
智能体解剖结构(Agent Anatomy)
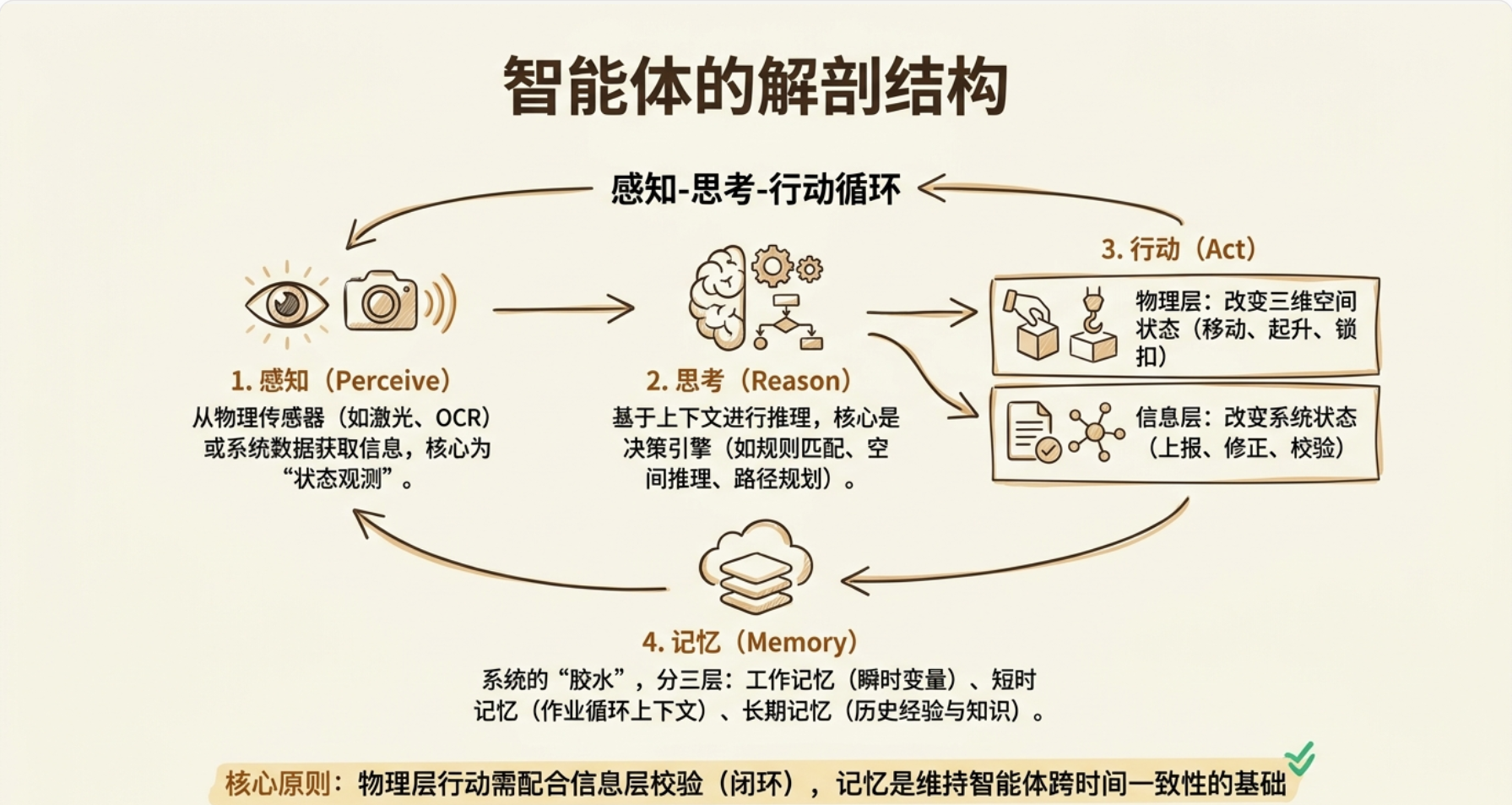
四大核心部件
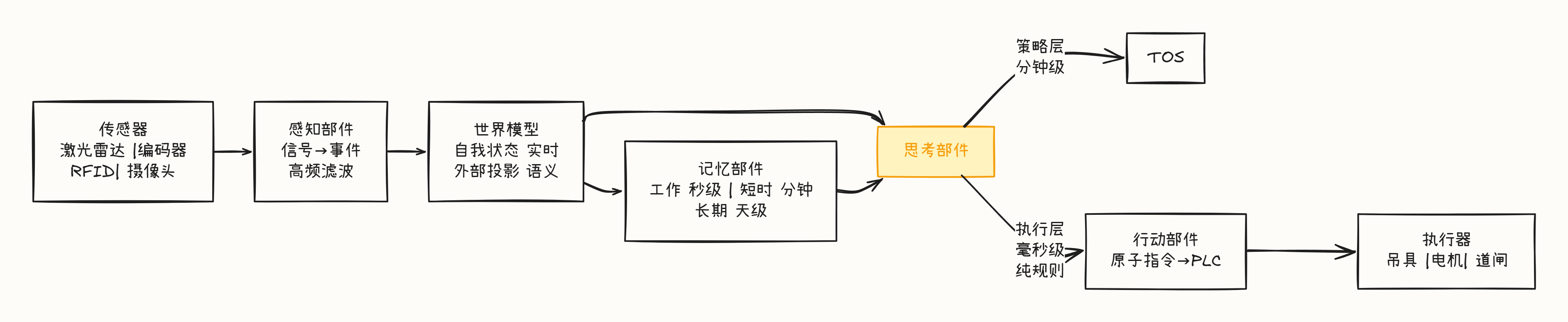
感知(Perceive)
传感器流/物理输入
系统查询、API调用
感知范式差异
思考(Reason)
感知->评估->选择->执行
决策框架统一(框架同构,策略异构)
场景特意策略(空间推理 vs 规则匹配)
行动(Act)
物理层动作(改变三维空间位姿)
信息层动作(校验,锁定,上报)
动作闭环设计
记忆(Memory)
工作记忆
短时记忆
长期记忆
做港口业务,你对桥吊的工作流程肯定不陌生:接收指令 → 移动到目标贝位 → 抓箱 → 放到指定位置。Agent 的本质结构和你熟悉的这个流程惊人地对应。
任何一个 Agent 都由四个核心部件组成:
部件 | 通俗含义 | 桥吊例子 |
|---|---|---|
感知 (Perceive) | 从环境获取信息 | 读 TOS 发来的作业指令、摄像头识别箱号、激光测距 |
思考 (Reason) | 基于当前信息做决策 | "这个箱要放船舱第 3 层,当前甲板上还有 2 层没卸完——我得先移开挡路的" |
行动 (Act) | 通过工具执行决策 | 调用小车移动 API、起升机构、吊具锁头 |
记忆 (Memory) | 跨时间保留的信息 | 刚才那个箱的实际位置和 TOS 系统里的不一致,记下来 |
这个循环在 Agent 领域叫 感知-思考-行动循环(Sense-Think-Act Loop),每完成一圈就是一次决策周期。一个桥吊 Agent 的 行动空间(能做的事)和 状态空间(需要知道的事)决定了它的全部能力边界。一个桥吊的“行动空间”应该包含以下信息:
确认或上报状态——比如吊具已经锁紧箱子、已经放到目标位置。这些不是物理动作,但必须发生,否则 TOS 不知道作业进度。
修正信息——箱号识别结果和 TOS 数据不一致时,得标记差异("这个贝位的实际箱和系统记载的差了一排")。
触发安全开关判断——"下面有人吗?舱盖板全开了吗?风大吗?" 这些条件满足才允许机械动作。
这三类有一个共同点:它们都是"改变信息世界"的动作,而不是"改变物理世界"的动作。
所以桥吊 Agent 的完整行动空间应该画成两层:
层次 | 动作类型 | 例子 |
|---|---|---|
物理层 | 改变箱子在三维空间的位姿 | 小车移动、起升、吊具锁/开锁 |
信息层 | 读、写、确认、告警 | 上报完成状态、修正箱位偏差、发出碰撞预警 |
这里的核心设计原则是:Agent 必须同时拥有两层的工具,否则它要么是"瞎的机械手",要么是"只会说不会动的参谋"。
桥吊 Agent 的记忆分三层,不是随便记,而是按信息生命周期来切的:
第一层:工作记忆(Working Memory)——秒级
当前这个作业循环的状态。一条指令从接受到完成,中间的所有瞬时变量都在这里:
当前目标贝位、目标层高
吊具状态(空载/带箱、锁紧/松开)
当前位置(小车坐标、起升高度)
当前阶段(移动中 / 下降中 / 锁紧中 / 起升中 / 横移中 / 放置中)
这一层的特征是高刷新率、用完即弃。箱子落地,大部分就可以清掉了。
第二层:短时记忆(Short-term Memory)——分钟到小时级
跨作业循环的上下文。完成一个箱子之后,这些信息还要留着:
"这艘船 05 贝位的舱盖板还没盖回去"
"刚才发现第 3 层有一个箱的 RFID 读错了,已经标记"
"堆场 B 区刚才反馈了拥堵,暂时避开"
这一层决定了 Agent 的行为连贯性——不是每条指令都从零开始重新理解世界。
第三层:长期记忆(Long-term Memory)——天级以上
跨班次的知识和经验积累:
"这个航线经常有超限箱混在标准箱里,遇到 XX 船公司多查一次"
"3 号桥吊的小车在 45 米位置有轻微抖动,降速通过"
历史作业效率曲线——哪些贝位的平均装卸时间异常
三层记忆的对应关系用一句话概括:
工作记忆 = "我现在在干什么"
短时记忆 = "这条船这班次发生过什么"
长期记忆 = "我在这干了三年,什么情况没见过"
前面讲的四个部件——感知、思考、行动、记忆——记忆是另外三个部件的"胶水":感知的结果写入记忆,思考从记忆里读上下文,行动完再更新记忆。一圈循环走通,全依赖记忆的读写一致性。
道口的业务你熟悉:集卡到闸口 → OCR 拍车牌/箱号 → 系统核验预约 → 抬杆放行 → 集卡驶入。我们现在把它拆成 Agent 的"感知"部件。
道口 Agent 需要感知的东西:
感知维度 | 来源 | 具体内容 |
|---|---|---|
车辆身份 | 摄像头 OCR | 车牌号、箱号、箱型(20/40/45尺) |
车辆物理状态 | 地磅、红外对射 | 是否有车在通道里、重量是否超限 |
闸口设备状态 | PLC/传感器 | 道闸当前位置(抬/落)、LED 屏显示内容、红绿灯状态 |
预约系统 | TOS/预约平台 | 这辆车有没有预约?预约的箱号匹配吗?时间窗口对吗? |
上下游状态 | 堆场 Agent | 目标堆区满了吗?有翻箱计划吗? |
前三项是实时传感器数据——纯粹从物理世界抓取的。后两项是系统数据——来自其他信息系统或 Agent。道口 Agent 的感知层必须同时覆盖这两类,漏掉任何一类都会出错。
和桥吊 Agent 的感知差异:
桥吊感知的核心是三维空间精度——激光、编码器、防摇传感器,追求毫米级的定位。道口感知的核心是身份匹配——"这辆车是不是它声称的那辆车"。二者的感知硬件完全不同,但在 Agent 框架里,它们都抽象为同一个结构:Observation = 传感器流 + 系统查询结果。
桥吊和道口的感知部件,在设计范式上有两个本质区别:
1. 精度需求 vs 确定性需求
桥吊感知追求精度:激光测距、编码器读数、防摇传感器——每一个都是连续的数值,噪音需要滤波,多个传感器需要融合(卡尔曼滤波那一套)。核心问题是"我的真实位置离目标还差 3.7 厘米吗?"
道口感知追求确定性:OCR 识别车牌——要么识别出来了,要么没识别出来。识别结果的置信度 > 阈值就采信,< 阈值就触发人工复核。核心问题是"我有足够把握说这辆车就是预约中的那辆吗?"
2. 主动获取 vs 被动等待
桥吊感知是主动、持续的——激光帧率可能是 50Hz,小车移动时每一帧都要读。感知驱动控制。
道口感知是事件驱动的——地磅感应到有车压上来,才触发 OCR 拍照。没车的时候,道口 Agent 的感知层几乎是静默的。控制驱动感知。
同一个"感知"标签下面,是两种完全不同的工程实现路径。这就是为什么 Agent 框架里"感知"只是抽象层——落到具体场景,架构要变。
单智能体的决策模型
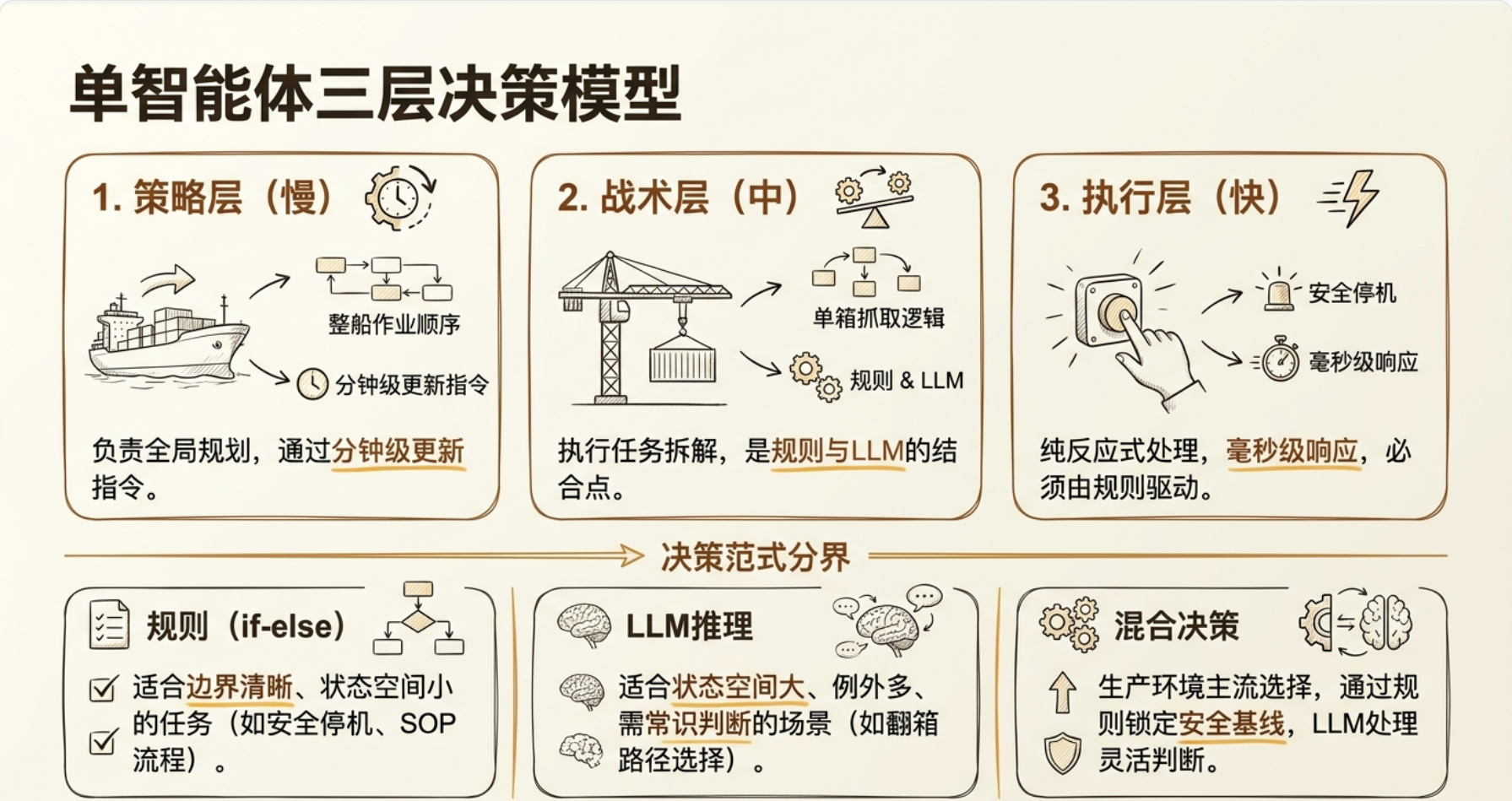
三层决策架构
你把一个桥吊 Agent 的"大脑"想象成一个黑箱:输入 = 当前状态,输出 = 下一步动作。这个黑箱内部,有三种主流实现方式:
范式 | 怎么决策 | 适合什么 |
|---|---|---|
规则驱动 | if-else 决策树。例:"如果目标贝位被挡 → 先移挡路的 → 再取目标" | 流程固定、边界清晰的场景 |
LLM 推理 | 大模型理解上下文后自己规划。"我看到目标箱被挡,周围有三个空位,我应该……" | 复杂、需要常识判断、规则写不完的场景 |
混合 | 关键安全决策用规则锁死,非安全决策交给 LLM 灵活处理 | 生产环境最常见的选择 |
我们先看第一个最基本的问题——一条指令进来,Agent 应该先做计划再执行,还是边看边反应?
桥吊 Agent 的思考部件内部,实际上有三层:
PLAINTEXT
┌──────────────────────────┐
│ 策略层(慢) │ 整船作业顺序规划,分钟级更新
│ → 先计划再执行 │
├──────────────────────────┤
│ 战术层(中) │ 单箱操作选择,秒级决策
│ → 快决策,轻计划 │
├──────────────────────────┤
│ 执行层(快) │ 运行中的打断/安全停机,毫秒级
│ → 纯反应 │
└──────────────────────────┘一个关键问题来了:这三层各自应该用规则(if-else)还是用 LLM 推理?规则和 LLM 的分界线:
规则适合"状态空间小、边界清晰"的决策
LLM 适合"状态空间大、需要常识推理、例外多"的决策
所以三层之间的指令流是:
PLAINTEXT
策略层 ──粗粒度指令──▶ 战术层 ──原子动作序列──▶ 执行层
▲ ▲ ▲
│ 打断 │ 打断 │ 打断(安全停机)
│(加急箱重新排序) │(感知异常需换策略) │核心要点
①三层决策架构:策略层做分钟级规划(LLM为主)、战术层做秒级方案选择(混合模式)、执行层做毫秒级安全响应(纯规则)。
②规则vsLLM的切换信号:if嵌套≥3层、同一分支频繁修改、状态空间不可枚举——就该切LLM。
③加急/异常在每一层都可以打断上层的计划,形成闭环。
两层地基搭好了:解剖结构 → 决策模型。现在进入第三节:状态管理与世界模型。
决策范式边界
规则驱动
状态空间小
边界清晰
安全关键决策必须用规则
LLM推理
复杂常识判断
状态空间大
避免规则组合爆炸
混合模式
规则做安全过滤
LLM做灵活判断
动态反馈流
策略下发
战术展开
执行反馈
智能体世界模型与状态管理
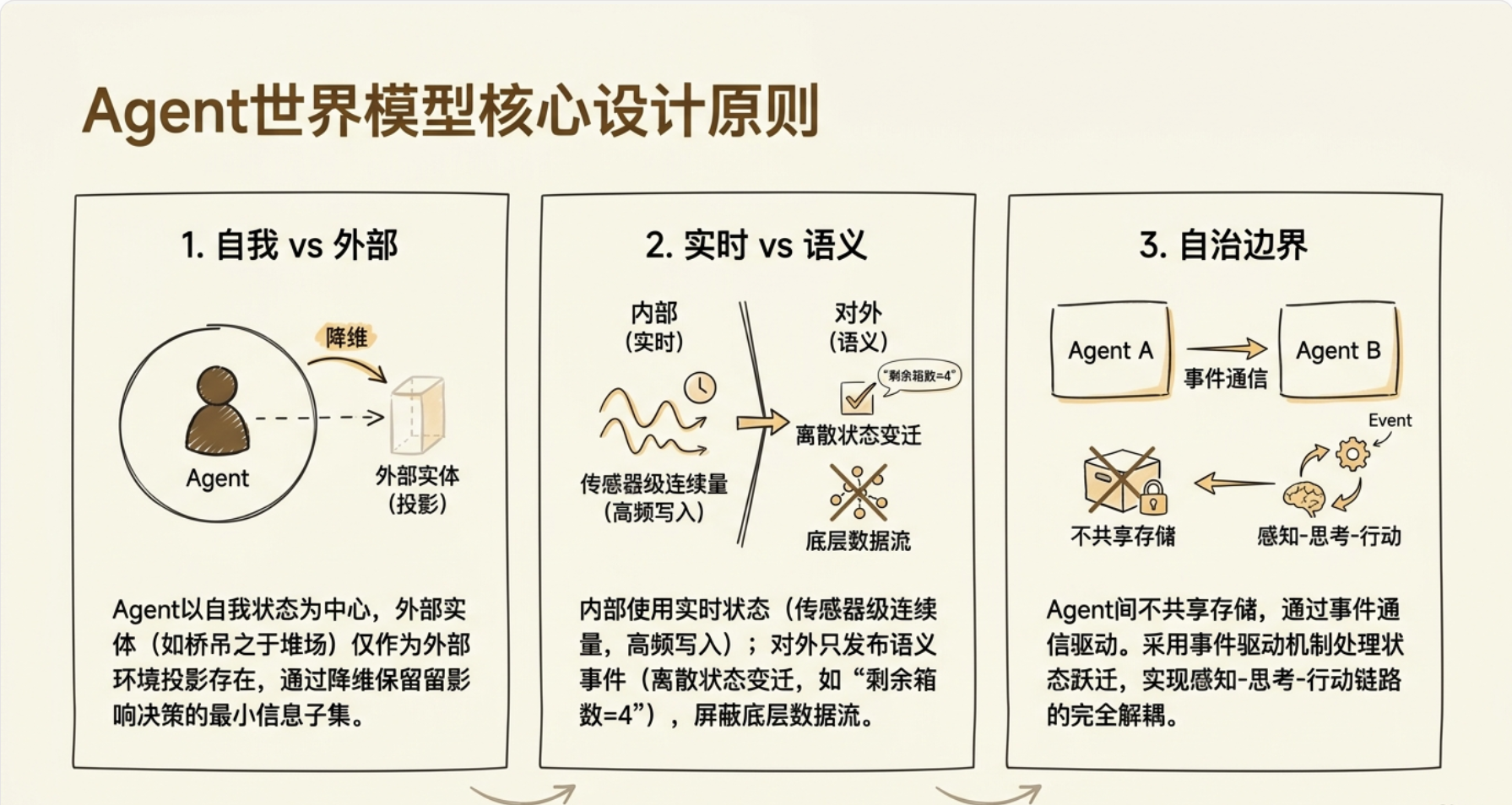
核心原则
自我VS外部
核心设计原则:每个 Agent 的世界模型 = 自我状态 + 外部环境投影。同一个物理实体(比如桥吊),在堆场 Agent 眼里只是一个"会变的位置+任务进度"——它不需要知道桥吊的吊具电机电流。
实时VS语义
但是一个核心设计问题:世界模型里有两类状态,它们的读写约束完全不同:
实时状态(位置、速度、传感器读数):高频写入、低延迟读取、不允许脏读
语义状态("箱已装船"、"道口拥堵"):低频更新、需要保障最终一致性、但允许短暂不一致
例子:堆场 Agent 做翻箱决策时,不需要知道"吊具离地几厘米",它只需要知道一个高层的语义事件——"桥吊什么时候腾出位置"。
正确的设计是:
桥吊 Agent 维护实时状态(传感器级),但它对外只发布语义状态——"已完成第 3 箱"、"预计 45 秒后完成"
堆场 Agent 的世界模型只存桥吊的语义投影:任务进度、预估完成时间、当前忙闲状态。绝不去订阅吊具的传感器流
这其实就是在说:每个 Agent 的世界模型对外部实体的建模是降维的——只保留影响自己决策的最小信息子集。桥吊的完整状态空间可能有几十个连续变量,但堆场只需要 3-4 个离散标签。这就解决了矛盾场景:语义状态和实时状态冲突时,堆场 Agent 根本不知道实时状态的存在——它只看语义层,所以不存在"信哪个"的问题。一致性由桥吊 Agent 自己负责:在语义状态未确认前不发"已完成"事件。
自治边界
第三个关键设计点——世界模型的自治边界:每个 Agent 只维护自己决策所必需的最小状态集,对外部实体只保留"语义投影"。三个 Agent 之间不共享状态存储,只通过事件通信。
现在我们有了三个核心原则:
自我 vs 外部:世界模型以自身为中心,外部实体只保留投影
实时 vs 语义:内部用实时状态,对外只发布语义事件;外部信息以语义状态摄入
自治边界:Agent 之间不共享状态存储,只通过事件通信
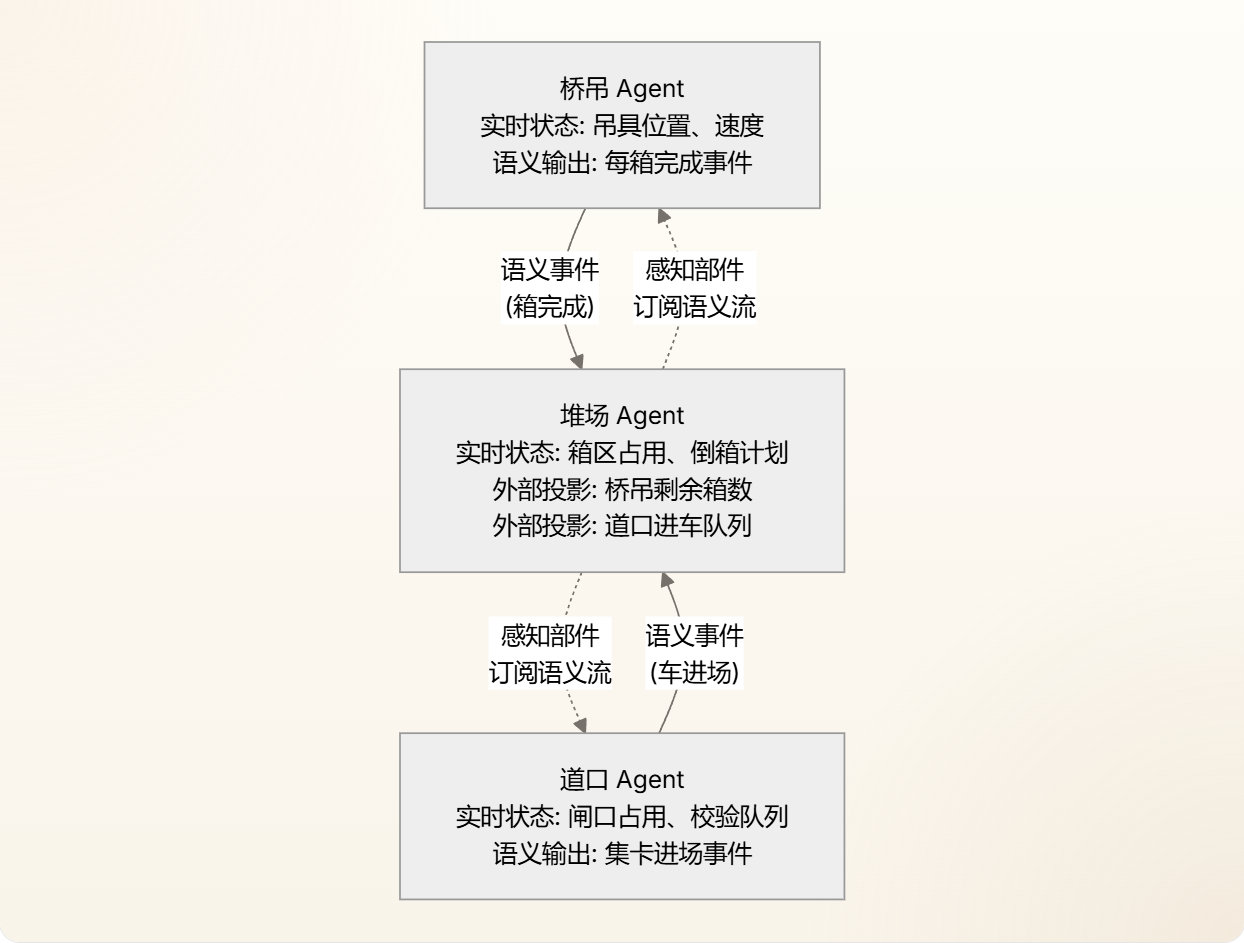
那回到桥吊和堆场的协作——桥吊完成一箱后,发了一个"第 3 箱已完成"的语义事件。堆场 Agent 收到后,在自己的世界模型里更新了什么?更重要的是,它怎么知道自己现在该行动了?
堆场 Agent 收到"第 3 箱已完成"后,它更新自己世界模型里的一个字段:桥吊A.剩余箱数 = 4(原来是5)。这个更新动作本身不触发任何决策——它只是把世界模型变"脏"了。
真正让堆场 Agent "动起来"的是触发条件。常见的设计有几种:
一种叫事件驱动(event-driven):"桥吊剩余箱数从 5 变 4"这个变化本身就是一个事件,堆场 Agent 的感知部件检测到这个变化后,把"该不该翻箱"推给思考部件去判断。
一种叫周期性轮询(polling):思考部件每 5 秒扫一遍世界模型,"桥吊还剩几箱?哦,4 箱了,快腾出位置了——启动翻箱计划"。
还有一种叫条件触发器(condition trigger):在世界模型里预先设定规则——"当桥吊剩余 ≤ 2 时,触发翻箱决策"。
翻箱场景天然适合事件驱动。原因是翻箱的触发条件是一个状态跃迁——"剩余箱数从 5 变 4"和"剩余箱数从 4 变 3"对"是否需要启动翻箱"有本质不同的含义。轮询可能扫到"还剩 4 箱"然后等了 5 秒再扫"还是 4 箱"——没变化就浪费了一次检查,而有变化时又可能错过了最佳窗口。
事件驱动还有一个工业级的好处:解耦。桥吊 Agent 不需要知道堆场 Agent 什么时候检查、检查什么——它只管发布事件。堆场 Agent 的感知部件订阅桥吊的语义事件流,变化发生 → 推送 → 思考部件介入。两个 Agent 的开发、测试、部署完全独立。
那到这里,我们把世界模型的核心骨架搭起来了。用一张结构图收束:
三类触发机制的选择信号
事件驱动:状态跃迁有意义,且错过跃迁会有后果(如翻箱窗口) 条件触发器:阈值明确,状态单调变化(如水位越线报警) 周期性轮询:状态变化无明确跃迁,或需要心跳探测对端存活
做个示例:
假设场景:道口 Agent 通知"一辆加急集卡已进场",堆场 Agent 收到这个事件后,它的感知部件、思考部件、行动部件、记忆部件,分别要做什么?世界模型在这中间起什么作用?
加急集卡进场场景:堆场 Agent 处理链路
1. 感知部件接收事件 道口 Agent 发布语义事件:{事件类型: 集卡进场, 优先级: 加急, 集卡ID: T-042, 预约箱号: CTN-8812, 时间戳: 14:32:05}
感知部件不做判断,只做滤波和格式化——验证事件完整性(五要素齐全)→ 更新世界模型的外部投影区:道口状态.进车队列 追加一条 T-042(加急)。
2. 世界模型变"脏",触发思考部件
这里不调感知部件——感知部件只负责收事件。真正触发的是条件触发器:世界模型检测到 进车队列 里出现了 优先级=加急 的条目,这是一个预先定义的触发信号 → 唤醒思考部件。
3. 思考部件决策
思考部件从世界模型读取当前快照:
桥吊还剩 8 箱,预估 6 分钟后腾出位置
堆场 H 区有 3 个可用倒箱位
当前有 2 辆普通集卡正在等待
CTN-8812 的预约贝位是 A-12
决策:加急箱需插队。翻箱计划调整为——优先为 A-12 贝位清出通道,现有普通集卡 task 挂起。输出战术指令:{动作: 启动翻箱, 目标贝位: A-12, 倒箱候选区: H区, 时限: 120秒}。
4. 行动部件执行
行动部件收到指令,拆解为原子动作序列:发指令给 RMG → 确认 CTN-8812 箱位 → 搬移挡路箱到 H 区 → 标记 A-12 通道就绪。同时发送信息层动作:向道口 Agent 回复 {集卡T-042: 通道就绪, 引导至A-12}。
5. 记忆部件写入
工作记忆:当前翻箱序号的计数、临时状态锁("A-12 正在翻箱,禁止其他操作") 短时记忆:加急任务记录 {T-042, CTN-8812, 完成时间, 是否超时} 长期记忆:加急模式触发频率统计,后续用于优化桥吊的预留策略
世界模型的核心作用一句话:它是各部件的"共享黑板"——感知往里写,思考往外读,行动改完写回去,记忆归档后清出工作区。没有世界模型,四个部件就是四个不知道对方在干什么的孤岛。
核心要点
①世界模型三原则:自我vs外部(以自身为中心,外部只保留投影)、实时vs语义(内部用实时,对外只发语义事件)、自治边界(Agent间不共享状态存储,只通过事件通信)。
②事件驱动是最适合港口场景的触发机制——状态跃迁有意义、解耦桥吊堆场道口的开发与部署。
③世界模型是四部件的"共享黑板":感知往里写、思考往外读、行动改完写回去、记忆归档。
多智能体通信(Multi-Agent Communication)
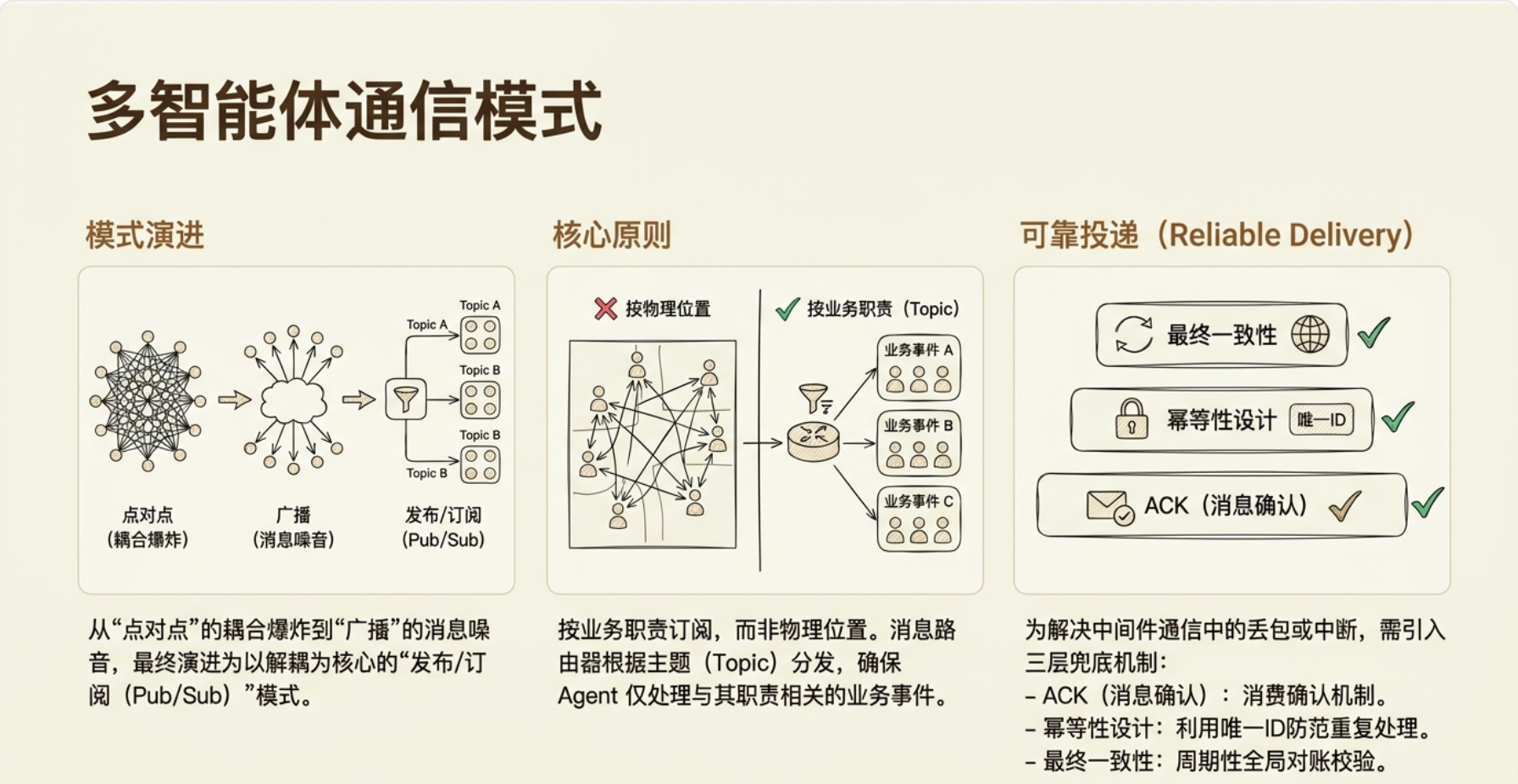
通信模式演进
桥吊、堆场、道口三个 Agent,谁和谁说话、说什么、怎么说。刚才你已经摸到了事件的边,现在把它结构化。
一个经典的分布式系统岔路口。解决这个问题的核心思路是:把"谁发消息"和"谁收消息"解耦——让发件人不知道收件人是谁,收件人也不知道发件人是谁,中间由一个"消息路由器"根据消息的主题来决定谁该收到。
在港口场景里,这条规则可以这样落地:
道口只喊一句话:"事件类型 = 加急车进场,载荷 = { 车牌号, 箱型, 时间 }"
它不需要知道谁在听。而堆场 Agent 提前声明过:"我订阅'集卡进场'类事件",中控调度声明过:"我订阅所有'加急'类事件",桥吊什么都没订阅——它压根不知道这回事。
这条路在分布式系统里叫 Pub/Sub(发布/订阅),也是多 Agent 通信中最基础的解耦模式。
点对点(Point-to-Point)
维护成本高
两个 Agent 之间有确定的、一对一的事务关系(比如中控下发"执行任务 X"给桥吊)
广播(Broadcast)
噪声干扰严重
真正的全局事件,比如"码头紧急停机"
发布/订阅(Pub/Sub)
主题路由
按职责订阅(原则:职责优先,非物理位置)
Pub/Sub 模式在 Agent 系统里的核心设计原则:按职责订阅,而非按物理位置。 道口和桥吊虽然同属一个码头,但职责完全不重叠——桥吊管"船-岸"的箱流转,道口管"岸-陆"的车流转。消息通路应该跟着职责走。
Pub/Sub 解耦了"谁发谁收",但引入了一个新问题。消息不是直接送达的,中间有路由器。如果道口发出"加急车进场",而堆场 Agent 因为网络闪断没收到这条消息——谁来兜底?
Pub/Sub 模式下,消息不是道口直接塞给堆场,而是经过一个中间件(消息队列)中转。道口发出消息 → 消息队列持久化 → 堆场从队列里拉取。
网络闪断的问题不在于"消息丢了"——好的消息队列(比如 RabbitMQ、Kafka)会落盘持久化,道口发成功了就不会丢。真正的问题是:堆场没收到,但道口以为发出了。
这时候兜底的机制有三个层面:
消息确认(ACK):堆场消费完一条消息后,显式回一个"我处理完了"。没回 ACK,消息队列就知道这条没被处理,可以重投或保留。
幂等性设计:堆场收到"加急车进场"这条消息两次(重投导致的),它处理第二次时结果和第一次一样——不会把同一辆车登记两次。这需要消息带唯一 ID。
最终一致性兜底:如果真出了极端情况(消息队列挂了),还有周期性对账——比如中控调度每隔 N 分钟把"当前在港加急车列表"和道口的"已入场加急车列表"做一次比对,发现缺口就补。
这套机制有一个通用的名字叫 可靠投递(Reliable Delivery),是 Pub/Sub 模式在工业级系统里的标配。
核心要点
①三种通信模式各有适用场景:点对点用于一对一确定性事务(如中控下发任务),广播用于全局紧急事件(如码头停机),Pub/Sub是日常业务通信的主力模式。
②Pub/Sub的核心价值是解耦——发件人不知道收件人是谁,按主题路由而非按发送者路由。
③Agent按职责订阅消息、而非按物理位置——道口不关心桥吊卸箱,桥吊不关心加急车进场。
④可靠投递三层保障:消息ACK + 幂等性设计(消息带唯一ID)+ 周期性对账兜底。
智能体任务分解与分配
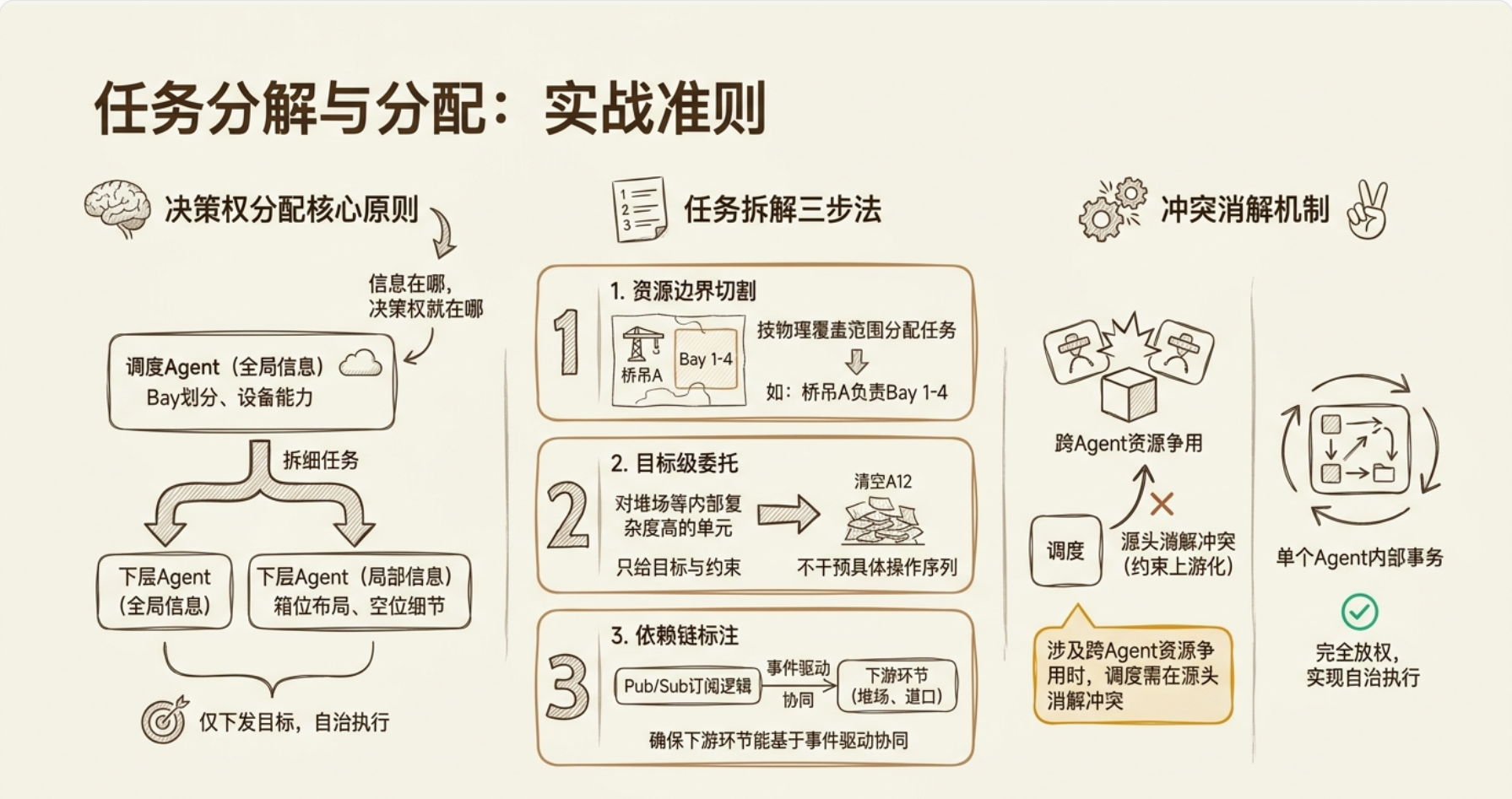
拆解原则
在一个多智能体系统中,任务分解不再是某个调度员在脑中完成的隐性操作,而是系统行为。
假设中控收到一个高层指令:「卸载 MSC-2025-04 号船,共 500 箱」。把它交给一个调度 Agent 来处理。你说它要"自动拆",那这个调度 Agent 拆出来的第一层产物可能是:
计划层指令:桥吊 A 负责 Bay 1-4 的 120 箱,桥吊 B 负责 Bay 5-8 的 130 箱…… → 堆场收到「箱位已空」后安排翻箱和堆存 → 道口收到「堆场已备好」后安排集卡进场
每一层指令传递下去时,下层 Agent 看到的不是「拆船的宏大叙事」,而是一个它能力范围内的具体任务。
在正常流程下,调度 Agent 拆完「卸 500 箱」这个计划后,它应该持续追踪每一个子任务的执行进度.这样他才能在桥吊A卡住时知道“Bat3还剩多少箱没卸,预估A还要多久恢复”,然后做出合理的重分配决策。但这种"持续追踪"也有一个代价——调度 Agent 的中心化程度变高了。我们来做个思维实验:假设港口有 8 台桥吊、3 个堆场、6 个道口同时作业。调度 Agent 每秒收到几十条状态更新——"桥吊 C 卸完第 47 箱"、"堆场 B 箱位 A12 已占"、"道口 3 号集卡进场"。它需要把所有子任务的状态、依赖关系、预估时间都维护在内存里。
如果其中一个桥吊突然离线 10 秒(网络抖动),调度 Agent 错过了它期间的几个状态更新,等它恢复时,调度 Agent 该怎么做?是信任恢复后桥吊自报的当前状态全量同步,还是让调度去"推演"失踪期间理论上发生了什么?
它触及了分布式系统里一个经典矛盾:"全量同步"和"推演"各有利弊,而且在不同场景下选择不同。
让我直接讲清楚——
方案一:信任自报状态(全量同步) 桥吊 A 恢复后,它把自己的当前状态一股脑发给调度——"我现在在 Bay 3、还剩 45 箱、吊具正常"。调度直接覆盖旧状态,继续派活。好处是简单,代价是那失踪的 10 秒里可能已经发生了问题(比如桥吊 A 其实卸错了一个箱),调度会基于"看似正确"的数据继续决策,直到后续翻箱时才炸雷。
方案二:推演缺失窗口 调度根据收到的最后一条消息("桥吊 A 在 Bay 3 卸第 30 箱")加上桥吊 A 的已知卸箱速率,推算出"理论上现在应该卸到第 34 箱"。然后等桥吊 A 恢复后,拿这个推演值和它自报的作比对。好处是能发现偏差,代价是推演本身可能和现实不一致(比如桥吊 A 不是因为网络抖动而是真的机械故障),以及推演逻辑会让调度 Agent 变得很重。
工程上通常的做法是:不推演,用最终一致性兜底。 调度信任恢复后的全量同步,而在"卸错箱"这类后果严重的场景,由堆场 Agent 来做独立校验——堆场收到的箱和调度说"应该到的箱"对不上,就触发异常事件。这就是我们过去提到的"周期性对账"思路。
在你们的港口作业里,有没有那种"拆完之后,谁干谁决定细节"的任务?比如调度说"把 A12 箱位清出来",但清哪个箱子、怎么移,具体由谁决定?
港口作业里,这个分工其实天然存在。拿你说的场景举例:
调度说:「把 A12 箱位清出来」
这句话本身就是一个"目标级任务"——它说清楚了要达成什么(A12 是空的),但没说怎么做。接下来谁决定"清哪个箱子、怎么移"?
答案是堆场 Agent。因为只有堆场知道 A12 上面压了几个箱、哪些箱可以移到别处、哪里有空位。调度不知道这些细节——它也不需要知道。调度只需要知道"A12 什么时候能清空",好决定道口的集卡什么时候发。
这就是任务分解里一个核心分层:
层级 | 谁 | 任务粒度 | 例子 |
|---|---|---|---|
上层(调度) | 调度 Agent | 目标 / 约束 | 「清空 A12 箱位」 |
下层(执行) | 堆场 Agent | 操作序列 | 「把 A12-3 移到 B07-2,然后把 A12-2 移到 C11-1」 |
调度给堆场的不是"分派"而是"委托"——我把这个目标交给你,你怎么做是你的自治范围,我只关心结果。
本质区别在于"拆细"还是"拆粗"取决于信息掌握在谁手里:
场景一:卸船 500 箱 → 拆得细
调度拆成「桥吊 A 负责 Bay 1-4、120 箱」,这个粒度是调度能做到的。因为 Bay 的划分、箱量分布、各桥吊的物理覆盖范围——这些信息调度全都有。它不需要问桥吊 A "你能管哪些 Bay",调度一开始就知道。
信息集中在上层 → 上层可以拆细。
场景二:清空 A12 → 拆得粗
调度只说「把 A12 清空」,不拆具体的移箱序列。因为 A12 上面压了几个箱、哪些箱可以移去哪个空位——这些信息只有堆场有,调度没有。如果调度硬要拆细,它就得先问堆场要一堆数据,那就变成调度什么都管、但什么都管不好的「神级调度员」。
信息分散在下层 → 上层只定目标,下层自主展开。
所以实战中的任务拆解原则就一条:
拆到"委托方拥有足够信息做决策"的最细粒度为止。 超过这个粒度,就改为委托(给目标+约束,不拆操作序列)。
卸船分配:调度有全局信息 → 拆到 Bay 级和箱数。 清箱位:堆场有布局信息 → 调度只给目标。 堆场排位:堆场知道空位分布 → 调度只管"这批箱要存"。
这三条线合在一起,调度 Agent 发布的是三层不同粒度的任务:细拆指令、高维目标、以及带约束的委托。
那假如堆场回来说"A12 清不了,因为没空位了"——调度 Agent 这时候应该做什么?
两种任务的本质不同在于"下属 Agent 有没有独立完成目标所需的信息":
卸船 500 箱——调度拆得细。
为什么?因为桥吊之间存在资源冲突。Bay 1-4 和 Bay 5-8 不能重叠,桥吊 A 和桥吊 B 的作业区域必须互斥。如果只丢给每个桥吊一个模糊的「你多干点」,它们各自看不到全局,可能两台桥吊冲向同一个 Bay,撞在一起。
所以调度必须拆到每一台桥吊的具体作业范围——这是约束上游化:把冲突在源头消解掉,不让底层 Agent 自己打架。
清空 A12 箱位——调度拆得粗。
为什么?因为清空一个箱位不存在跨 Agent 的资源冲突。A12 就是堆场 Agent 自己的地盘,箱怎么移完全在它内部。调度不需要、也没能力去算 A12 上面具体压了几个箱——那些数据在堆场的记忆里。
这是自治下放:当事务不跨边界时,让持有信息的 Agent 自己决策,上层只管结果。
规则总结:
跨 Agent 存在资源争用(空间、时间槽、设备)→ 上层拆细,做冲突消解
事务完全在单个 Agent 内部边界内 → 上层只给目标,下层自治执行
任务分解的核心分层逻辑:直接给你实战中的任务分解规则,不绕弯了。
调度 Agent 拿到"卸船 500 箱"后的拆解流程:
第一步:按资源边界做一个初始切割。 把 500 箱按 Bay 分布切成几块,分配给能物理覆盖那些 Bay 的桥吊——「桥吊 A 负责 Bay 1-4,约 120 箱」。这一步调度自己做,因为它有全局的 Bay 布局和桥吊作业范围。
第二步:遇到无法拆细的部分,改为委托。 拆到"箱位的具体操作"这一层就停住。调度不告诉堆场"你把 A12-3 移到 B07-2",因为箱位分布是堆场的内部状态。调度只给目标——「把这批箱存了」「把 A12 清出来」——让堆场自己展开成移箱序列。
第三步:识别跨 Agent 的依赖链。 「卸船」这个任务不是独立的——它往下会触发「堆场需要安排箱位」「道口需要派集卡」。调度在拆的时候要标注这些依赖:桥吊卸完 Bay 3 → 堆场收到空间释放 → 道口可以放下一批集卡。这些是调度在 Pub/Sub 里要订阅的关键事件。
核心判断准则就一条:
信息在哪,决策权就在哪。 全局信息(Bay 划分、箱量分布、设备能力)→ 调度拆细。局部信息(箱位布局、堆场空位、道口排队)→ 委托下层,只给目标不给步骤。
加一条兜底: 跨 Agent 有资源冲突的(比如两个桥吊的工作范围可能重合),调度在分配时就消解冲突,不让底层自己打架。单 Agent 内部的操作,调度完全不插手。
核心要点
①任务分解的唯一准则:信息在哪,决策权就在哪。全局信息(Bay划分、箱量分布)→ 调度拆细。局部信息(箱位布局、堆场空位)→ 委托下层。
②约束上游化:当跨Agent存在资源冲突时,调度在分配时就消解冲突,不让底层自己打架。
③三种任务粒度:细拆指令(带具体参数)、高维目标(只说结果)、带约束的委托(给边界条件后让下层自治)。
④依赖链:卸船→堆场安排箱位→道口派集卡,调度通过Pub/Sub订阅关键事件来追踪链条推进。
异常与同步(中心化 vs 自治)
全量同步
推演模式
异常机制与容错设计
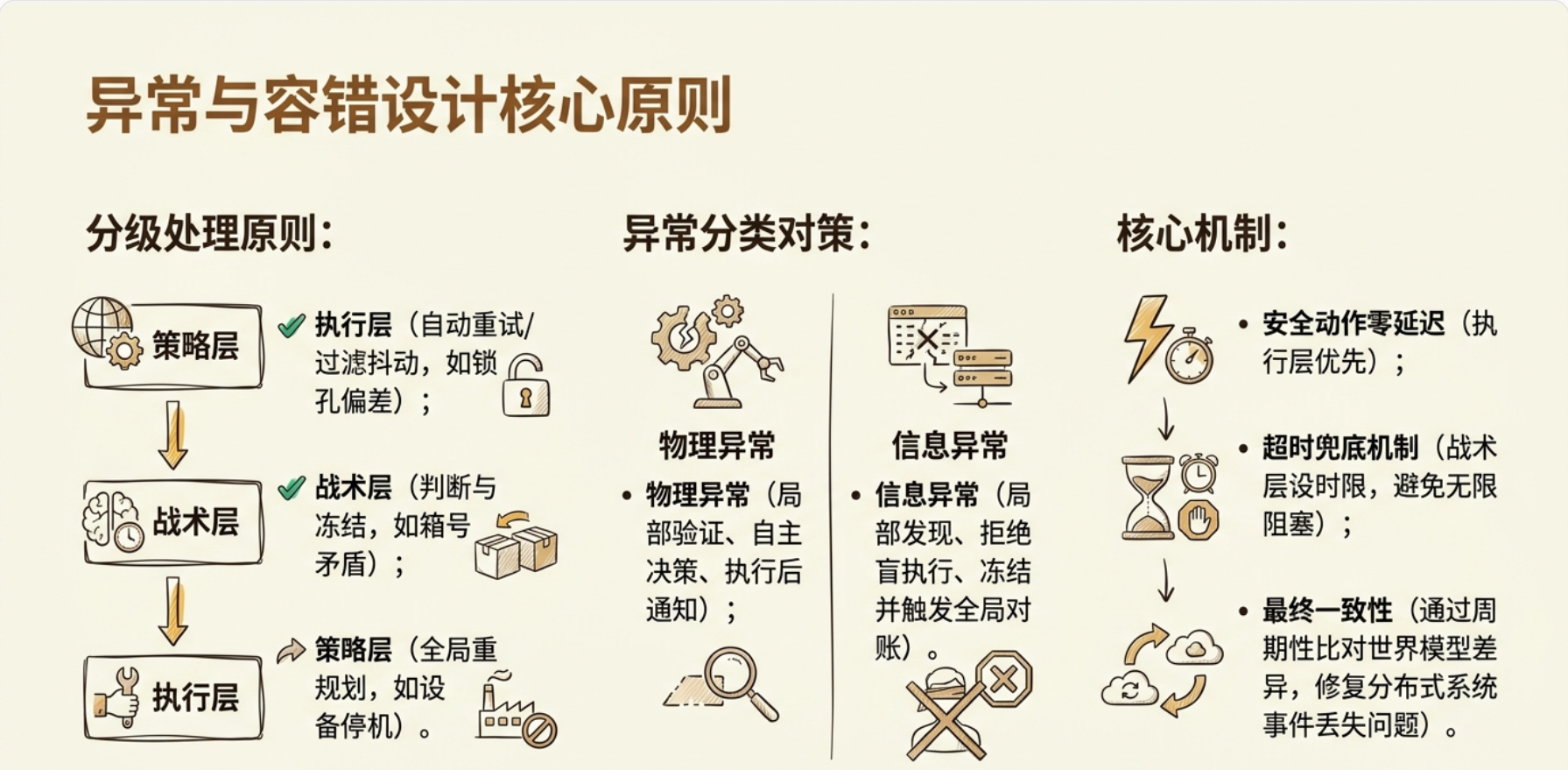
分级处理逻辑
执行层(规则驱动)
自动重试(锁孔偏差)
瞬时抖动过滤
执行层(毫秒级,纯规则): 传感器读到"偏差3mm" → 自动微调吊具位置 → 再试。这个循环不需要思考,不需要上报,不需要记录。执行层只管"偏差→纠正→重试"这个原子动作链。三次内成功,就当什么都没发生。
战术层(判断驱动)
冻结与止血(信息矛盾)
局部诊断
战术层(秒级,需要判断): 执行层三次重试都失败了,把"锁孔对准失败@箱号47"这个事件抛给战术层。战术层做判断:
是不是这个锁孔本身有物理损伤?→ 需要换一个锁孔角度,或者跳过该箱,先卸下一箱
是不是吊具的激光校准需要重新标定?→ 触发校准流程
战术层决策完后,把结论告诉执行层,同时以语义事件的方式通知调度:"第47箱跳过,原因:锁孔三次对准失败,等待维修确认"。
策略层(规划驱动)
全局资源重规划
跨Agent协同
策略层(分钟级,全局调度): 收到"第47箱被跳过"后,策略层更新全局计划——这箱什么时候补?由谁补?会不会影响后续的舱盖开关时序?策略层不关心"为什么没对准",只关心"这箱没卸成,整体计划怎么调整"。
通过一个例子:桥吊 A 在卸第 47 箱时,吊具传感器返回了一个"锁孔未对准"信号——这不是机械故障,而是需要微调重试的临时偏差。这件事应该由桥吊 Agent 自己在执行层重试三次后静默解决,还是一发生就立刻上报给调度?
这个场景的完整处理链是:执行层静默重试 → 失败后战术层诊断决策 → 策略层调整全局计划。
异常应该由谁负责发现、谁负责决策、谁负责上报?有两个关键事实你必须抓住:
信息在哪? 堆场 Agent 的眼睛就盯着自己的箱区,它看到的实际物理状态是最真的。谁有这个信息?堆场自己。
矛盾代表什么? 调度的"已清空"和堆场的"没清空"打架了——这不一定是"谁错了",更可能是状态同步滞后。上一秒有人把这个箱放上去了,事件还没传到调度。
所以:
发现者:堆场 Agent 自己——它的世界模型在翻箱前置校验时发现了矛盾。
决策者:堆场 Agent 的战术层——当下这个翻箱动作不能执行,因为压箱没移走。战术层需要决定:暂停翻箱、标记"待确认",同时把矛盾上报。
上报者:堆场 Agent ——通过 Pub/Sub 向调度发一个
world-model-conflict语义事件,附上实际的列快照。
调度的职责是收到矛盾后做对账——查自己手里的状态更新记录,看是哪个环节的更新事件丢了。
核心原则:谁掌握真相谁喊停,谁发现问题谁上报,局部决策局部做,全局影响全局报。
那接下一个场景:桥吊 B 突然收到吊具电机过热告警,按安全规则必须停机冷却 15 分钟。但它身上还背着 80 个待卸箱。 停机之后,这 80 箱怎么办?谁来决定?
桥吊 B 吊具过热停机——三个 Agent 各干什么:
桥吊 B 自己(执行层 + 战术层):
安全规则一触发,执行层直接断电——这不需要任何人批准。战术层同时做两件事:
估算冷却时间,发一个语义事件:
{"event":"downtime","agent":"QC-B","reason":"overheat","est_duration":"15min","affected_tasks":["bay-3-remaining-80"]}把当前进度(卸到第几箱、哪些箱位已空)快照存入记忆,供恢复时使用
调度(策略层):
收到 QC-B 停机事件后,策略层做全局重规划:
QC-B 覆盖的 Bay 3 剩余 80 箱,有没有空闲的桥吊可以过来接?如果 QC-A 作业进度领先且无硬冲突 → 调度让 QC-A 完成自己任务后移机到 Bay 3 接替
如果所有桥吊都满载 → 80 箱进入等待队列,启动冷备预案(但这个场景一般不这么做)
不管哪种方案,调度要向所有订阅方发一个计划变更事件
堆场、道口(下游受影响的 Agent):
QC-B 停机意味着上游放慢,堆场的翻箱节奏可以放松,道口的集卡调度要重新算到达时间。它们各自治域内的调整,不需要调度一条条指挥。
核心原则:安全事件零延迟响应(执行层直接断电,不上报等批准),停机后语义事件触发全局重规划(调度),下游 Agent 根据计划变更自主调整(自治)。
现在我们换一个更有意思的异常——不是设备故障,而是"信息层的错误":
堆场 Agent 在翻箱时发现,调度 10 分钟前发来的指令里标记的箱号是 A12-03-2,但它实际扫描到那个箱位的 RFID 读数是 B07-11-5——箱号对不上。这可能是搬运工放错了箱,也可能是 RFID 标签被换过。
异常类型分类
原则一——分级处理
层级 | 职责 | 示例 |
|---|---|---|
执行层 | 可自动恢复的偏差,静默处理 | 锁孔偏差重试、传感器瞬时抖动过滤 |
战术层 | 需要判断但不能自作主张的,冻结+上报 | 箱号矛盾、指令与状态冲突 |
策略层 | 全局资源重规划 | 桥吊停机、泊位延误、天气封港 |
原则二——物理异常 vs 信息异常,两套处理链
物理异常:局部可验证 → 局部可决策 → 执行后通知。省去不必要的上报。
信息异常:局部可发现 → 但不能决策 → 冻结 → 要求上游对账。绝不盲猜执行。
原则三——安全动作零延迟
任何涉及人身安全、设备安全的规则触发(过热停机、防撞雷达告警),执行层直接动作,不需要等任何 Agent 或人的批准。先停机,再发事件。
原则四——超时兜底
如果堆场 Agent 发了一个矛盾事件给调度,10 秒没收到回执——不能无限等。战术层要设超时,超时后执行降级策略:冻结该任务,打上人工介入标记,继续做下一个不依赖该箱位的任务。
原则五——最终一致性对账
不管前面处理得多好,分布式系统一定有丢失事件的情况。所以每个 Agent 每隔一定周期(比如 5 分钟)对自己的世界模型做一次完整性校验,和调度的全局状态做差分比对。差出来的结果就是兜底的最后一道防线。
核心设计原则
安全动作零延迟
超时兜底策略
心跳超时设定
响应等待超时
最终一致性对账
周期性校验
差分比对修正
五条核心设计原则
①分级处理——执行层静默重试、战术层冻结判断、策略层全局重规划。
②物理异常vs信息异常分离——物理可局部决策(重试/跳箱),信息必须冻结+全局对账。
③安全动作零延迟——过热/防撞等安全规则触发直接断电,不上报等批准。
④超时兜底——心跳超时+回执超时两级,超时后降级+人工标记。
⑤最终一致性对账——周期性世界模型完整性校验,兜住所有分布式丢事件的边角。
码头智能体架构与技术选型
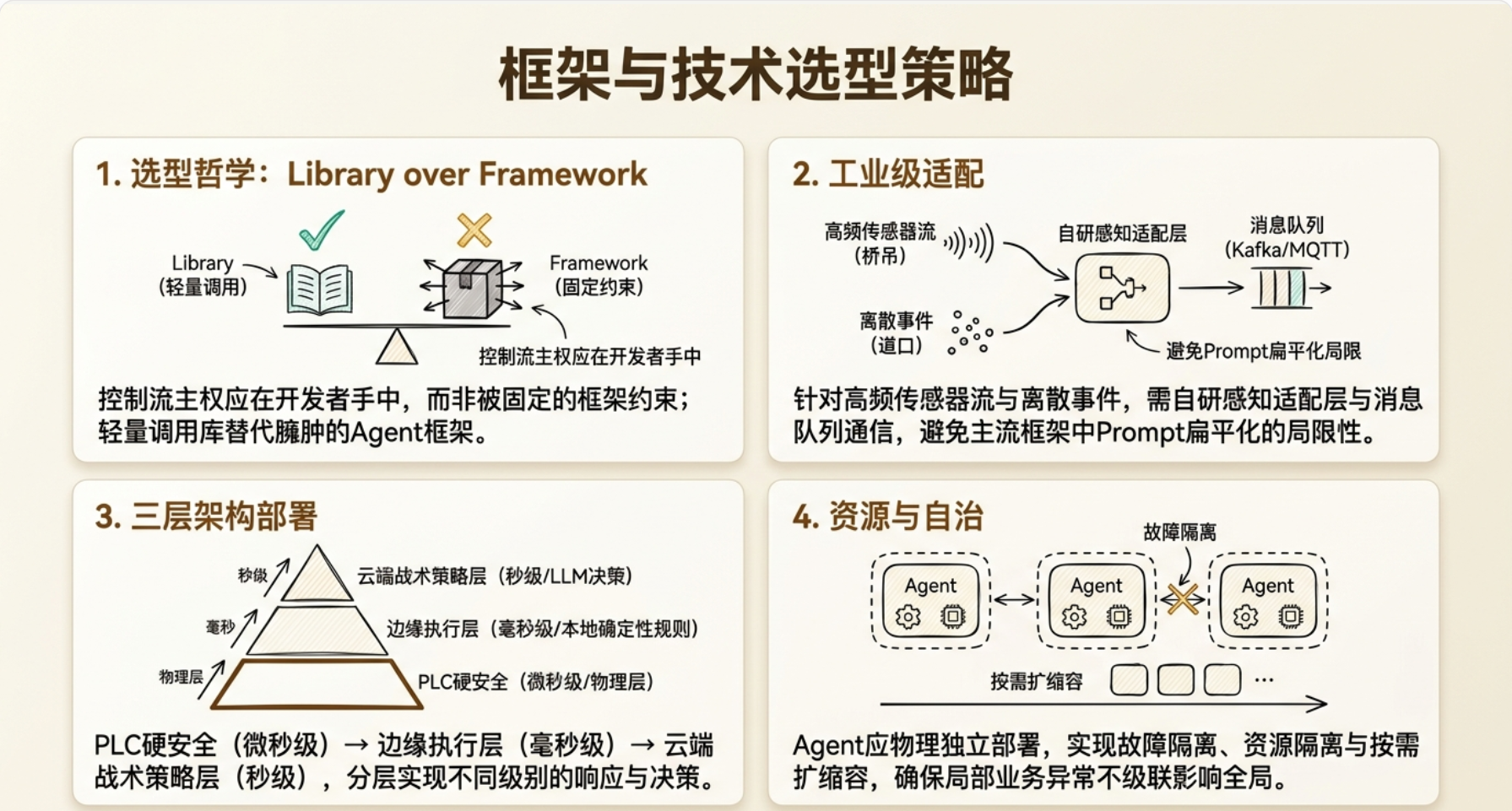
选型策略
三个 Agent——桥吊、堆场、道口——在同一个"感知→思考→行动→记忆"循环下,内部差异其实很大:
桥吊的感知是高频连续传感器流(毫米级吊具位置),道口的感知是离散事件(RFID 触发、道闸状态)。
桥吊的决策是三层级联(策略选船序→战术选箱→执行控吊具),堆场的决策战术层极重(翻箱策略、箱位优化),道口几乎只有执行层+战术层的快速校验。
桥吊的行动有物理动作(吊具升降)和信息动作(状态上报),道口全是信息动作(校验结果、放行/拦截指令)。
现在问题来了:如果框架给你一个固定的 Agent 循环(比如 LangChain 的 AgentExecutor 那种"tool-calling loop"),你觉得它最可能在哪个部件上卡住你的设计?是感知、思考、行动,还是记忆?
框架解决的是"通用问题",你的港口 Agent 是"专用问题"。
主流 Agent 框架(LangChain、AutoGen、CrewAI)的核心假设是:Agent 的输入输出都是文本,感知就是拼 prompt,记忆就是对话窗口,行动就是调 tool。这个假设放在 Chatbot、客服、代码助手这些场景没问题,但放到你的桥吊 Agent 上会直接散架:
感知层不匹配。 桥吊每秒几十帧激光雷达数据,道口是 RFID 离散事件触发——框架根本没有高频传感器流的消费接口,也没有事件驱动的触发机制。你自己写一个感知适配层(比如 ROS2 节点 + 事件总线),比往框架里硬塞要干净得多。
决策层不是纯 LLM 可承载的。 你前面的三层决策模型里,执行层必须用规则(硬实时、毫秒级),战术层用 LLM(复杂判断),策略层是求解器(运筹优化)。框架默认"Agent = LLM 决策",你的架构里 LLM 只是战术层的一部分——硬塞进去整个框架就会变成瓶颈。
记忆不是扁平窗口。 工作记忆(毫秒级传感器缓存)需要 Redis/共享内存,短时记忆(作业上下文)需要结构化存储带 TTL,长期记忆(历史模式)需要向量库。框架给你的就是一个消息列表——你设计了三种生命周期,框架只给你一种。
通信不是"Agent 之间的对话"。 你前面设计的 Pub/Sub 是基于业务主题的路由("箱位已空"、"加急车进场"),走的是消息队列(Kafka/MQTT),不是框架的 Agent 间对话。AutoGen 的 GroupChat 模式在这种工业级消息语义面前是玩具。
那框架有没有用?有用,但位置不是你想象的那样。
框架的价值不在"承载整个 Agent 循环",而在 LLM 调用的工程化——prompt 管理、tool 定义、流式输出、重试策略、token 计费。这些你自己写很繁琐,但也不值得为它们接受框架的全套约束。
你的合理选型是:轻量 LLM 调用层用库(不是框架),Agent 循环自己写。
具体来说:
LLM 调用:用 OpenAI/Anthropic SDK 直接调,或者用一个极薄的封装(比如 LiteLLM 做统一接口),不要用 LangChain 的 AgentExecutor
Agent 循环:自己实现感知→思考→行动→记忆的主循环,桥吊/堆场/道口三个 Agent 共享同样的循环结构但内部策略不同(你前面说的"架构同构、策略异构")
通信:走消息队列(Kafka/MQTT),不用框架内置的通信机制
记忆:工作记忆 Redis,短时记忆 PostgreSQL + TTL,长期记忆 pgvector
这就是所谓的 "库优于框架"(Library over Framework)——你的代码调用库,而不是框架调用你的代码。控制流的主权在你手上。
那我问你一个落地的判断:你前面设计的异常处理原则里有一条"安全动作零延迟"——桥吊执行层检测到防撞信号必须毫秒级断电。如果战术层的 LLM 决策在云上跑,这段安全逻辑应该部署在哪里?LLM 能参与吗?
安全逻辑绝对不能经过 LLM。 部署在桥吊本地的 PLC 或边缘工控机上,硬编码规则,独立于 Agent 的 LLM 战术层运行。
实战做法分三层:
第一层:PLC 硬安全(微秒级) 防撞、超限、急停——写在 PLC 固件里,不走任何操作系统,更不走网络。检测到激光雷达防撞信号 → 直接断电,物理回路,连 Agent 的执行层都绕过去了。这是真正的"零延迟"。
第二层:边缘执行层(毫秒级) 跑在桥吊旁边的边缘服务器上(不是云端),用确定性规则引擎。比如"吊具未对准锁孔 → 微调三次 → 三次失败则暂停并上报战术层"。这层有毫秒级延迟,但足够快。关键:这层部署在本地,不依赖云网络。
第三层:云端战术/策略层(秒级到分钟级) LLM 决策跑在云端,处理的是"选哪个箱"、"翻箱策略"、"重规划"这种不差一两秒的任务。它的输出是指令,不是控制信号——指令到了边缘层还要经过安全校验才执行。
所以布署架构是 PLC → 边缘服务器 → 云端 三层物理分离。桥吊防撞这条链路:激光雷达 → PLC 直接断电(微秒)→ 同时通知边缘执行层"已急停"→ 边缘通知云端战术层"异常,需重规划"。安全动作和上报是并行的,不等批准。
部署与安全架构
最后一个落地的选型判断:既然 Agent 循环自己写、通信走消息队列、安全逻辑本地部署——那你觉得这三个 Agent(桥吊、堆场、道口)应该跑在同一个进程里,还是各自独立部署?为什么?
各自独立部署。理由三条:
1. 故障隔离。 桥吊的 Agent 进程挂了,堆场和道口必须继续跑。如果塞在同一个进程里,一个 Agent 的 bug(比如桥吊处理激光雷达数据时 OOM)会拖死全部三个。港口作业不能接受这种耦合。
2. 部署位置不同。 桥吊 Agent 的边缘执行层跑在桥吊旁边的工控机上,道口 Agent 跑在道口闸机的边缘节点上,堆场 Agent 战术层也许在机房或云端。物理上就分开了。
3. 资源需求不同。 桥吊要处理高频传感器流,需要 GPU 做点云推理(或者至少高吞吐的 CPU 绑定);道口基本是事件驱动的轻量逻辑。放在一起,资源分配和扩缩容都绑死了。
所以你的部署拓扑是三个独立服务,通过消息队列(Kafka/MQTT)通信,各自有自己的感知适配层、决策引擎和记忆存储。这正是你前面 Pub/Sub 设计在物理层的映射——通信解耦,部署也解耦。
框架选型核心原则
库优于框架
你的代码调用库(如 OpenAI SDK),而不是框架调用你的代码。控制流主权在你手上,框架只帮你做 LLM 调用的工程化(重试、流式、计费)。
Agent 循环自研
感知→思考→行动→记忆的主循环自己写,三个 Agent 共享循环结构但内部策略不同(架构同构、策略异构)。框架的固定循环无法承载你差异化的感知模式和三层决策。
通信走消息队列
不用框架内置的 Agent 对话机制。选 Kafka/MQTT,基于业务主题路由,和你前面设计的 Pub/Sub 模式直接对接。
记忆分级存储
工作记忆 Redis(毫秒级),短时记忆 PostgreSQL + TTL(分钟/小时级),长期记忆 pgvector(天级)。不用框架的扁平对话窗口。
安全逻辑本地闭环
PLC 硬安全(微秒)→边缘规则引擎(毫秒)→云端 LLM 战术层(秒级)三层物理分离。LLM 从不直接发控制信号。
独立部署
三个 Agent 各自独立进程/服务,故障隔离,按物理位置部署,按资源需求扩缩。
核心原则:库优于框架
六条选型原则
①库优于框架——你的代码调用库,不是框架调用你的代码。
②Agent 循环自研——感知→思考→行动→记忆的主循环自己写,三个 Agent 架构同构策略异构。
③通信走消息队列——Kafka/MQTT 按业务主题路由,不用框架内置通信。
④记忆分级存储——Redis + PostgreSQL TTL + pgvector,不用扁平对话窗口。
⑤安全逻辑本地闭环——PLC→边缘→云端三层物理分离,LLM 从不发控制信号。
⑥独立部署——三个 Agent 各自独立服务,故障隔离,按物理位置部署。
整体架构
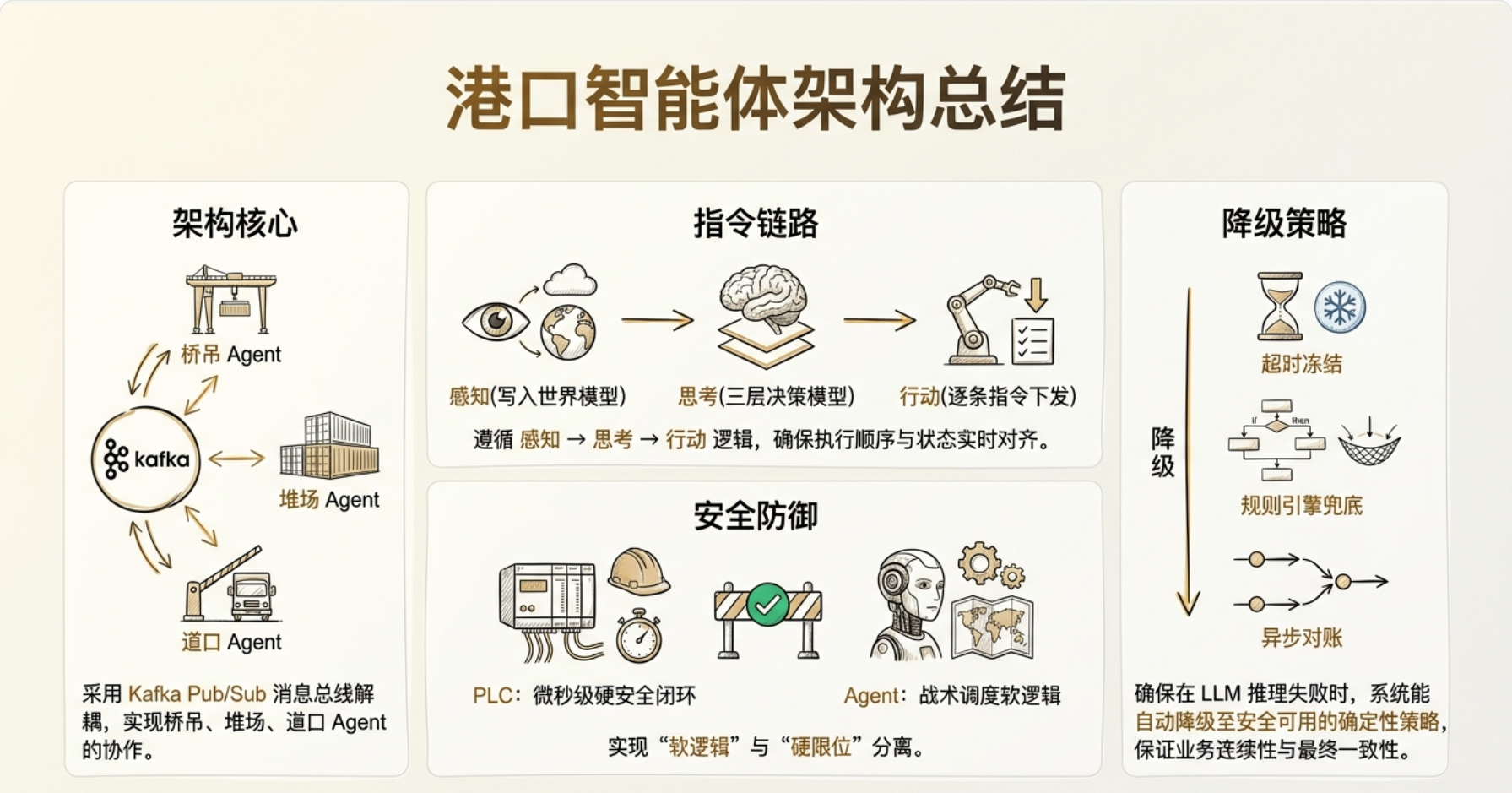
整体架构图:
现在我问你一个综合性的问题:如果中控 TOS 给桥吊 Agent 发了一个"加急箱优先卸船"的指令,从消息总线收到指令到桥吊吊具开始动作,这条链路经过哪些组件?每个组件做什么判断?
完整链路——从 TOS 指令到桥吊吊具动作:
TOS 下发"加急箱优先卸船"指令 → 桥吊开始动作,经过 6 步:
步骤 | 组件 | 做什么 |
|---|---|---|
1 | 消息总线 (Kafka) | Topic |
2 | 桥吊 Agent · 感知部件 | 读到指令,写入世界模型(事件: |
3 | 桥吊 Agent · 思考部件(战术层) | 读世界模型 → 当前正在执行的顺序表 vs 加急箱位置 → 判断:插队是否安全?(吊具空载?相邻 Bay 无冲突?)→ 输出新抓取序列 |
4 | 桥吊 Agent · 思考部件(执行层) | 将序列转为原子指令: |
5 | 桥吊 Agent · 行动部件 | 逐条发指令给 PLC,每步等 PLC 回执(ACK + 传感器状态),异常立即中断 |
6 | 桥吊 PLC | 执行电机动作,速度控制、防撞硬限位(不经过 Agent,微秒级切断) |
关键设计点(对应前七个节点):
步骤 3 战术层用了三层决策模型:TOS 给策略(加急),战术层做计划展开(具体插哪),执行层只管原子动作。
步骤 5-6 的安全闭环:Agent 下行到 PLC 是纯执行,PLC 的防撞逻辑不过 Agent。
步骤 2 的世界模型:指令进来先写世界模型,不是直接发动作——保持感知→思考→行动的循环不短路。
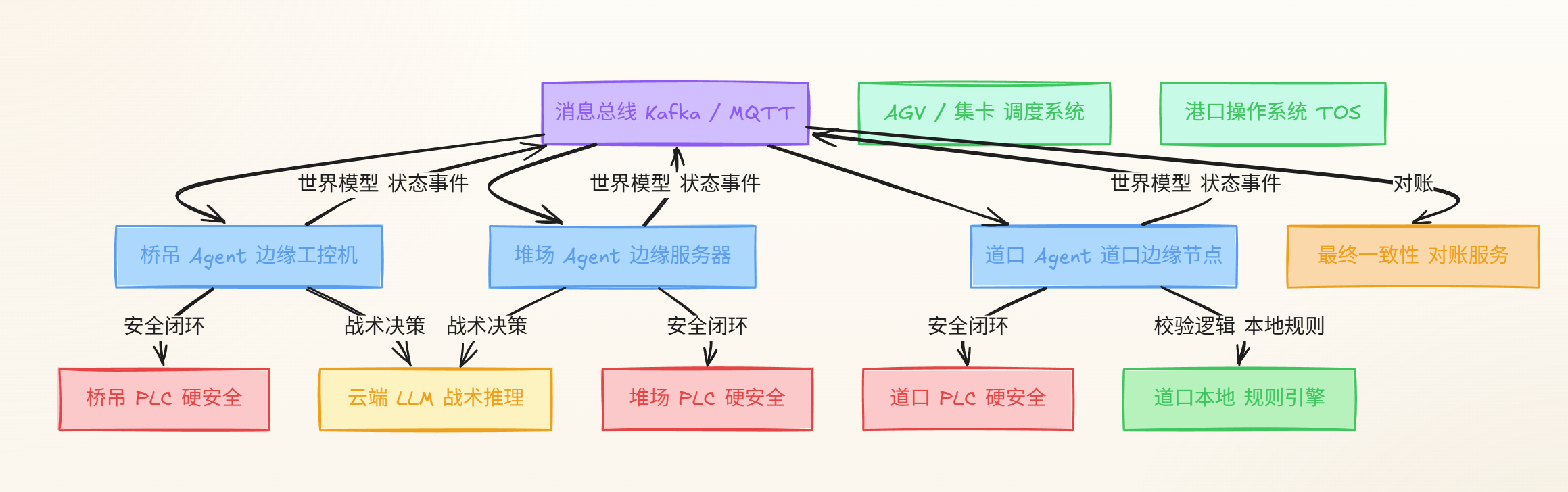
港口多智能体系统 · 架构全景
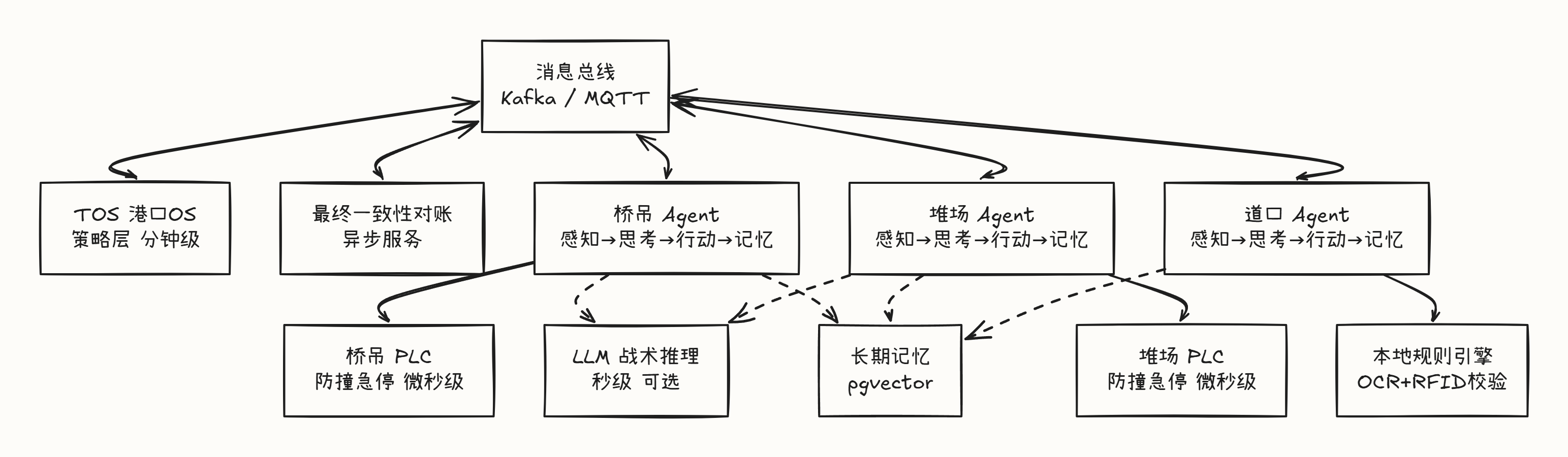
二、单个 Agent 内部结构
三、决策三层模型
决策层次
层级 | 时间 | 范围 | 引擎 | 示例 |
|---|---|---|---|---|
策略层 | 分钟级 | 整船/全场 | TOS + 优化算法 | 整船卸箱顺序、泊位分配 |
战术层 | 秒级 | 单箱/Bay | 规则引擎 + LLM | 加急箱插队判断、翻箱选位 |
执行层 | 毫秒级 | 原子动作 | 纯规则/硬编码 | 吊具锁孔、小车移动、道闸抬杆 |
四、三大 Agent 差异对照
Agent 差异化设计
维度 | 桥吊 | 堆场 | 道口 |
|---|---|---|---|
感知 | 连续高频(激光雷达、编码器) | 事件驱动(箱位移入/移出) | 确定性(OCR、RFID、地磅) |
决策复杂度 | 中——位置约束强、序列优化 | 高——翻箱预测、空间最大化 | 低——匹配校验、通行判定 |
LLM 依赖 | 可选(序列优化时) | 有价值(翻箱策略、空间推理) | 几乎不需要(规则够用) |
行动空间 | 吊具六自由度 + 锁孔 + 防撞 | 堆高机/龙门吊定位 + 翻箱 | 道闸、LED、语音对讲 |
安全关键度 | 极高——悬吊 30 吨 | 高——堆垛倒塌风险 | 中——集卡碰撞风险 |
记忆需求 | 工作记忆为主(当前作业序列) | 短时+长期(箱位历史、翻箱规律) | 最小(当前通行记录) |
五、通信架构
Pub/Sub 主题设计
Topic | 发布方 | 订阅方 | QoS |
|---|---|---|---|
qc/status/bay-progress | 桥吊 | 堆场、TOS、对账 | 至少一次 + 幂等 |
yard/event/position-freed | 堆场 | 调度、TOS、对账 | 至少一次 + 幂等 |
gate/event/truck-in | 道口 | 调度、堆场 | 至少一次 + 幂等 |
tos/cmd/priority | TOS | 桥吊 | 精确一次 |
equipment/alarm | 各 Agent | 维修调度、TOS | 至少一次 |
heartbeat/* | 各 Agent | 对账服务 | 尽力而为 |
六、异常与容错五原则
分级处理
执行层异常(锁孔偏差)毫秒级重试;战术层异常(箱号冲突)秒级冻结+校验;策略层异常(设备停机)分钟级全局重规划。
物理/信息异常分离
传感器断连(物理)→ 安全停机,不猜;箱号不匹配(信息)→ 冻结+人工/规则仲裁,不能当物理故障处理。
安全动作零延迟
防撞、急停、超限——PLC 硬线逻辑,不经过 Agent 软件栈,不经过 LLM,微秒级切断。
超时兜底
LLM 超时 → 冻结局部 → 规则引擎降级(Earliest Accessible First)→ 事后对账。不盲动。
最终一致性对账
心跳超时 + 回执超时两级兜底;定时比对 Agent 世界模型 vs TOS 状态,偏差告警不自动回滚。
七、技术选型六条原则
库优于框架——你的代码调用 LiteLLM/OpenAI SDK,不用 Agent 框架控制你的循环
Agent 循环自研——感知→思考→行动→记忆主循环自己写,三个 Agent 架构同构、策略异构
通信走消息队列——Kafka/MQTT 按业务 Topic 路由,不用框架内置的 GroupChat 或内存通信
记忆分级存储——Redis(工作记忆,秒级TTL)+ PostgreSQL(短时,分钟/小时TTL)+ pgvector(长期,天级语义检索)
安全逻辑本地闭环——PLC→边缘→云端三层物理分离,LLM 只参与战术推理,从不发控制信号
独立部署——三个 Agent 各自独立服务/进程,故障隔离,按物理位置部署到工控机/边缘服务器
八、指令执行完整链路
1
消息总线接收
Kafka Topic 送达,带幂等 ID 防重投
2
感知部件写入世界模型
事件入库:PRIORITY_UNLOAD / containerId / bay / timestamp
3
战术层计划展开
读世界模型 → 当前序列 vs 加急箱位置 → 判断插队安全性 → 输出新抓取序列(规则+可选LLM)
4
执行层原子化
序列拆为 MOVE_TO → LOWER_SPREADER → LOCK_TWISTLOCKS → HOIST
5
行动部件逐条下发
每步等 PLC ACK + 传感器回执,异常立即中断
6
PLC 执行 + 安全硬限位
电机动作,防撞硬线逻辑微秒级独立于 Agent
7
感知部件回写结果
动作完成事件 → 更新世界模型 → 广播状态事件到消息总线
一句话总结
三个独立 Agent 通过消息总线松耦合通信,每个 Agent 内部分感知→思考→行动→记忆四部件闭环。决策分层(策略/战术/执行),LLM 只在战术层做推理不碰控制,安全逻辑硬线微秒级。异常分级处理、超时冻结降级、最终一致性兜底。
八个节点学习总结
节点 | 核心收获 |
|---|---|
智能体的解剖结构 | 掌握了感知→思考→行动→记忆四部件模型,能区分物理层动作与信息层动作,理解了三种记忆生命周期 |
单智能体的决策模型 | 掌握了策略/战术/执行三层决策架构,能准确判断规则 vs LLM 的适用边界,理解了执行层为什么只用规则 |
状态管理与世界模型 | 掌握了自我vs外部、实时vs语义、自治边界三条核心原则,能追踪完整的事件→感知→思考→行动→记忆链路 |
多智能体通信模式 | 理解了三种通信模式的演进逻辑和适用场景,能按业务职责设计 Topic 路由,掌握了可靠投递的必要性 |
任务分解与分配 | 掌握了按信息拥有权决定拆细/委托分界的原则,能区分细拆指令、高维目标、带约束委托三种粒度 |
异常与容错设计 | 掌握了五大设计原则:分级处理、物理/信息分离、安全动作零延迟、超时兜底、最终一致性对账 |
框架与技术选型 | 掌握了六条选型原则:库优于框架、循环自研、消息队列通信、记忆分级、安全闭环、独立部署 |
整体架构与集成方案 | 完整掌握了从部署拓扑到指令执行全链路,能将前七个节点的所有设计决策串联成统一架构方案 |
这套架构可以直接作为方案基础的五个理由
①每个设计决策都有明确的原则做支撑,不是拍脑袋。
②三个 Agent 的差异化设计表可以直接用作需求文档的骨架。
③通信 Topic 设计覆盖了正常作业、异常告警、心跳对账三条线。
④异常处理五原则覆盖了从毫秒到分钟、从物理到信息的全频谱。
⑤技术选型给出了明确的组件替代关系——Kafka、Redis、PostgreSQL、pgvector、LiteLLM 都是可替换的成熟方案。
