
我们已经把 RAG 管线从搭建到优化都讲透了。分块、embedding、混合检索、Reranker——一套流程走下来,确实能让 Agent "查到资料"了。
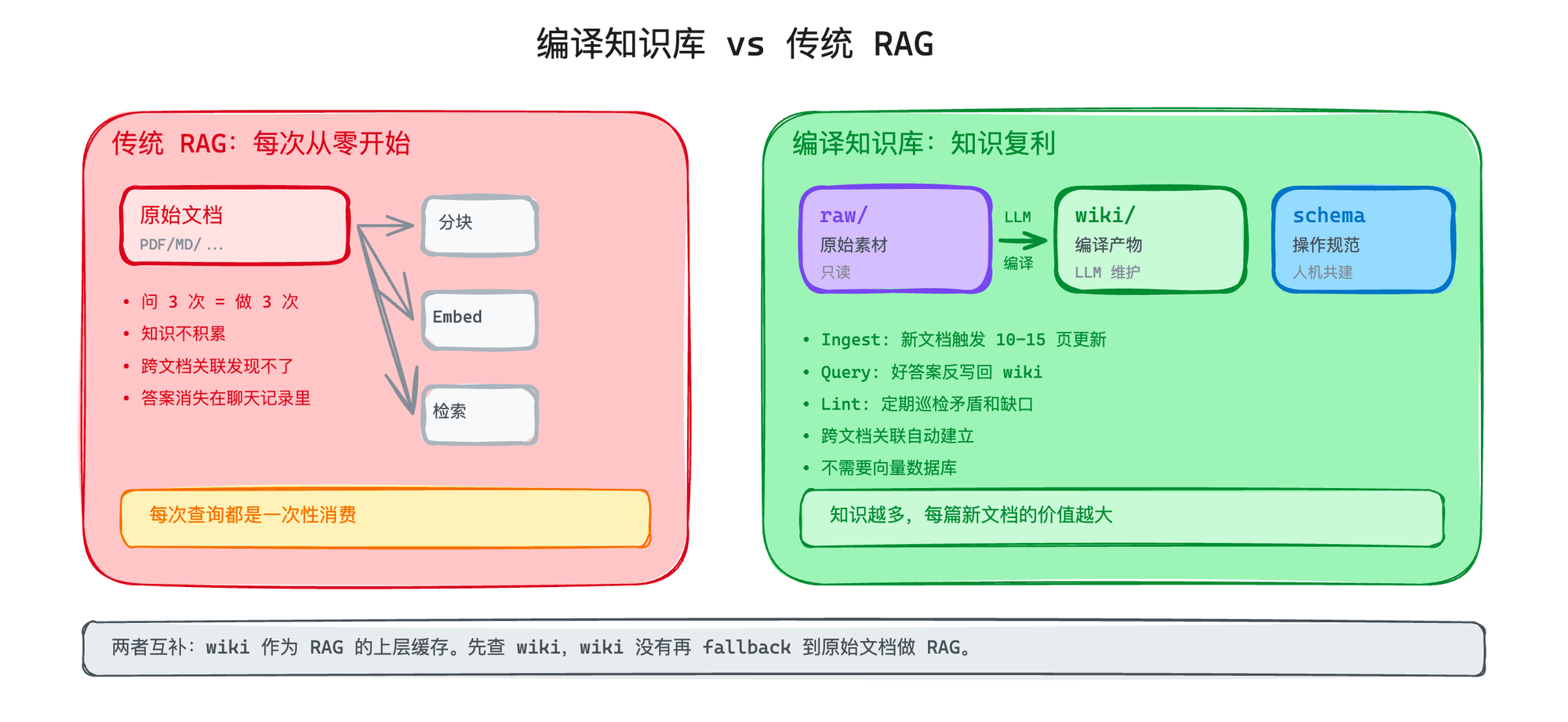
但用了一段时间你会发现一个问题:每次查询都是从零开始的。
你上周问过"我们的部署流程是什么",Agent 检索了一遍文档,综合了三个 chunk,给了你一个不错的回答。今天你同事问了同样的问题——Agent 又从头检索了一遍,又综合了一遍,可能给出一个措辞不同但内容差不多的答案。
三个人问三次,Agent 做了三次完全相同的工作。知识没有积累,答案没有沉淀。
还有一个更深层的问题:跨文档的关联,RAG 几乎发现不了。
文档 A 说"我们的用户增长在 Q2 放缓了",文档 B 说"Q2 我们砍掉了增长团队的预算"。这两件事之间的因果关系,人看了一眼就明白,但向量搜索做不到——因为这两段话在语义空间里可能离得很远,各自的关键词也重叠度不高。
RAG 解决的是"找到相关内容"的问题,但它不解决"理解内容之间的关系"和"让知识持续积累"的问题。
2026 年 4 月,Andrej Karpathy 发了一篇 gist,提出了一个思路,在技术圈引起了很大的反响。他的核心观点是:别让 LLM 每次都从原始文档里临时拼凑答案了,让它先把文档"编译"成一个结构化的知识库,后面查的时候直接查编译产物。
编译器类比:从源码到产物
Karpathy 用了一个程序员秒懂的类比:
原始文档就是源码,LLM 就是编译器,Wiki 就是编译产物。
你不会每次运行程序的时候都从源码编译一遍吧?你编译一次,生成可执行文件,后面直接跑可执行文件。RAG 就像每次都从源码解释执行——能跑,但慢,而且每次的执行路径可能不同。
编译知识库的思路是:让 LLM 提前把原始文档"编译"成结构化的 wiki 页面,建好交叉引用和索引。后面查询的时候,直接在编译产物上检索,而不是回到原始文档。
而且更关键的是:每次新增一篇文档,LLM 会把新信息整合进已有的知识体系里——更新相关的实体页面、修订摘要、标注矛盾、补充交叉引用。一篇新文档进来,可能触发 10-15 个已有页面的更新。
这就是"知识复利"——知识越多,每一篇新文档带来的价值越大,因为它跟已有知识产生的连接越多。
Karpathy 自己的描述更直白:"Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。"
三层架构
编译知识库的架构很清晰,分为三层:
Layer 1:raw/(原始素材)
你收集的所有原始材料——文章、论文、PDF、会议记录、截图、数据文件。这一层是只读的,LLM 可以读但不能改。它是你的 source of truth。
Layer 2:wiki/(编译产物)
LLM 生成和维护的结构化 Markdown 文件。这一层完全由 LLM "拥有"——它负责创建页面、更新内容、维护交叉引用、保持一致性。你读它,LLM 写它。
wiki 里面存的是经过整合的知识:实体页面(某个人、某个产品、某个概念的全貌)、对比分析(A 和 B 的区别)、综述页面(某个领域的全景)、时间线(事件的发展脉络)。
Layer 3:schema(操作规范)
一个配置文件(在 Claude Code 里就是 CLAUDE.md),告诉 LLM 这个 wiki 的结构约定、命名规范、工作流程。这一层是你和 LLM 共同维护的——你定规则,LLM 按规则执行。
这三层的关系可以类比成软件开发:raw/ 是需求文档,wiki/ 是代码,schema 是编码规范。
三个核心操作
整个编译知识库只有三个操作,非常简洁。
Ingest(摄入)
新素材进来的时候,LLM 做的事情不是简单地"存一下"。它会读完原始文档,创建一个摘要页面,然后扫描已有的 wiki 找到所有相关的实体和概念——更新它们的内容、补充新信息、标注矛盾、建立交叉引用,最后更新索引和日志。
整个流程用图来看更直观:
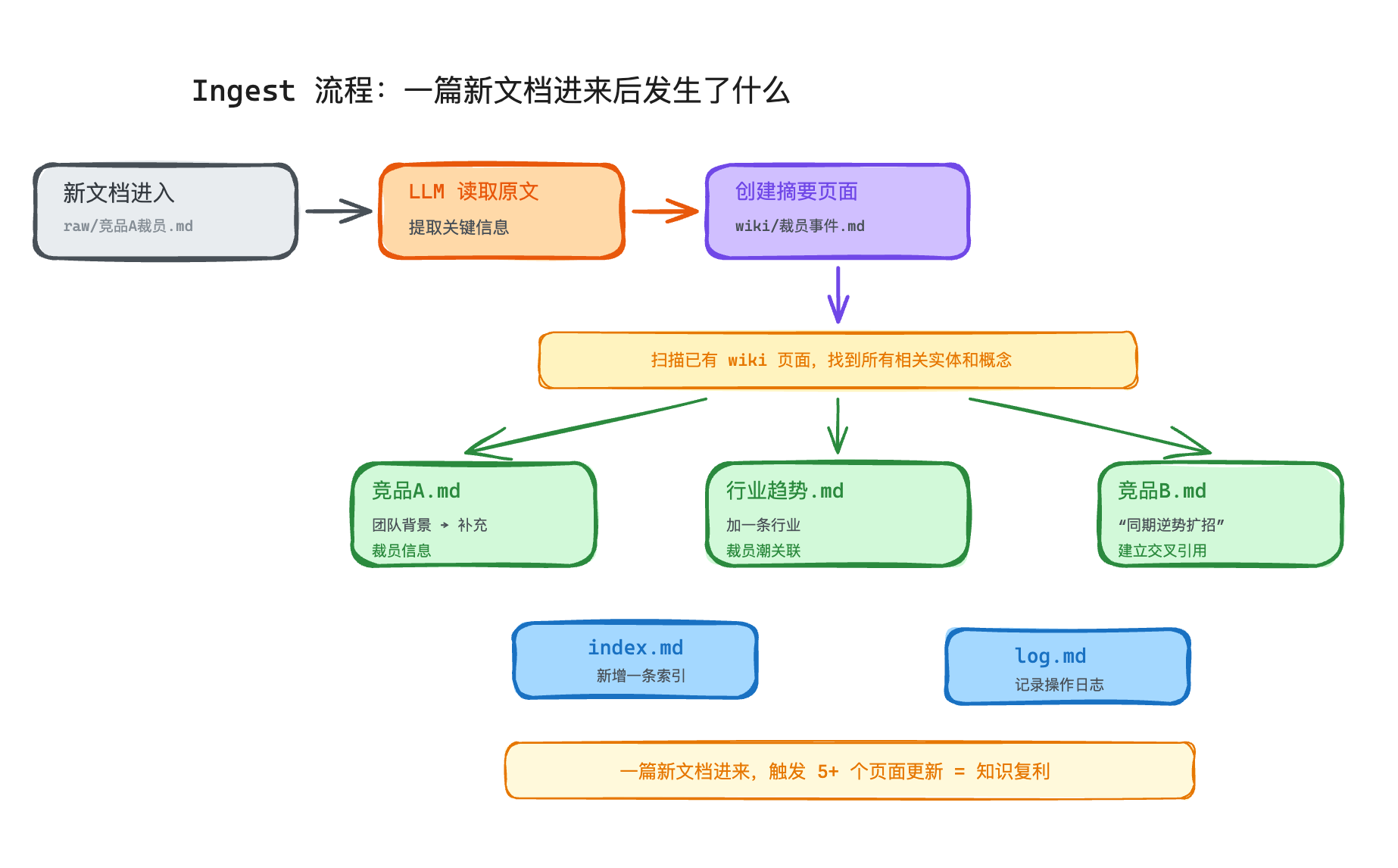
一篇新文档进来,可能触发五个以上页面的更新。这就是为什么说"知识在复利"——不是线性增长,是网络效应。
Karpathy 说他更喜欢一次 ingest 一篇,中间参与一下——看看摘要对不对,引导一下重点。但批量 ingest 也行,看你的场景。
举个具体例子。假设你在做竞品分析,已经 ingest 了 10 篇关于竞品 A 的文章,wiki 里有一个 竞品A.md 页面,里面整理了它的产品功能、融资历史、团队背景。现在你找到了一篇新文章,讲的是竞品 A 最近的一次大裁员。
Ingest 这篇文章之后,LLM 不只是创建一个新的摘要页面。它会去更新 竞品A.md,在团队背景的部分补充裁员信息,可能还会标注一下"此前的团队规模数据需要更新"。如果 wiki 里还有一个 行业趋势.md 页面,它可能也会去那里加一条关于行业裁员潮的关联。甚至可能发现 竞品B.md 页面里提到"竞品 B 在同一时期逆势扩招",于是在两个页面之间建立一条交叉引用。
一篇文章进来,知识网络变得更密、更准。这是 RAG 做不到的事情。
Query(查询)
在 wiki 上提问。LLM 先读 index.md 找到相关页面,再深入读具体内容,综合回答并标注来源。
这里有一个 RAG 做不到的事情:好的回答可以反写回 wiki。
你问了一个对比分析的问题——"竞品 A 和竞品 B 在人才策略上有什么区别",LLM 读了两边的页面,给了一个详尽的对比。这个对比分析本身就是有价值的知识,不应该消失在聊天记录里。把它存成一个新的 wiki 页面 竞品人才策略对比.md,下次任何人问类似的问题,直接就能找到。
你的每一次探索都在给知识库增值,而不是一次性消费。 这就是 Karpathy 说的"知识复利"——不只是 ingest 的时候在积累,query 的时候也在积累。
Lint(清理)
定期做一次健康检查:
有没有页面之间互相矛盾?
有没有被新信息推翻的旧内容?
有没有孤立的页面(没有任何其他页面链过来)?
有没有重要概念被提到了很多次,但还没有自己的专属页面?
有没有信息缺口可以通过搜索来补充?
这个操作跟之前讲的"保险丝"是同一个思路——不是等出了问题才修,而是主动巡检、提前发现。
Context Engineering 设计:三级缓存
编译知识库跟上下文管理怎么配合?这里有一个很优雅的三级缓存设计:
L0:index.md 常驻 system prompt
大概 2500 字符,是整个知识库的"目录"。每个 wiki 页面一行,包含链接和一句话摘要。这个东西常驻在 system prompt 里,每次会话都能看到——LLM 知道知识库里有什么,但不需要把所有内容都加载进来。
L1:wiki 页面按需加载
每个页面大约 1500 字符。用户提问的时候,LLM 通过 index.md 定位到相关页面,用 Read 工具读取。只读需要的,不读不相关的。
L2:原始文档仅在必要时回溯
如果 wiki 页面的信息不够详细,LLM 可以回到 raw/ 去读原始文档(每篇大约 8000 字符)。但大部分情况下 L1 就够用了——因为 wiki 页面已经是编译过的精华。
这个三级缓存的精髓是什么?越常用的信息离上下文越近,越原始的信息离上下文越远。
跟 CPU 的 L1/L2/L3 缓存完全一样。index.md 是 L1 缓存(小、快、常驻),wiki 页面是 L2(中等大小、按需加载),原始文档是 L3(大、慢、很少用到)。
Karpathy 表示,在中等规模下(100 篇左右的文档,几百个 wiki 页面),这套机制"出奇地好用",不需要任何向量数据库或 embedding 基础设施。一个 index.md + grep 就够了。
qmd:当知识库规模上来之后
如果你的知识库只有几十篇文档,index.md 加 grep 完全够用。但规模上来之后呢?
上一篇我们用 qmd 的三种搜索模式(BM25 → 向量 → BM25+Rerank)串起了检索优化的完整流程。这里换个角度——qmd 不仅是搜索引擎,它也是编译知识库的天然好搭档。
它还提供了一个 MCP Server,可以直接接入 Claude Code 等 Agent——Agent 通过 MCP 协议调用 qmd 的搜索能力,就像调用一个内置工具一样。
但要注意一点:qmd 是搜索引擎,不是知识编译器。 它帮你快速找到已有的内容,但它不会帮你整合知识、建立交叉引用、维护页面一致性。编译知识库和 qmd 是互补的关系——编译知识库生产内容,qmd 帮你高效检索这些内容。
这里有一个实际的规模判断:如果你的 wiki 不到 200 个页面,index.md 常驻在 prompt 里大概 2500 字符,模型通过索引就能定位到大部分内容,不太需要额外的搜索工具。当 wiki 超过几百页之后,index.md 本身变得太长了,这时候 qmd 这样的工具就有价值了——它在索引和原始页面之间多加了一层高效检索。
编译知识库 vs RAG:什么场景用什么方案
到这里你可能想问:那 RAG 是不是可以扔了?还是说两者可以一起用?
都不是。RAG 仍有使用场景,而且大部分场景下,二者选一个就够了,关键是判断你的场景属于哪种。
直接用编译知识库的场景: 个人或小团队的知识体系,文档量不大(几十到几百篇),内容相对稳定,你需要知识持续积累和跨文档关联。比如个人研究笔记、团队内部 wiki、竞品分析库、课程知识体系。这种场景下编译知识库就够了,不需要再搭一套 RAG 管线。
直接用 RAG 的场景: 文档量大(几千几万篇),内容频繁变动,不可能也没必要全部"编译"。比如客服知识库、产品文档中心、法律法规库。这种场景下老老实实用 RAG,分块、embedding、向量搜索那一套。
不管用哪种方案,有一点要记住:wiki 的内容是 LLM 编译出来的,不是原始事实。 LLM 在整合信息的时候可能会理解偏差、遗漏关键细节、甚至引入错误的关联。所以 wiki 页面不应该被当成"最终真相"——它更像是一个高质量的索引和摘要层。当你需要精确数据或者做重要决策的时候,还是要回溯到 raw/ 里的原始文档去核实。这也是为什么三层架构里 raw/ 是只读且不可修改的——它是你永远可以回溯的 source of truth。
串一下
RAG 解决了"找到相关内容"的问题,但没解决"知识积累"和"跨文档关联"的问题。编译知识库是一种不同的思路:让 LLM 提前把原始文档"编译"成结构化的 wiki,知识在每次 ingest 时复利式增长。
三层架构——raw/(原始素材,只读)、wiki/(编译产物,LLM 维护)、schema(操作规范,人机共建)。
三个操作——Ingest(摄入新素材,触发多页面更新)、Query(在 wiki 上检索)、Lint(定期巡检矛盾和缺口)。
三级缓存——index.md 常驻 prompt(L0)、wiki 页面按需加载(L1)、原始文档必要时回溯(L2)。跟 CPU 缓存一个思路。
