体做法是一次只移除一个组件,跑一轮测试看效果有没有变差——如果没变差,说明这个组件编码的假设已经不成立了,大胆删掉。
还有一条设计原则值得记住:成功应该是不发声的,只有失败才需要发出声音。 验证机制跑过了就什么都不说,只在发现问题时才往 Agent 的上下文里注入错误信息。为什么要这么做?举个例子,比如一开始每次代码修改后都跑完整的测试套件,4000 个通过的测试结果直接灌进上下文——Agent 的上下文被无用信息淹没了。
改成"通过了就沉默、失败了才输出"之后,效果就好了很多。
这跟我们前面讲工具执行管线时的思路是一脉相承的——错误信息是给模型看的,不是给人看的。验证通过的信息对模型没有价值,它只需要知道什么地方出了问题、怎么修。
最后,如果 Agent 跑完你总是不满意,但它自己觉得很好——加 Evaluator。 这就是前面讲的"自以为是"的信号。如果你发现自己总在 Agent 完成后手动返工,那不是模型的问题,是你的 Harness 缺了一个独立的质量检查环节。
参考资料
Anthropic: Harness design for long-running application development: https://www.anthropic.com/engineering/harness-design-long-running-apps
HumanLayer: Skill Issue - Harness Engineering for Coding Agents: https://www.humanlayer.dev/blog/skill-issue-harness-engineering-for-coding-agents
Anthropic: Building Effective Agents: https://www.anthropic.com/research/building-effective-agents
Terminal Bench 2.0: https://www.vals.ai/benchmarks/terminal-bench-2
Meta-Harness: End-to-End Optimization of Model Harnesses: https://arxiv.org/abs/2603.28052
Vercel: We removed 80% of our agent's tools: https://vercel.com/blog/we-removed-80-percent-of-our-agents-tools
LangChain: Improving Deep Agents with harness engineering: https://www.langchain.com/blog/improving-deep-agents-with-harness-engineering
