
上一篇说了父子模式——派一个子 Agent 出去干活,干完把结论带回来。这个模式解决了上下文装不下的问题,但它本质上是单向的:父 Agent 发指令,子 Agent 执行,结果回传。子 Agent 之间互相不知道对方在干什么。
现在换一个场景。你要同时开发三个功能模块:用户认证、支付系统、通知服务。这三个模块有依赖关系——支付完成后要调通知服务,通知服务需要用户认证的 token。如果用父子模式,三个子 Agent 各干各的,互相不通信,最后合并的时候大概率接口对不上。
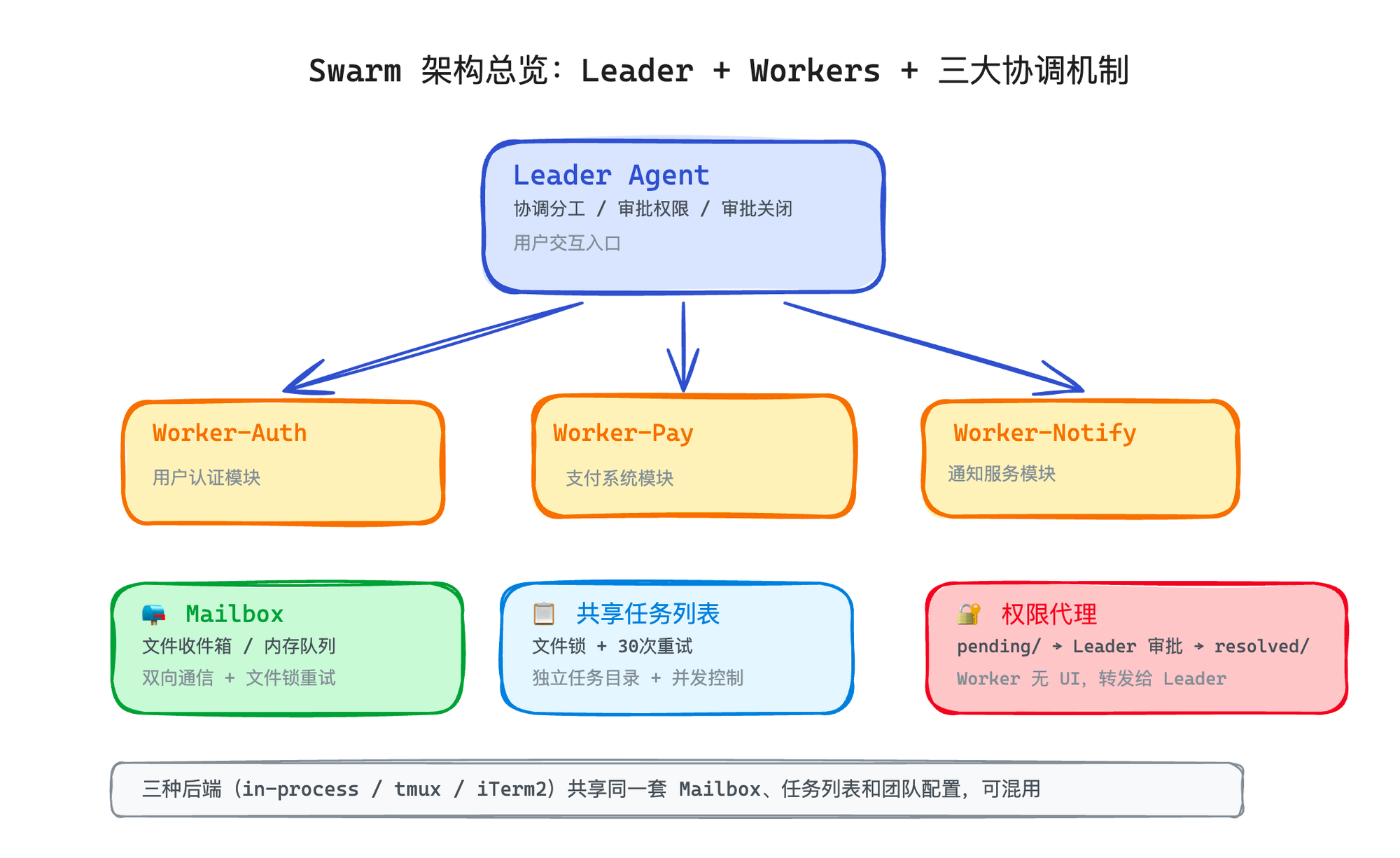
这就需要从"派出去、收回来"升级到"一起干、互相聊"。一组 Agent 组成一个团队,有一个 Leader 协调分工,成员之间可以互相发消息、共享任务列表、同步进度。
这就是 Swarm 模式。
从父子模式到团队模式
父子模式和 Swarm 模式的区别,不只是 Agent 数量的变化——架构层面多了三个难题。
第一个难题是双向通信。 父子模式是单向的——父 Agent 给任务,子 Agent 返结果。但团队协作需要 Agent 之间互相发消息。做支付模块的 Agent 需要问做认证模块的 Agent:"你的 token 格式定好了吗?" 这就需要一套消息传递机制——谁发给谁、怎么发、对方什么时候能收到。
第二个难题是共享状态。 团队需要一个共享的任务列表——谁在做什么、做完了没有、还有哪些没人认领。多个 Agent 同时读写这个列表,就涉及并发控制——两个 Agent 同时认领同一个任务怎么办?
第三个难题是权限代理。 单 Agent 的时候,遇到需要用户确认的操作(比如删除文件),直接弹窗问用户就行。但 Swarm 里的 Worker Agent 可能跑在一个后台进程里,没有 UI。它遇到权限问题,得把请求转发给 Leader,Leader 再问用户,用户批准后再把结果传回 Worker。这个来回的链路一旦出问题,Agent 就卡死了。
这三个难题就是 Swarm 模式的工程核心。
Mailbox:基于文件的消息系统
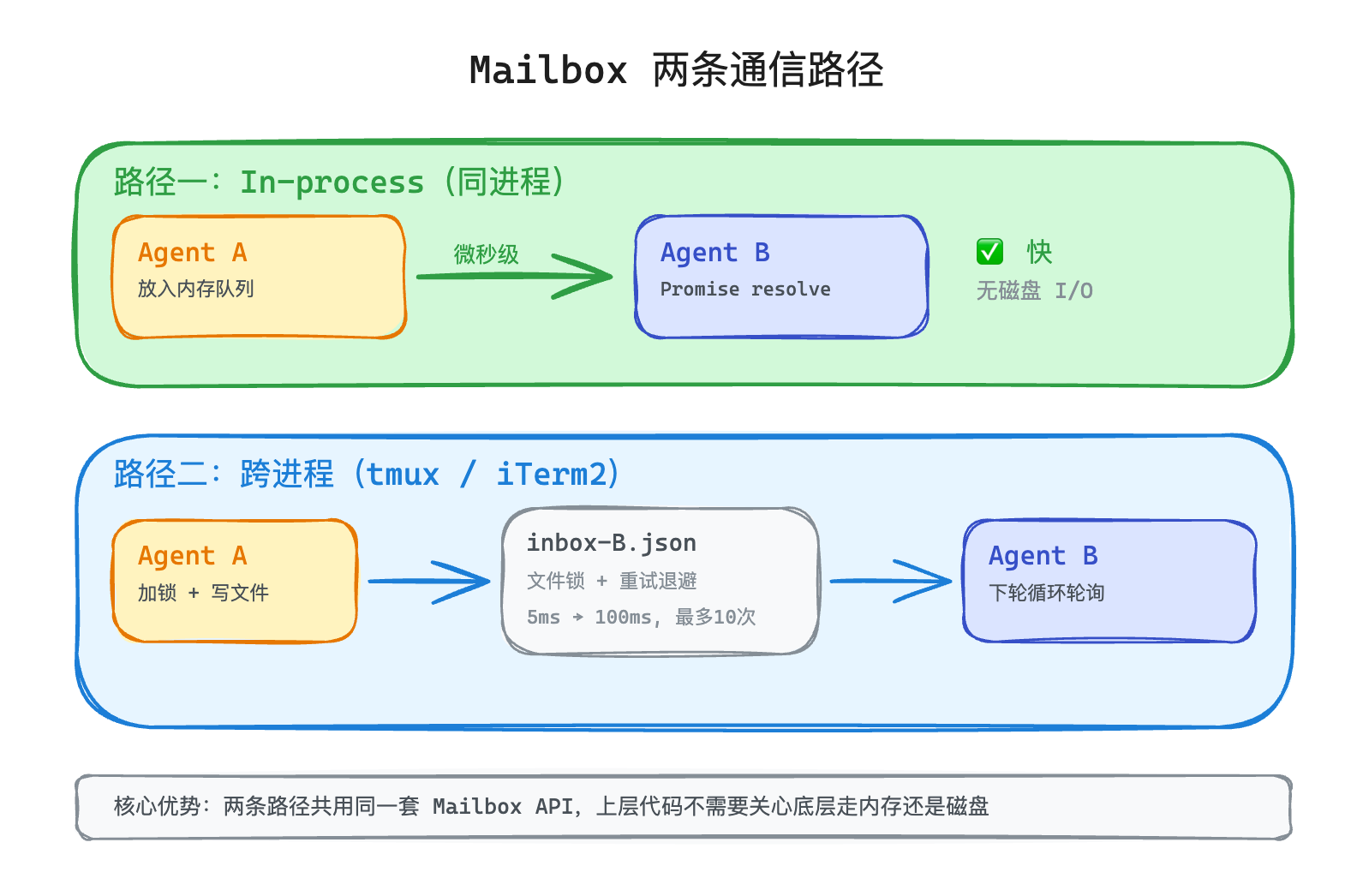
先看通信怎么做。Claude Code 的方案叫 Mailbox——每个 Agent 有一个"收件箱",其他 Agent 往里面写消息,Agent 自己来读。
具体来说,每个团队成员在磁盘上有一个 JSON 文件当收件箱,路径类似 ~/.claude/teams/{team-name}/inboxes/{agent-name}.json。要给某个 Agent 发消息,就往它的收件箱文件里追加一条记录。
Agent 在每轮 Agent Loop 的间隙检查自己的收件箱,有新消息就读取处理。
消息的格式非常简单——发送者、文本内容、时间戳、已读标记、颜色标识。没有什么复杂的消息协议。
SendMessage 工具支持三种发送方式:
指定某个 teammate 的名字发点对点消息。
用
*广播给所有人。发送结构化请求(比如关闭请求、计划审批)。
消息的投递时机也有讲究——Agent 不是实时监听收件箱的(那太浪费资源),而是在每轮 Agent Loop 的工具调用间隙检查一次。如果 Agent 正在执行一个耗时的工具调用(比如跑测试),消息就得等这轮工具执行完才能被看到。所以 Mailbox 的通信节奏更像邮件而不是微信——发出去之后,对方下一次"检查收件箱"的时候才能看到,中间可能隔几秒也可能隔几十秒。
你可能会问:用文件做消息队列,性能不会很差吗?
不可否认,文件 I/O 比内存通信慢。但 Claude Code 做了一个优化:如果两个 Agent 跑在同一个进程里( in-process 模式),就跳过文件 I/O,直接在内存里传递消息。具体来说,发送方把消息放进一个内存队列,接收方那边有一个 Promise 在等着——消息一到,Promise 立刻 resolve,接收方马上就能处理。这比读写文件快得多,延迟从毫秒级的磁盘 I/O 降到微秒级。只有跨进程的 Agent 才需要走磁盘(tmux 是一个终端复用工具,可以在一个终端窗口里开多个独立面板,每个面板跑自己的进程)。
并发安全也是文件方案的一个痛点。两个 Agent 同时往同一个收件箱写消息,可能会互相覆盖。Claude Code 用文件锁 + 重试退避来解决——写入前先加锁,拿不到锁就等一等(从 5ms 开始,指数退避到 100ms,最多重试 10 次)。
共享任务列表:怎么防止抢活
团队需要一个共享的任务列表来协调分工。Claude Code 的做法是给每个团队创建一个独立的任务目录,所有成员通过团队名字解析到同一个目录。
关键问题是并发控制。多个 Agent 可能同时想创建任务、认领任务、更新状态。Claude Code 的方案跟上面说的 Mailbox 类似——文件锁 + 重试。不过参数更激进一些:最多 30 次重试,退避从 5ms 到 100ms,给 10 个以上并发 Agent 留了足够的重试预算。
这里有一个容易出问题的点:同一套代码要支持三种运行模式(in-process、tmux、iTerm2),怎么保证所有 Agent 都找到同一个任务列表?Claude Code 的做法是用团队名字作为任务目录的统一标识——不管 Agent 从哪种方式启动,只要拿到了团队名字,就能解析到同一个任务目录。
Permission Sync:最难的一个问题
Swarm 里最有挑战性的工程问题是权限代理。
场景是这样的:一个 Worker Agent 跑在 tmux 的后台 pane 里,没有 UI 交互能力。它需要执行一个 rm -rf build/ 命令,按权限策略这个操作需要用户确认。它怎么问用户?
Claude Code 的解法是权限请求转发——Worker 把请求写到一个 pending/ 目录,Leader Agent 定期轮询这个目录,看到请求后呈现给用户。用户批准或拒绝后,结果写入 resolved/ 目录,Worker 读取结果继续(或放弃)执行。
这个链路有一个很微妙的设计:如果 Worker 和 Leader 跑在同一个进程里(in-process 模式),就不需要走文件——直接共享内存中的 ToolUseConfirmQueue,Leader 立刻能看到请求。只有跨进程的情况才走文件中转。
举一个具体的时序帮你理解这个流程:Worker 在 tmux pane 里执行到 rm -rf build/,权限系统拦截了这个操作,Worker 把请求序列化后写入 pending/rm-build-12345.json。Leader 在下一轮 Agent Loop 里轮询到这个文件,把请求呈现给用户——"Worker-Auth 想执行 rm -rf build/,允许吗?"。用户点了允许,Leader 写入 resolved/rm-build-12345.json(状态为 approved)。Worker 在自己的下一轮循环里读到了 resolved 文件,继续执行。整个来回的延迟取决于用户的响应速度和两边的轮询间隔。
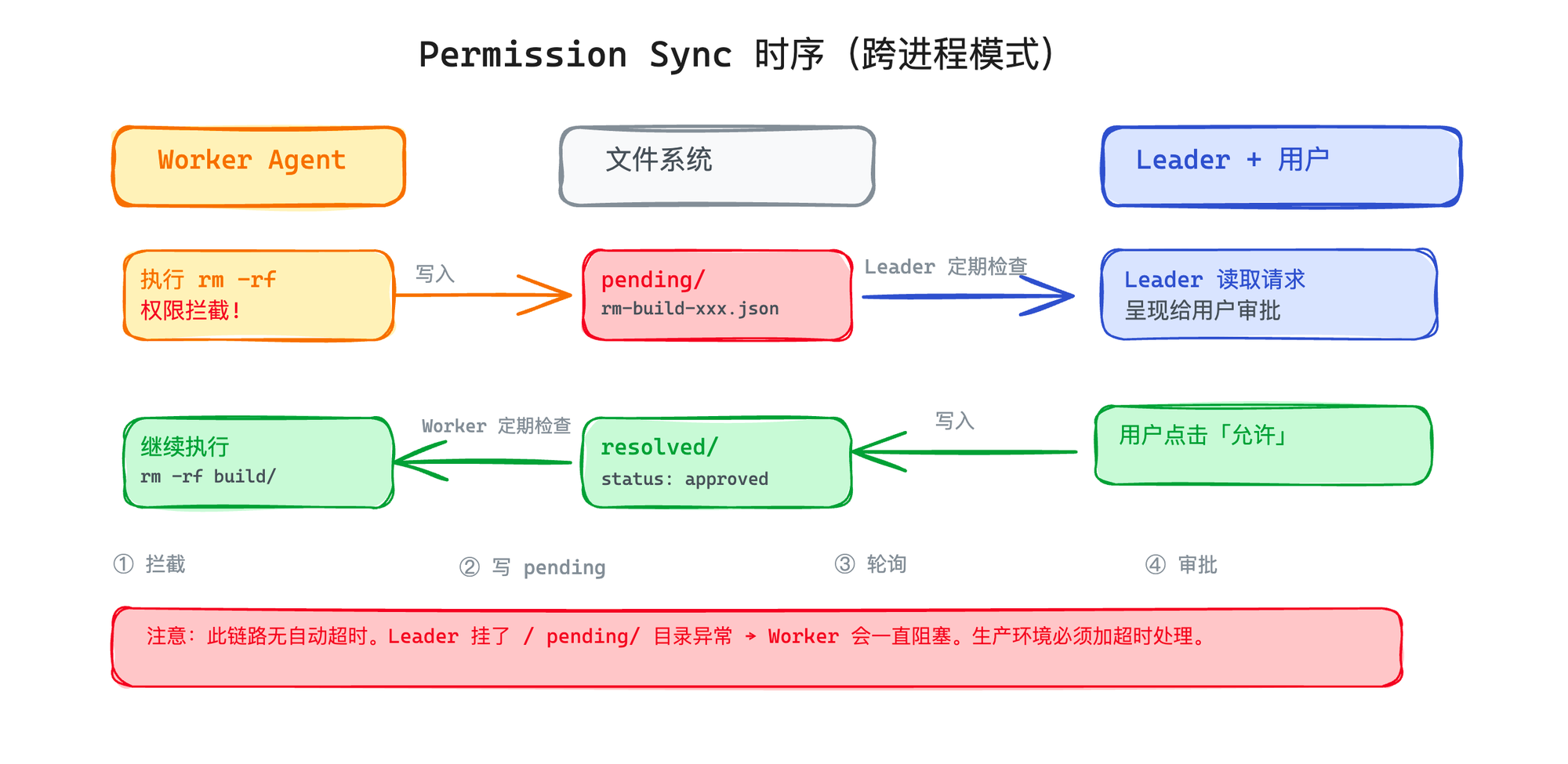
这个链路一旦断了——比如 Leader 挂了、或者 pending/ 目录权限有问题——Worker 就会一直阻塞在轮询 resolved/ 文件这一步。Permission Sync 目前没有自动超时机制,能让 Worker 停下来的只有用户手动中断或者 Leader 主动发 shutdown 请求。这是 Swarm 架构里一个值得注意的薄弱点——如果你要在生产环境用类似的设计,给权限等待加一个超时是必须做的。
如何关闭:Agent 不能自己决定"我干完了"
另一个容易被忽视的问题是团队的关闭流程。
直觉上你会觉得:Agent 做完任务就退出呗,有什么好协调的?
但实际上,如果让 Agent 自己决定"我干完了",会出问题。Agent 可能觉得自己的部分做完了,但其实还有测试没跑、文档没写、或者其他 Agent 依赖它的输出还没拿到。提前退出会导致最后产出了一个半成品。
Claude Code 的方案是 Leader 审批制关闭。Worker 想退出时,先给 Leader 发一个 shutdown 请求。Leader 检查这个 Worker 的任务是否真的完成了——如果没完成,Leader 可以拒绝请求并告诉它还需要做什么。只有 Leader 确认后,Worker 才能真正退出。
关闭的物理流程也有讲究:先终止 tmux pane(停掉进程),再清理 worktree(如果有的话),最后删除团队目录和任务目录。顺序不能乱——如果先删了任务目录,还在跑的 Agent 就找不到任务列表了。
Leader 在发起全局 shutdown 之前,还会等所有 teammate 进入 idle 状态。每个成员有一个 isIdle 标记,Leader 注册回调函数等待所有人都 idle 了才开始关闭流程。
两种执行后端
前面反复提到"in-process"和"tmux"两种模式。Claude Code 的 Swarm 同时支持三种 teammate 执行后端,这在整个行业里是独一份的:
In-process 模式:teammate 和 Leader 跑在同一个 Node.js 进程里,用 AsyncLocalStorage 隔离上下文。好处是零启动延迟、通信走内存。坏处是一个 teammate 如果陷入死循环,会拖慢整个进程。还有一个有意思的设计细节——teammate 的 AbortController 不链接到 Leader 的。你按 ctrl+c 中断 Leader,正在工作的 teammate 不会被杀掉。这是故意的——防止 Leader 的一次操作失误把所有人的工作都毁了。
Tmux 模式:前面提过,tmux 能在一个终端窗口里开多个独立面板。Claude Code 给每个 teammate 开一个面板,每个 teammate 就是一个独立的 Claude Code 进程。好处是真正的进程隔离——一个崩了不影响其他人。坏处是启动慢、通信走文件 I/O,比较适合长时间运行的重型任务。
iTerm2 模式:跟 tmux 类似,但用的是 macOS 原生的 iTerm2 分屏。用户体验更好(能直接在 iTerm2 里看到每个 Agent 的输出),但只能在 macOS 上用。
三种后端共享同一套 Mailbox、任务列表和团队文件。这是 Claude Code Swarm 架构里最优雅的设计之一——不管 Agent 以什么方式启动,它看到的世界是一致的:同一个任务列表、同一套收件箱、同一份团队配置。
实际使用中,后端选择是自动的——Claude Code 启动 teammate 时会检测当前环境:装了 tmux 就用 tmux,装了 iTerm2 就用 iTerm2,都没有就 fallback 到 in-process。用户不需要手动指定。
行业里的其他方案
Claude Code 的 Swarm 是 hub-and-spoke 模式——Leader 是中心节点,所有通信经过它。但行业里还有其他思路。
OpenAI Swarm 走了一条极简路线——Agent 通过函数调用直接把控制权"交接"(handoff)给另一个 Agent。没有中心节点,没有消息队列。一个 Agent 返回另一个 Agent 对象,系统就切换到那个 Agent 继续对话。共享的是对话历史,每个 Agent 用自己的 system prompt 和工具集来解读同一段历史。OpenAI 自己定义这个框架为"教学用途",生产级的方案已经升级为 Agents SDK。
AutoGen(微软)选了另一条路——GroupChat 模式。所有 Agent 在同一个聊天室里,一个 GroupChatManager 决定"下一个谁说话"。选人的策略可以是 LLM 决定(根据上下文判断谁最适合接话)、轮流、或者自定义规则。好处是所有 Agent 共享完整上下文,信息不会丢。坏处也很明显——上下文会快速膨胀,而且全靠 LLM 选下一个 speaker 本身就不太靠谱。
Anthropic 在 Building Effective Agents 博客里给出了一组很重要的数据:单 Agent 在 64% 的基准测试中表现等于或优于 Multi-Agent 系统,Multi-Agent 只带来了 2.1 个百分点的准确率提升,但成本大约翻了一倍。 不过成本可以通过模型分层来优化——Leader 用强模型,Worker 用便宜的模型,能省 40%-60% 的开销。
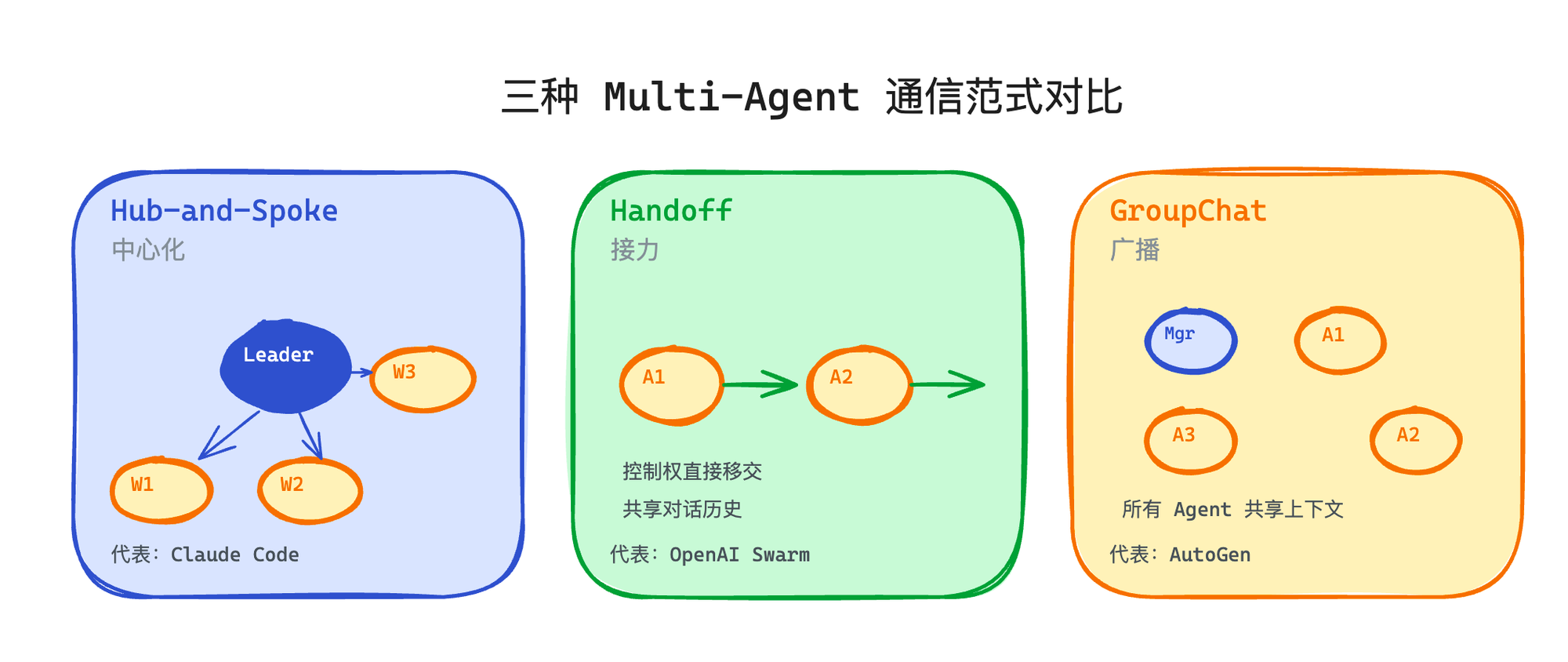
这三种方案代表了通信模式的三种基本范式——hub-and-spoke(中心化)、handoff(接力)、groupchat(广播)。选择哪种取决于你的场景:Agent 之间需要频繁来回协商用 hub-and-spoke;任务是线性流转的用 handoff;所有 Agent 需要看到全局信息用 groupchat。没有哪种是绝对更好的。
Anthropic 的数据也再次印证了上一篇的结论:不要为了 Multi-Agent 而 Multi-Agent,大多数场景单 Agent 就够了。
什么时候值得用 Swarm
结合前面的分析和行业数据,Swarm 模式真正适合的场景其实不多,但一旦适合,收益非常明显:
多模块并行开发——三个独立但有接口依赖的模块同时推进,Agent 之间需要协商接口定义、同步进度。用父子模式做不了这种横向协调。
长时间运行的复合任务——比如一个持续几十分钟的大型重构,涉及前端、后端、测试多个维度。每个维度的 Agent 跑在独立进程里(tmux 模式),一个崩了不影响其他人的进度。
需要人工审批的分布式工作流——多个 Worker 各自推进,遇到高风险操作时通过 Permission Sync 机制把审批请求汇总到 Leader,用户在一个地方统一处理。
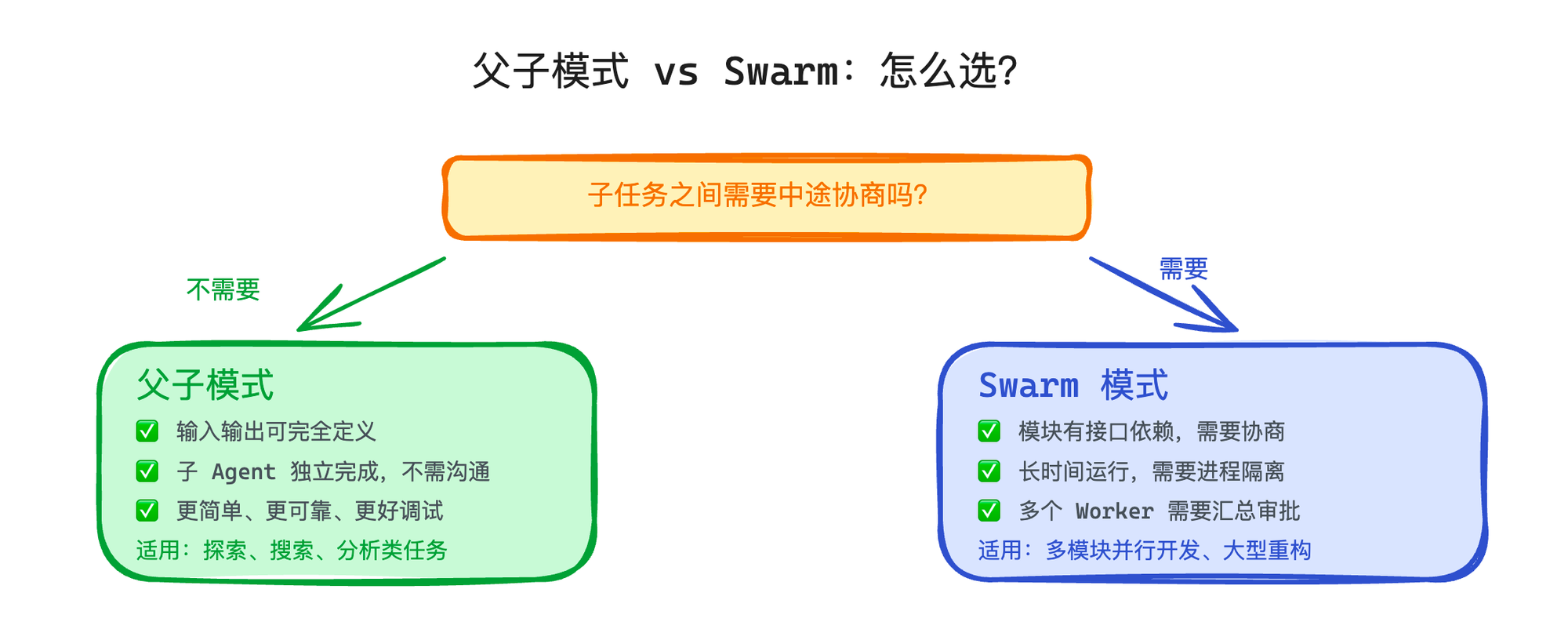
不适合 Swarm 的场景也很清楚:如果任务之间不需要互相通信,用父子模式就够了——更简单、更可靠、更好调试。Swarm 的 Mailbox、任务列表、权限代理这些机制都是有成本的,只有真正需要 Agent 之间横向协调的场景才值得承担这些复杂度。一个简单的判断标准是:
如果你能把每个子任务的输入输出完全定义清楚,不需要中途沟通,那就是父子模式的事;
如果子任务之间的依赖需要在执行过程中动态协商,才是 Swarm 发挥作用的地方。
参考资料
Claude Code Sub-agents 文档: https://code.claude.com/docs/en/sub-agents
Anthropic: Building Effective Agents: https://www.anthropic.com/research/building-effective-agents
Anthropic Cookbook (Orchestrator-Workers): https://github.com/anthropics/anthropic-cookbook/blob/main/patterns/agents/orchestrator_workers.ipynb
OpenAI Swarm: https://github.com/openai/swarm
AutoGen GroupChat: https://microsoft.github.io/autogen/stable/user-guide/core-user-guide/design-patterns/group-chat.html
Why Do Multi-Agent LLM Systems Fail?: https://arxiv.org/pdf/2503.13657
Orchestrator-Worker Comparison (Arize AI): https://arize.com/blog/orchestrator-worker-agents-a-practical-comparison-of-common-agent-frameworks/
