
我们已经搭了一个完整的 RAG 管线——加载、分块、Embedding、存储、检索、注入。管线跑通了,但你可能很快会发现一个问题:
Agent 确实在"查资料"了,但查回来的东西经常不对。
你问"怎么部署这个服务",它检索回来一篇"服务架构概览图"——语义上确实相关(都跟"部署"和"服务"有关),但你想要的是部署命令、配置文件、环境变量这些操作性的内容,不是一张架构图。
你问"上次上线出了什么问题",它返回"上线流程规范"——这两个在向量空间里确实靠得很近,但一个是问题、一个是规范,完全不是一回事。
这个问题很经典:语义相似不等于任务相关(Semantic Similarity ≠ Task Relevance)。
纯向量搜索的结构性局限
为什么纯向量搜索会“搜到但不对”?先搞清楚这个原因才方便后续理解。看清本质:Embedding 模型做的事情是把文本映射到一个高维空间。在这个空间里,语义相近的文本距离近。但"语义相近"和"对用户有用"是两码事。
举几个典型的失败场景:
意图模糊:用户问"Python 错误处理",向量搜索可能返回一篇介绍 Python 异常机制的博客,也可能返回一段 try-except 的代码示例。两个在语义上都跟"Python 错误处理"相关,但用户可能只想要代码示例。
技术术语的歧义:embedding 模型对一些领域术语的理解不如人类。比如"migration"在数据库语境下是"迁移脚本",但 embedding 可能也把"数据迁移服务"、"云实例迁移方案"拉得很近。
这些问题不是调调参数就能解决的。它们源于 Bi-encoder(双编码器)的架构限制——查询和文档各自独立算向量,没法捕捉两者之间的细微交互。
所以生产级 RAG 系统不会只用向量搜索。接下来我们看几个行之有效的优化手段。
混合检索:向量 + 关键词的组合拳
目前最被广泛采用的检索优化手段就是这套组合拳。思路很直接:向量搜索擅长理解语义,关键词搜索擅长精确匹配——两个各有所长,组合起来效果最好。
为什么关键词搜索不能扔掉?
你可能觉得都 2026 年了,还用关键词搜索?太老土了吧。但想想这个场景:用户搜 ECONNREFUSED。这是一个精确的错误码。向量搜索可能把它理解成"连接被拒绝"的语义,返回一堆跟网络错误相关的文档。但用户就是要找包含这个具体错误码的那几段文字。
关键词搜索(BM25)在这种场景下碾压向量搜索——它不管语义,就是找"这个词出现在哪"。
反过来,用户搜"怎么让服务更稳定",关键词搜索就懵了,"更稳定"这个词出现的地方太少了,但向量搜索能理解这些语义上的关联。
所以最佳实践是两个都用。
OpenClaw的实现
两条检索路径并行:
向量路径:sqlite-vec 做余弦距离搜索
关键词路径:FTS5(SQLite 内置全文搜索引擎)做 BM25 排序
最后按权重合并:final_score = 0.7 × 向量分 + 0.3 × 关键词分。
但这里有一个细节很多人忽略了——两条路径返回的分数根本不是一个体系的。 打个比方,向量搜索给你的分数是"厘米",BM25 给你的分数是"斤"——一个量长度,一个量重量,你没法直接把 3 厘米和 2 斤加起来说"总分 5"。
具体来说:向量搜索返回的是余弦距离,值在 0 到 2 之间,越小越相关;BM25 返回的是一个负数排名值,越负代表匹配度越高。一个是小数、一个是负数,数值范围完全不同。如果你直接把 0.3(向量分)和 -15.7(BM25 分)加起来,结果毫无意义。
OpenClaw 的处理方式是把 BM25 分数做 sigmoid 归一化:
PLAINTEXT
如果 rank < 0: score = -rank / (1 - rank) → 映射到 [0, 1)
如果 rank ≥ 0: score = 1 / (1 + rank) → 映射到 (0, 1]
这样两边的分数都在 0-1 的范围内了,加权合并才有意义。
这个容易被忽略的归一化步骤,实际上是混合检索能不能 work 的关键。很多教程里讲的是"把向量分和 BM25 分加起来",但不讲归一化——照着做出来效果一定很差。
为什么是 70/30?
为什么向量占 70%、关键词占 30%,而不是 50/50?
这是因为在大部分文档检索场景下,语义理解比精确匹配更重要。用户的查询通常是自然语言("怎么做 XXX"),而不是精确关键词。但关键词那 30% 也不能丢,因为它在处理专有名词、错误码、API 名称这类精确匹配场景时不可替代。
候选采样:先多捞,再精选
还有一个很实际的工程决策:你最终只需要 6 条结果,要不要直接就检索 6 条?
OpenClaw 的做法是先多捞 4 倍——需要 6 条,就先检索 24 条(上限 200)。
这是因为向量搜索的 top-6 和关键词搜索的 top-6 可能差异很大。如果各自只取 6 条就合并,很容易丢掉某条路径上排名靠后但合并后应该入选的结果。多取一些候选,在更大的池子里做精选,效果好很多。
这个 4 倍是在实际使用中不断迭代、验证出来的一个平衡点,你可以直接拿去用,也可以进行微调。
Query 改写
混合检索解决了"用什么方式搜"的问题。但还有一个更根本的问题:用户输入的 query 本身可能就不适合直接搜索。
用户问"上次部署出了什么问题"——这句话直接拿去做搜索,不管是向量还是关键词,匹配到的大概率不是你想要的。因为"出了什么问题"这个意图,在检索系统里很难直接表达。
Query 改写就是在搜索之前,先把用户的问题"翻译"成更适合检索的形式。
HyDE:假设文档 Embedding
HyDE(Hypothetical Document Embedding) 是目前最被广泛采用的 query 改写技巧。
思路很巧妙:先让模型生成一个"假回答"——不管对不对,先编一个看起来像答案的东西。然后用这个假回答去做检索。
比如用户问"上次部署出了什么问题",HyDE 会先让模型生成:
"上次部署时 Nginx 配置没有更新导致 502 错误,同时数据库连接池配置不当导致超时。"
这个假回答可能完全是瞎编的,但它在向量空间里的位置比原始问题更接近真正包含答案的文档——因为它的表达方式跟文档更像(都是陈述句,都包含具体的技术细节)。
HyDE 的原始论文发现,它能显著提升零样本检索的效果,在某些基准上甚至超过了有监督的微调模型。但要注意代价——多了一轮 LLM 调用,延迟会增加 43-60%。但客观来讲这个延迟可以通过工程的手段来进行优化,比如用更小的模型来做,因为我们对回答的正确性要求并不高,用次一些的模型也没有问题。
子问题分解
复杂问题经常包含多个子意图。"我们的用户增长趋势和竞品相比怎么样"——这个问题至少包含两个子查询:
"我们的用户增长数据"
"竞品的用户增长数据"
直接搜原始问题,向量搜索大概率找不到一篇同时包含两方面信息的文档。拆成两个子查询分别搜索,再合并结果,效果会好很多。
这些技巧的本质都是同一件事:用户问的问题和数据库里存的答案之间,表达方式可能完全不同。Query 改写就是在中间架一座桥。
Reranker:粗检索之后,再来一轮精排
到目前为止,我们优化了"搜什么"(Query 改写)和"怎么搜"(混合检索)。但搜回来的候选里,排序可能还是不对——相关的排在后面,不太相关的排在前面。
Reranker(重排序器) 做的就是对候选结果做精细排序。
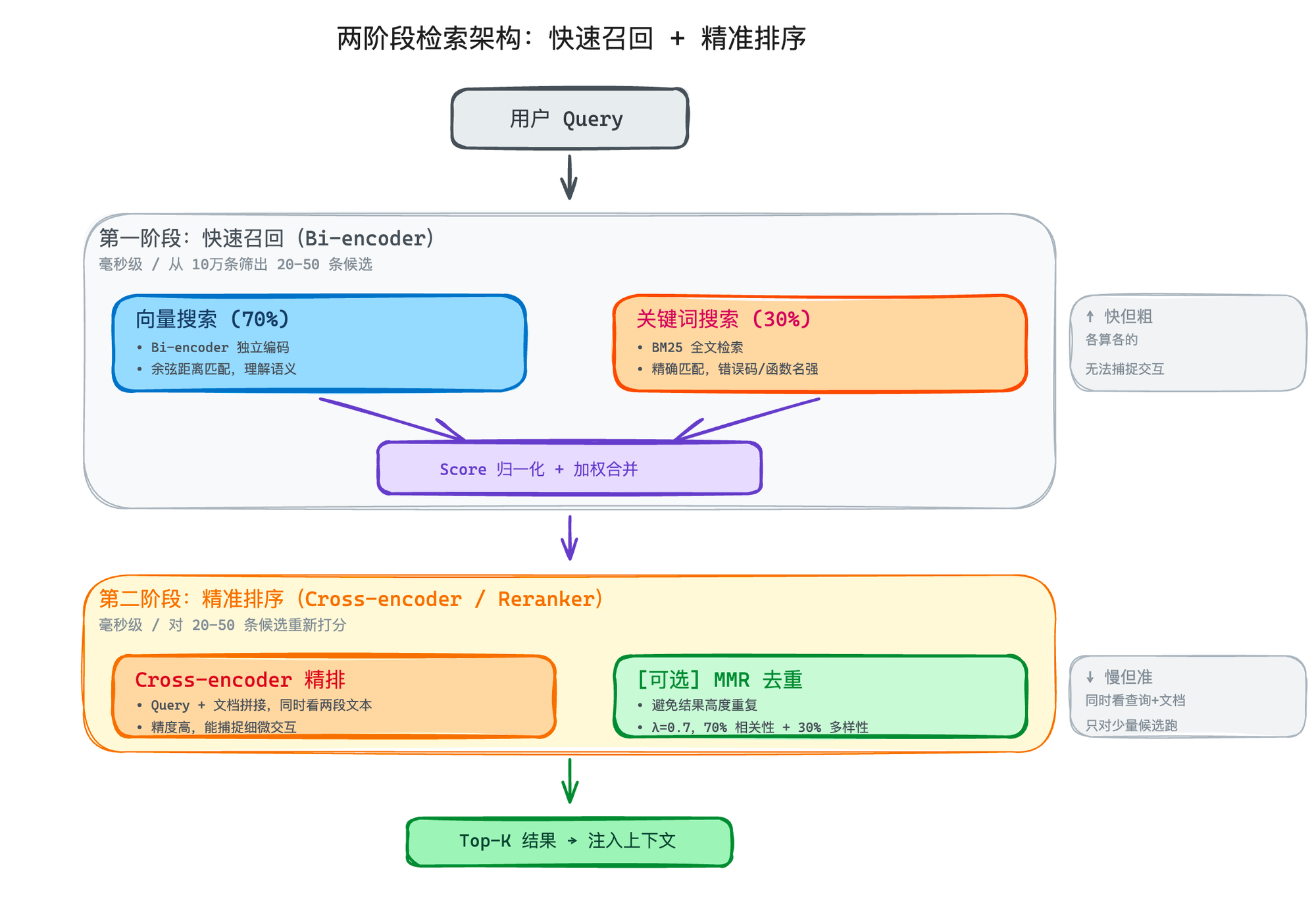
Bi-encoder vs Cross-encoder
前面用的 embedding 模型,专业术语叫 Bi-encoder(双编码器)——查询(query)和文档 chunk 各自独立过一遍模型算出一个向量,然后比距离。你可以理解成两种独立的计算方式,各算各的。好处是快——文档的向量可以提前算好,查询时只算一个新向量就行。坏处是两边各算各的,匹配的精准度会打折扣。
Reranker 用的是完全不同的一类模型,叫 Cross-encoder(交叉编码器)。注意,它跟 Bi-encoder 不是同一批模型换个用法,而是专门为"判断两段文本的相关性"训练的模型,比如 Cohere Rerank、BGE-reranker 这些。
Cross-encoder 把查询和文档拼在一起,让模型同时看到两段文本来打分。这样精度高很多——比如用户问"怎么解决 502 错误",一篇文档标题是"Nginx 配置指南",Bi-encoder 可能觉得关系不大,但 Cross-encoder 能读到文档里确实讲了 502 的排查步骤,就会给高分。
为什么不直接用 Cross-encoder?
因为太慢了。Cross-encoder 每一对(查询, 候选)都要跑一次完整的模型推理。如果你有 10 万个 chunk,跑 10 万次显然不现实。
所以业界用的是两阶段架构:
第一阶段:快速召回(Bi-encoder) ——向量搜索 + 关键词搜索,毫秒级,从 10 万条里筛出 20-50 条候选
第二阶段:精准排序(Cross-encoder / Reranker) ——对这 20-50 条候选重新打分,毫秒级(因为候选数量少了)
这个两阶段模式在后端的搜索引擎领域已经用了很多年了,在 RAG 里同样适用。
qmd 的三种搜索模式:一个鲜活的教材
讲了这么多理论,我们来看一个实际产品是怎么把这些优化串起来的。
qmd 是 Shopify CEO Tobi Lütke 做的一个本地 Markdown 搜索引擎——用 SQLite 存索引,用 GGUF 格式的本地小模型做 embedding 和 rerank,零 API 调用,完全离线可用。它提供了三种搜索模式,正好对应检索优化的三个层次:
qmd search 是最基础的——纯 BM25 关键词搜索,零 GPU 成本,4 秒就出结果。你搜 ECONNREFUSED 这种精确错误码,它比什么都快。但你要是搜"怎么让服务更稳定",它就傻眼了,文档里没出现过这几个字,它就找不到。
qmd vsearch 加了一层语义理解。它用本地 GGUF 小模型把文档都算成向量,搜的时候走语义匹配。这样"高可用"和"服务稳定"就能关联上了。代价是你得先跑一遍 qmd update 建索引,而且要经常去同步。
qmd query 是火力全开——先用 BM25 关键词搜索捞一批候选,再用本地模型做 rerank 精排。这个操作的精度是最高的。
这三种模式刚好覆盖了从"便宜但粗"到"贵但准"的完整范围——关键词搜索零成本但只认字面匹配,向量搜索懂语义但要预计算,BM25+Rerank 精度最高但最吃资源。没有"最好"的模式,只有最适合你当前场景的模式。
对大多数场景来说,默认用 BM25(快、免费),需要语义搜索时上 vsearch,对精度要求极高时再上 query。这也是 qmd 把 BM25 设为默认模式的原因——不是因为它最好,而是因为它的性价比最高。
MMR 去重
还有一个容易被忽略的问题:检索结果的多样性。
你搜"怎么配置 Nginx",混合检索搜回来 6 条结果,其中 5 条都在讲 location 指令——因为你的文档库里关于 location 的内容最多,向量距离也最近。但用户可能还需要 upstream、ssl、gzip 这些方面的信息。
MMR(Maximal Marginal Relevance,最大边际相关性) 解决的就是这个问题。
我先摆个公式,然后给大家解释一下:
PLAINTEXT
MMR_score = λ × 相关性 - (1-λ) × 与已选结果的最大相似度
OpenClaw 的实现里,λ 默认是 0.7——70% 看相关性,30% 看多样性。
算法很符合直觉:每次选下一条结果的时候,不仅看它跟查询的相关度,还要看它跟已经选了的结果有多"不一样"。如果一条结果跟已选的某条高度相似,它的 MMR 分数就会被扣分。
有一个有意思的实现细节:怎么判断两条结果"像不像"?最直觉的做法是再跑一次 embedding 算语义相似度,但那又多一轮 API 调用。OpenClaw 用了一个更土但更快的办法——把两段文本各自拆成词的集合,看两个集合有多少重叠。重叠越多说明越像。比如两条结果都包含"nginx"、"location"、"proxy_pass"这几个词,重叠率就很高,MMR 就会扣分。这种方法叫 Jaccard 相似度,零额外成本,在这个场景下完全够用。
MMR 在 OpenClaw 里是默认关闭的,需要手动开启。为什么?因为大部分场景下,混合检索 + 候选采样已经能提供足够的多样性了。只有在你发现结果高度重复的时候才需要开 MMR。
时间衰减:旧信息应该排更后面
如果你的知识库包含时间敏感的内容(比如会议记录、项目状态更新、部署日志),还有一个优化维度:时间衰减。
三个月前的部署日志和昨天的部署日志,在语义上可能一模一样,但用户大概率想看昨天的。
OpenClaw 用指数衰减来处理这个问题:
PLAINTEXT
衰减系数 = e^(-λ × 天数)
其中 λ = ln(2) / 半衰期
默认半衰期 30 天——一条 30 天前的记忆,分数乘以 0.5;60 天前的,乘以 0.25。越老越不容易被检索到。
但有一类内容是豁免的——像 MEMORY.md 这种常驻文件,不会被衰减。
时间衰减跟 MMR 一样,在 OpenClaw 里默认关闭。只有当你的知识库有明显的时间敏感性时才需要开。
总结
检索优化的本质是解决一个核心矛盾:用户的问题和文档库里的答案,表达方式可能完全不同。
围绕这个矛盾,我们有四层优化手段:
混合检索——向量搜索理解语义,关键词搜索精确匹配,70/30 加权合并。别忘了分数归一化,否则合并没有意义。
Query 改写——HyDE 用假回答做检索,子问题分解拆复杂查询。本质是在用户的问题和文档的内容之间构建一道桥梁。
Reranker 精排——Bi-encoder 快速召回,Cross-encoder 精准排序。两阶段架构,不加 Reranker 的 RAG 在生产环境里基本不及格。
多样性和时效性——MMR 避免结果高度重复,时间衰减让旧信息排后面。按需开启,别过度优化。
