
试想一个场景,你让 Agent 去分析一个中型代码仓库——200 个文件、十几个模块。Agent 开始工作了:先读 package.json,再读几个配置文件,然后逐个模块浏览源码、读测试、查依赖关系。
干到一半你发现问题了。Agent 已经读了 50 多个文件,上下文里塞了十几万 token,但它的分析开始"走神"——前面读过的文件内容已经被挤到注意力的边缘,回答质量明显下降。上下文窗口就这么大,你往里面塞的东西越多,模型对每条信息的"记忆力"就越差。
这个问题在前面讲 Context Rot 的时候就提过了。当时的应对手段是上下文压缩——我们讲过的那套从 soft trim 到 hard clear 再到 memory flush 的多级压缩策略。但压缩有上限——压得太狠信息就丢了,压得不够空间还是不够用。
这时候你可能会想:能不能派几个"小弟"出去,让它们各自负责一部分,干完了把结论带回来? 一个小弟去看前端模块,一个去看后端 API,一个去看测试覆盖率——每个小弟在自己的上下文里干活,最后把结论汇总到主 Agent 这里。
这就是 Multi-Agent 最核心的动机。
所以 Multi-Agent 的本质不是什么"一个负责规划、一个负责执行、一个负责评审"这种角色扮演。它是一种上下文管理策略——每个子 Agent 有自己独立的上下文窗口,探索完把结果压缩回传,父 Agent 的上下文始终保持干净。
先讲一个误区
聊 Multi-Agent 之前,我想先把一个容易先入为主但有问题的模式讲清楚。
Manus 团队说过一句很精辟的话:人类组织之所以有部门分工,是因为每个人的"上下文窗口"(认知带宽)有限。但 AI Agent 不存在这个限制——只要上下文装得下,一个 Agent 完全可以同时承担多个角色。
你去搜 "multi-agent tutorial",十篇有八篇教你搭一个三件套:Planner Agent 负责拆任务,Executor Agent 负责干活,Reviewer Agent 负责检查。听起来很合理对吧,感觉是一个看起来很酷的组合。
但实际跑起来你会发现很多问题。
第一,出了错你不知道该怪谁。生成的代码有 bug,是 Planner 的任务拆得不好、Executor 理解错了、还是 Reviewer 没检查出来?三个 Agent 的上下文互相交织,排查问题的复杂度直接翻了几倍。
第二,协调本身就是开销。2025 年有一份研究分析了多个 Multi-Agent 系统的失败案例,其中有数据表明 36.9% 的失败来自协调出现了问题,每多一个 Agent,潜在的交互路径会急剧增长。
这不是说 Multi-Agent 没用。拆 Agent 也是有正当理由的——上下文装不下了、需要并行提效、需要任务隔离,但"我需要一个 Planner 角色"不在其中。我们先讲最基础的动机:上下文容量。
父子模式:最基础的 Multi-Agent 架构
理解了动机之后,我们来看最基础、也是最实用的 Multi-Agent 模式——父子模式。
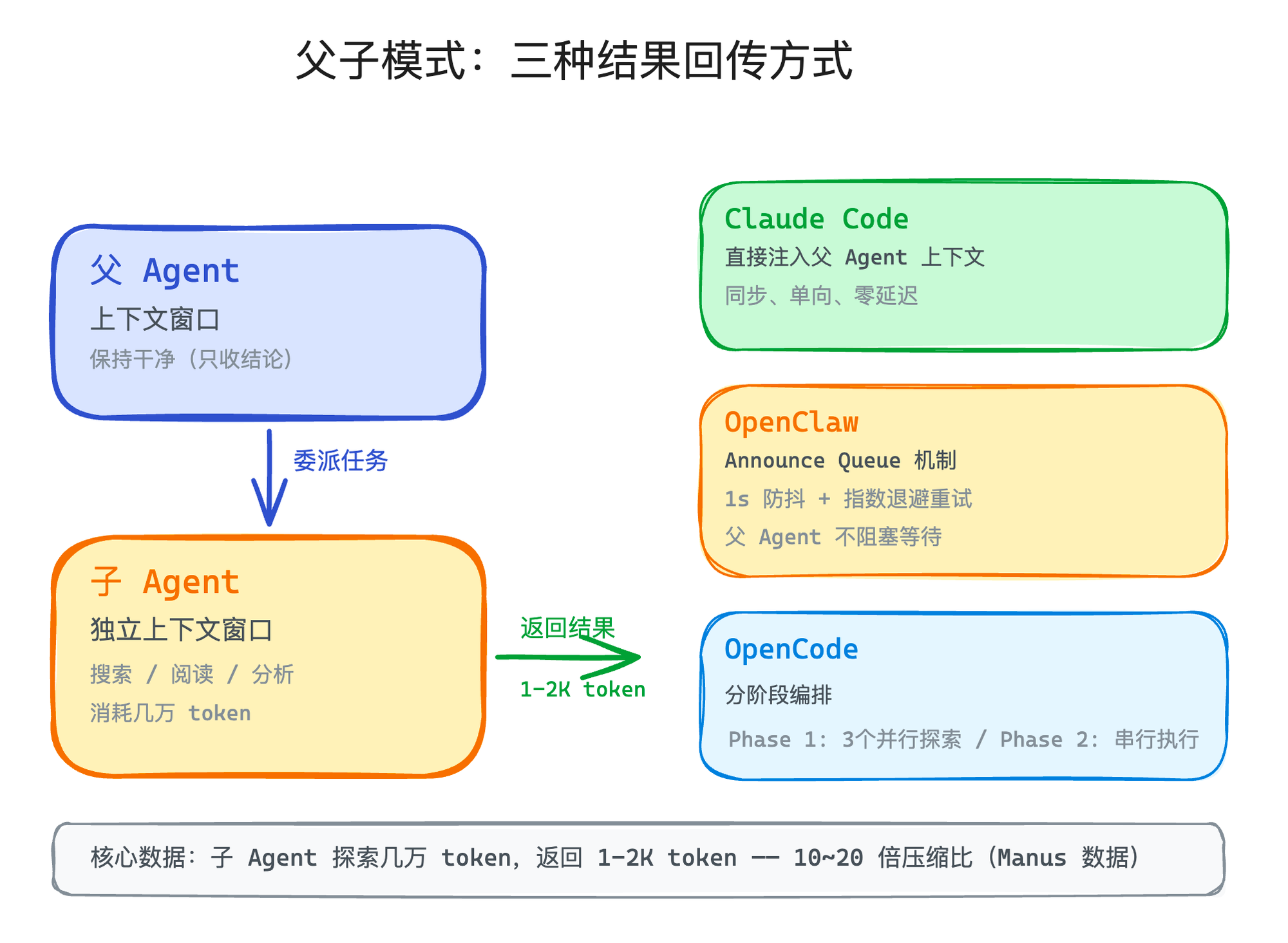
父 Agent 生一个子 Agent,给它一个任务,等它干完,拿回结果。就这么简单。
Claude Code 的 Agent 工具就是这个模式。你在跟 Claude Code 对话的时候,它觉得某个子任务需要深入探索(比如搜索整个代码库里某个函数的所有调用方),它会自己派一个子 Agent 出去。子 Agent 在自己独立的上下文窗口里搜索、阅读、分析,最后把结论打包返回给父 Agent。
如果你用过 Claude Code,你应该见过这种场景——它在回答复杂问题时会显示"Explore...",然后子 Agent 在后台跑了一段时间,最后一段精简的结论出现在对话里。你看到的就是子 Agent 的返回结果,背后可能读了几十个文件、做了十几次搜索,但你的主对话上下文里只多了几百 token 的结论。
具体来说,委派任务有两种方式:
轻量委派:只给子 Agent 一个任务描述,让它自己去探索。比如"找出所有引用了 formatDate 函数的文件"。子 Agent 从零开始,自己决定怎么搜、搜哪里。这种方式适合探索性任务——你不确定答案在哪,让子 Agent 去翻。
重量委派:除了任务描述,还附带一些上下文片段——可能是一段代码、一份文件内容、或者前面对话的关键摘要。子 Agent 有了更多背景信息,不需要从零开始。这种方式适合你已经知道方向、只是需要子 Agent 深入挖掘的场景。
子 Agent 完成任务后,结果回传的方式在不同产品里有所不同。
Claude Code 最直接——子 Agent 的最终输出作为工具结果直接注入父 Agent 的上下文,跟普通的工具调用没什么区别。前面讲工具执行管线的时候说过,工具结果会走截断和持久化流程,子 Agent 的返回结果也不例外——太长了一样会被截断,只保留关键信息。整体的特点就是,单向、同步、零延迟。
OpenClaw 做得更精细一些。它有一个叫 Announce Queue 的机制——子 Agent 完成后,结果不是立刻投给父 Agent,而是先进入一个通知队列。队列有 1 秒的防抖间隔(避免子 Agent 频繁更新时父 Agent 被打断太多次),还有指数退避重试(投递失败时从 2s 开始翻倍,4s、8s 一直到上限 60s)。这样父 Agent 不会被阻塞等待,也不会被子 Agent 的中间状态频繁打断。
OpenCode 走了另一条路——分阶段编排。Phase 1 最多派 3 个 Explore Agent 并行出去搜集信息,Phase 2 切回串行设计,逐步执行。先散后收,很像你带团队的方式:先让几个人各自去调研,等调研结果都回来了,再坐下来一步步推进。
三种隔离思路
父子模式解决了"怎么拆任务"的问题。但紧接着还有一个更底层的问题:多个 Agent 同时跑的时候,怎么保证它们不互相干扰?
一个 Agent 在读文件、另一个在改文件,两个撞一起就出事了。或者两个子 Agent 都在同一个进程里跑,共享了某些全局状态,一个改了状态另一个还在用旧值——这种 bug 查起来让人崩溃。
这就是隔离问题。业界有三种主流思路,各有各的适用场景。
思路一:共享内存,进程内隔离
最轻量的方案——所有 Agent 跑在同一个进程里,用语言层面的机制来隔离状态。
Claude Code 用的是 Node.js 的 AsyncLocalStorage。如果你做过 Node.js 后端开发应该对这个东西不陌生,它本来是用来做请求级别的上下文隔离的(比如每个 HTTP 请求有自己的 traceId),Claude Code 把它拿来给每个子 Agent 创建独立的异步上下文。
具体来说,每个子 Agent 启动时,Claude Code 会给它克隆一份文件状态缓存,而不是共享同一份。这样一个子 Agent 改了文件状态,不会影响另一个子 Agent 看到的数据。
这个方案的好处是零 IPC(进程间通信) 开销——因为都在同一个进程里,没有跨进程通信,启动快、内存压力也小。坏处是隔离不够彻底——如果有人不小心用了全局变量,还是会互相覆盖。
OpenCode 的做法更简单——虽然它在搜集信息阶段会并行派出多个 Explore Agent,但所有对文件的实际操作都是串行的,同一时间只有一个 Agent 在读写文件系统。这样压根不需要做隔离,因为不存在两个 Agent 同时改同一个文件的情况。牺牲了一些并行效率,但省掉了所有并发控制的复杂度。
思路二:Worktree,文件系统完全隔离
如果子 Agent 需要做破坏性操作——比如大规模重构、实验性修改——你不希望它在主代码目录上直接动手。万一改坏了呢?
Claude Code 对这种场景提供了 Worktree 模式。它用 git worktree 给子 Agent 创建一个独立的工作目录——本质上是同一个 git 仓库的另一份副本。子 Agent 在自己的 worktree 里随便改,改好了再 merge 回来;改坏了直接删掉,主目录一点都不受影响。
为了省磁盘空间,Claude Code 还做了一个小优化:node_modules 这类依赖目录不会重复安装,而是用软链接(symlink)指回主目录的那份,只有源码文件是独立副本。
这个方案的好处是源码层面彻底隔离——子 Agent 在 worktree 里怎么改都不影响主目录。坏处是开销大——创建 worktree 要时间,源码也多占一份磁盘。所以它适合那种"子 Agent 要做高风险操作"的场景,不适合日常的小任务委派。
思路三:队列串行化,用排队代替锁
OpenClaw 的 Lane 模型走了第三条路——不做复杂的状态隔离,用队列来保证同一个 session 里的操作按顺序执行,天然不会冲突。
Lane 是什么概念?可以理解为"车道"。不同类型的任务走不同车道,每条车道有自己的并发配额:
main车道:最多 4 个 Agent 并发cron车道:最多 1 个(定时任务串行跑)subagent车道:最多 8 个并发
同一个 session 内部是严格串行的——消息进来先排队,前一个处理完才轮到下一个。这意味着不需要复杂的锁机制或状态克隆,队列本身就是最简单的并发控制。
跨 session 之间是并行的,每个 session 走自己的队列,互不影响。
具体到实现层面,OpenClaw 用的是嵌套队列——消息到达后先进 session 级别的队列(保证 session 内串行),session 队列处理时再进全局 lane 的队列(控制并发上限)。两层队列嵌套在一起,既保证了单 session 内的操作有序,又允许不同 session 之间合理并发。
这个设计很务实——大部分 Agent 场景其实不需要"两个 Agent 同时改同一个文件"这种高难度的并发操作。用队列把同一个 session 的操作排好队,就能解决 90% 的并发问题。

三种思路适用的场景很清晰:日常的信息搜集、代码分析这类轻量任务,用进程内隔离就够了,启动快开销小;子 Agent 需要大规模修改文件的破坏性操作(重构、实验性分支),上 Worktree 隔离文件系统;如果你的产品是多用户多 session 的架构,Lane 模型用队列自然解决了并发问题,不需要自己管锁。
并发安全:几个容易踩的坑
隔离模型选好了,还有几个实操层面的并发问题需要处理。
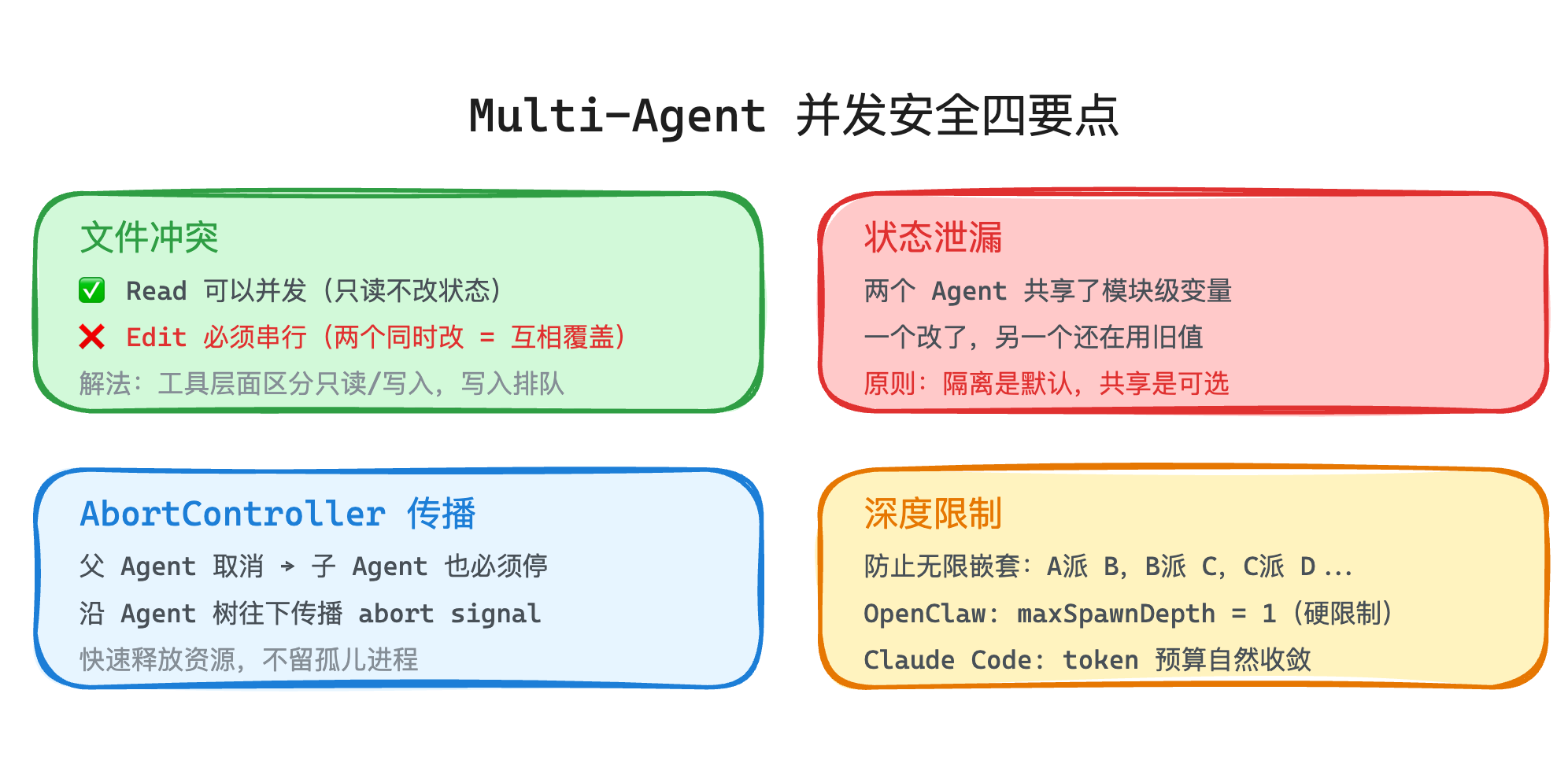
文件冲突是最直接的。多个 Agent 并行工作时,Read 操作可以随便并发——读文件不改状态,谁先谁后都无所谓。但 Edit 操作必须串行——两个 Agent 同时改同一个文件,结果就是互相覆盖。Claude Code 在工具层面做了这个区分:只读工具标记为可并发,写入工具排队执行。
状态泄漏是更隐蔽的问题。两个子 Agent 共享了一个模块级别的变量,一个改了另一个还在用旧值——这类 bug 在单 Agent 的时候根本不会出现,一上 Multi-Agent 就冒出来了。核心原则是:隔离是默认的,共享是可选的——任何跨 Agent 的状态共享都必须是你显式决定的,不能是意外发生的。
AbortController 的传播同样容易被忽略。父 Agent 取消了一个任务,子 Agent 也必须跟着停下来,不然子 Agent 还在那里消耗资源。OpenClaw 的做法是把 abort signal 沿着整个 Agent 树往下传播——父 abort 了,所有子孙都收到信号,快速释放资源。
深度限制是另一个必须要有的保险——本质上跟前面讲的 Agent Loop 保险丝是一个思路,防止 Agent 无限消耗资源。子 Agent 能不能再派子 Agent?如果可以,理论上可以无限嵌套下去——A 派了 B,B 派了 C,C 再派 D……每一层都消耗资源和时间。对这个问题,不同的产品也各有解决思路,你可以进行参考:
OpenClaw 直接设了一个硬限制:
maxSpawnDepth = 1,也就是子 Agent 不能再派子 Agent,它就是叶子节点。Claude Code 没有设硬限制,而是靠 token 预算自然收敛——子 Agent 分到的 token 预算有限,用完了就得收工,自然没法无限嵌套下去。
拆 Agent 是有成本的
最后想强调一个反直觉的结论:能用一个 Agent 搞定的事,就别拆成多个。
每多一个 Agent,你就多了一层通信开销(子 Agent 启动、执行、回传结果都需要时间)、多了一组需要调试的交互(结果不对是父 Agent 描述不清还是子 Agent 理解偏了?)、多了一个潜在的故障点(子 Agent 卡住了怎么办?超时了怎么办?)。
前面工具系统那篇讲过 Manus 的一句话——"heavily armed agents get dumber",给 Agent 堆太多武器它反而变笨了。Multi-Agent 也是同样的道理:Agent 不是越多越好,协调本身就是成本。
判断该不该拆,就一条标准:你的上下文是不是真的装不下了? 如果一个 Agent 就能在上下文窗口内完成任务,那多个 Agent 只会增加不必要的复杂度。如果上下文确实不够用——一个 Agent 读了 50 个文件还需要继续读,压缩也压不动了——这时候才值得派子 Agent 出去,用独立的上下文窗口来承载那些放不下的信息。
