
跟 Claude Code 聊了半天,告诉它"这个项目用 pnpm 不要用 npm"、"测试用 vitest 不要用 jest"、"commit message 用中文"。一切都很顺畅。
然后你关掉终端,第二天再打开,输入一个新指令——它又开始用 npm 装依赖了。
它不是故意的。它是真的不记得了。
上下文窗口就像你的工作台——台面上摆的东西你能看到、能用,但关灯离开之后,台面会被清空。第二天回来,什么都没有。
这就是为什么 Agent 需要一个记忆系统。不是什么高深的概念,就是把工作台上那些"下次还用得到"的东西,找个地方存起来,下次开工的时候再摆回去。
你需要记住什么?先搞清楚什么不用记
能从代码推导的,不存。
项目用什么技术栈?文件结构长什么样?有没有用 TypeScript?这些东西读一下 package.json 和 tsconfig.json 就知道了。存到记忆里反而有害——万一项目迁移了技术栈,旧记忆就成了误导。
能从 git 推导的,不存。
谁改了什么文件?最近一次部署是什么时候?这些用 git log 和 git blame 一查也知道了。
能从文档推导的,不存。
项目已经在 CLAUDE.md 里写了"用 pnpm 不要用 npm"?那记忆里就不需要再存一遍。重复存储不仅浪费空间,还会在两处信息不一致时造成混乱。
那什么需要存?
只存那些"只存在于对话中、无法从其他地方获取"的信息。
比如:
用户说"我是做后端的,前端不太熟"——这个信息代码里没有,git 里也没有。
用户纠正了一个行为"不要在 commit message 里加 emoji"——这是偏好,只在对话里出现过。
团队决定"下周三之前不要合并非关键 PR,移动端要切 release"——这是项目动态,代码里看不出来。
同事说"pipeline bug 都在 Linear 的 INGEST 项目里"——这是外部资源的一个引用。
Claude Code 的四种记忆类型就是这么来的:user(用户画像)、feedback(行为反馈)、project(项目动态)、reference(外部资源)。
这个背后的排除法的思路很重要。记忆系统最常见的问题不是"记得太少",而是"记得太多"——噪音把有用信息淹没了。
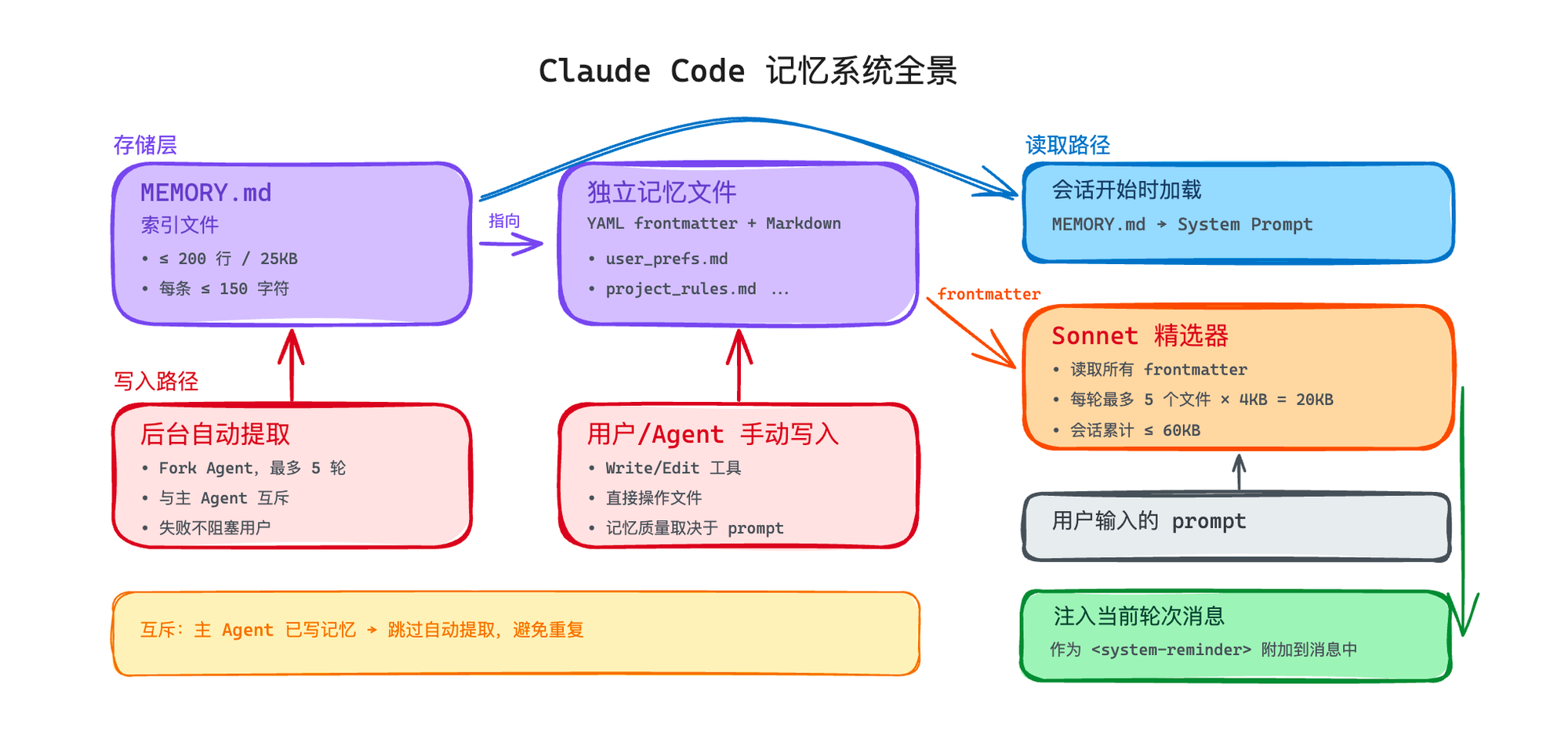
文件派:Claude Code 的 MEMORY.md
知道该记什么了,接下来聊怎么存。
Claude Code 选了一条很多人没想到的路:纯文本文件。
没有向量数据库,没有 embedding 模型,没有 SQLite,就是非常朴素的 Markdown 文件。
双层架构
Claude Code 的记忆系统是一个"索引 + 正文"的双层结构:
第一层:MEMORY.md(索引文件)
这是一个不超过 200 行的 Markdown 文件,放在 ~/.claude/projects/<项目路径>/memory/ 目录下。它的角色是目录页——每一行是一条指针,指向一个具体的记忆文件:
MARKDOWN
- [用户偏好](user_preferences.md) — 后端出身,前端不熟,偏好简洁代码
- [项目规范](project_conventions.md) — pnpm,vitest,commit 用中文
- [部署拉闸](deploy_freeze.md) — 2026-04-15 前不合并非关键 PR
每条不超过 150 个字符,一行搞定。MEMORY.md 在每次会话开始的时候会被加载到 system prompt 里——所以它必须短,不能把上下文窗口撑满。
第二层:独立记忆文件
每个记忆是一个独立的 .md 文件,带 YAML frontmatter:
MARKDOWN
---
name: 项目规范
description: 包管理器、测试框架、commit 规范等项目约定
type: feedback
---
用 pnpm 不要用 npm。
**Why:** 用户明确要求,团队统一规范。
**How to apply:** 所有 install/add 命令用 pnpm。
测试用 vitest 不要用 jest。
**Why:** 项目已配好 vitest,jest 会引入额外依赖。
frontmatter 里的 description 字段很关键——后面精选注入的时候,就是靠这个字段来判断这条记忆跟当前任务有没有关系。
200 行上限的暴力约束
MEMORY.md 有一个硬限制:200 行 或 25KB,谁先到谁算数。 超了就截断,末尾追加一条警告。
你可能觉得 200 行太少了。但这恰恰是一个很聪明的设计决策。
物理上限倒逼 Agent 只保留最重要的记忆。就像你的桌面如果只能放 10 本书,你自然会精挑细选——反过来,如果桌面无限大,你就会把什么都往上堆,最后找什么都找不到。
谁来写记忆?
这是 Claude Code 记忆系统最精妙的地方:记忆的读写完全靠 Agent 自己,用现有的 Write/Edit 工具。
没有专门的"记忆写入 API",没有特殊的存储接口。Agent 用 Write 工具创建记忆文件,用 Edit 工具更新 MEMORY.md 索引——跟写代码文件没有任何区别。
这意味着什么?
记忆的质量完全取决于 prompt 设计,而不是代码逻辑。
Claude Code 在 system prompt 里详细规定了什么该存、什么不该存、格式怎么写、怎么避免重复。Agent 按这些指令操作文件。如果记忆质量不好,调 prompt 就行,不需要改代码。
精选注入:不是全量加载,是按需挑选
200 行的 MEMORY.md 会在会话开始时加载到 system prompt 里,但那些独立的记忆文件不会全部加载。
为什么?因为如果你有 50 个记忆文件,每个 4KB,全量加载就是 200KB——上下文窗口直接吃掉一大块,还没开始干活呢。
Claude Code 的做法是:用 Sonnet 做 relevance selection,而且完全不阻塞主流程。
这里有一个很精巧的工程设计。流程是这样的:
用户输入一条消息
系统立刻提取用户的 prompt,异步发给 Sonnet——注意,是异步的,不等结果
主模型同时开始正常工作——不需要等 Sonnet 返回
Sonnet 在后台拿所有记忆文件的 frontmatter(文件名 + description + type),跟用户 prompt 做匹配
Agent Loop 每一轮迭代时轮询一下:Sonnet 返回了吗?返回了就消费结果,没返回就跳过,下一轮再看
当 Sonnet 结果到达时,挑出的记忆文件作为附件注入当前轮次的消息中
当然,实际上这里用 Haiku 也没有问题,但对于这种语义匹配的任务,Claude Code 官方会认为 Sonnet 更加合适,因此选择了 Sonnet。
你看,这又是我们前面小节强调的 JIT 加载思想——不是一开始就全量加载,而是异步预取、按需注入。而且不阻塞主流程,Sonnet 慢一点也没关系,反正主模型 Opus 先跑着。
限制也很明确:每轮最多 5 个文件 × 4KB = 20KB,整个会话累计不超过 60KB。
超过 1 天的记忆还会附带一条提示("这条记忆是 X 天前的,记忆是时间点快照,不是实时状态"),提醒模型别盲目相信旧信息。
自动提取:后台偷偷帮你记
除了用户手动让 Agent 记住什么,Claude Code 还有一个自动提取机制。
每次 query 结束后(模型的最终响应不再有工具调用时),系统会 fork 一个后台 Agent,去分析最近几轮对话,提取值得记住的信息。
这个后台 Agent 的行为被严格限制了:
只有 5 轮 工具调用预算(防止它自己跑偏)
只能读不能写代码(Read/Grep/Glob 可以,但只对记忆目录有 Edit/Write 权限)
跟主 Agent 互斥——如果主 Agent 这一轮已经手动写了记忆,自动提取就跳过,避免重复
失败了不会阻塞用户——后台跑的,静默失败,下一轮重试
这个设计非常优雅。用户完全感知不到后台在帮他记东西,但下次会话开始的时候,那些重要的信息就已经在记忆里了。
数据库派:OpenClaw 的 SQLite + 向量方案
Claude Code 的文件方案简单、透明、人类可读。但它有一个天花板:记忆量上去之后,文件检索效率不够。
你有 20 条记忆,MEMORY.md 扫一眼就知道哪条相关。你有 500 条呢?靠 Sonnet 扫 500 个 frontmatter 来挑,成本和延迟都扛不住。
而且文件方案做不了语义搜索。你问"上次部署出了什么问题",文件方案只能靠文件名和 description 里的关键词匹配。但如果记忆文件的标题是"3 月 15 日线上事故","部署"这个词根本没出现,文件方案就找不到了。
OpenClaw 走的是另一条路:**SQLite + sqlite-vec + FTS5,三位一体。**我们下面就来拆解一下这个路线。
存储架构
OpenClaw 用 SQLite 数据库存储记忆,路径在 ~/.cache/openclaw/agents/memory/<agentId>.sqlite。
数据库里有三张核心表:
chunks 表:存记忆文本和元数据(id、路径、来源、行号范围、hash、embedding)
chunks_vec 表:sqlite-vec 虚拟表,存向量索引,支持余弦距离搜索
chunks_fts 表:FTS5(SQLite 内置的全文搜索引擎)虚拟表,支持 BM25 排序——你可以理解为给记忆文本建了一个"搜索引擎"
一条记忆同时被三种方式索引——原文、向量、关键词。查询的时候,三条路都能走。
混合检索:向量 70% + 关键词 30%
这是 OpenClaw 记忆系统最核心的设计。
纯向量搜索有一个大坑:语义相似不等于任务相关。
你搜"怎么部署",向量可能返回"部署架构图"(语义近),而不是"部署命令清单"(你真正需要的)。因为 embedding 模型对专业术语和操作性内容的区分能力有限。
纯关键词搜索也有坑:同义词和自然语言表达搜不到。
你搜"上次出了什么问题",BM25 找不到"3 月 15 日线上事故",因为没有共同关键词。
OpenClaw 的解法是混合检索:
向量路径:把查询文本转成 embedding,在 chunks_vec 表里做余弦距离搜索
关键词路径:用 FTS5 的 BM25 排序做全文检索
合并:两路结果去重后,按
0.7 × 向量分 + 0.3 × 关键词分加权合并
为什么是 70/30?因为大部分情况下语义匹配比关键词匹配更准,但关键词能兜住那些向量搜不到的边缘情况。这个比例是经验值,OpenClaw 允许配置调整。
时间衰减:老记忆自动降权
记忆不是存了就一直有效的。三个月前的项目决策,大概率已经过时了。
OpenClaw 实现了一个指数衰减机制:
PLAINTEXT
衰减系数 = e^(-λ × 天数)
λ = ln(2) / 半衰期天数
什么意思呢?默认半衰期 30 天——一条记忆在 30 天后,权重降为原来的一半。也就是说,60 天后降为四分之一。
但有一个例外:MEMORY.md 等常驻文件豁免衰减。 因为这些文件通常包含的是长期有效的项目约定,不应该因为时间久就降权。
这个设计的本质假设是"新的信息通常比旧的更有用"。这个假设对大部分场景成立,但不绝对——比如公司的核心技术栈选型三年没变过,这种记忆就不该衰减。所以 OpenClaw 把衰减做成了可选的,默认关闭,按需开启。
Memory Flush:压缩之前先存档
这个设计跟之前讲过的上下文压缩有直接关系。
OpenClaw 在触发上下文压缩之前,会先跑一轮 Memory Flush——让 Agent 把当前会话中值得长期保存的信息写入记忆文件,然后再做压缩。
触发条件有两个:
软阈值:当已用 token 达到
上下文窗口 - 20000 - 4000时触发。20000 是给模型输出预留的空间(reserveTokensFloor),确保压缩后模型还有足够的 token 来生成回复;4000 是 flush 的提前量,在压缩真正触发前先把重要信息存档。举个例子,128K 的上下文窗口,当已用 token 到 104K 时就会触发 flush强制阈值:当 transcript 文件(存对话记录的文件)大小超过 2MB 时无条件触发
这解决了一个很实际的问题:压缩会丢信息。如果不在压缩前把重要信息存到长期记忆里,那些信息就真的丢了——上下文里没了,记忆里也没有。
Embedding:向量从哪来?
向量搜索的前提是你得先把文本变成向量。这就涉及一个实际问题:embedding 用谁的?
OpenClaw 在这里给了很大的选择空间——OpenAI、Gemini、Voyage、Mistral 这些云端方案都支持,也可以用 Ollama 或者 node-llama-cpp 跑本地小模型。

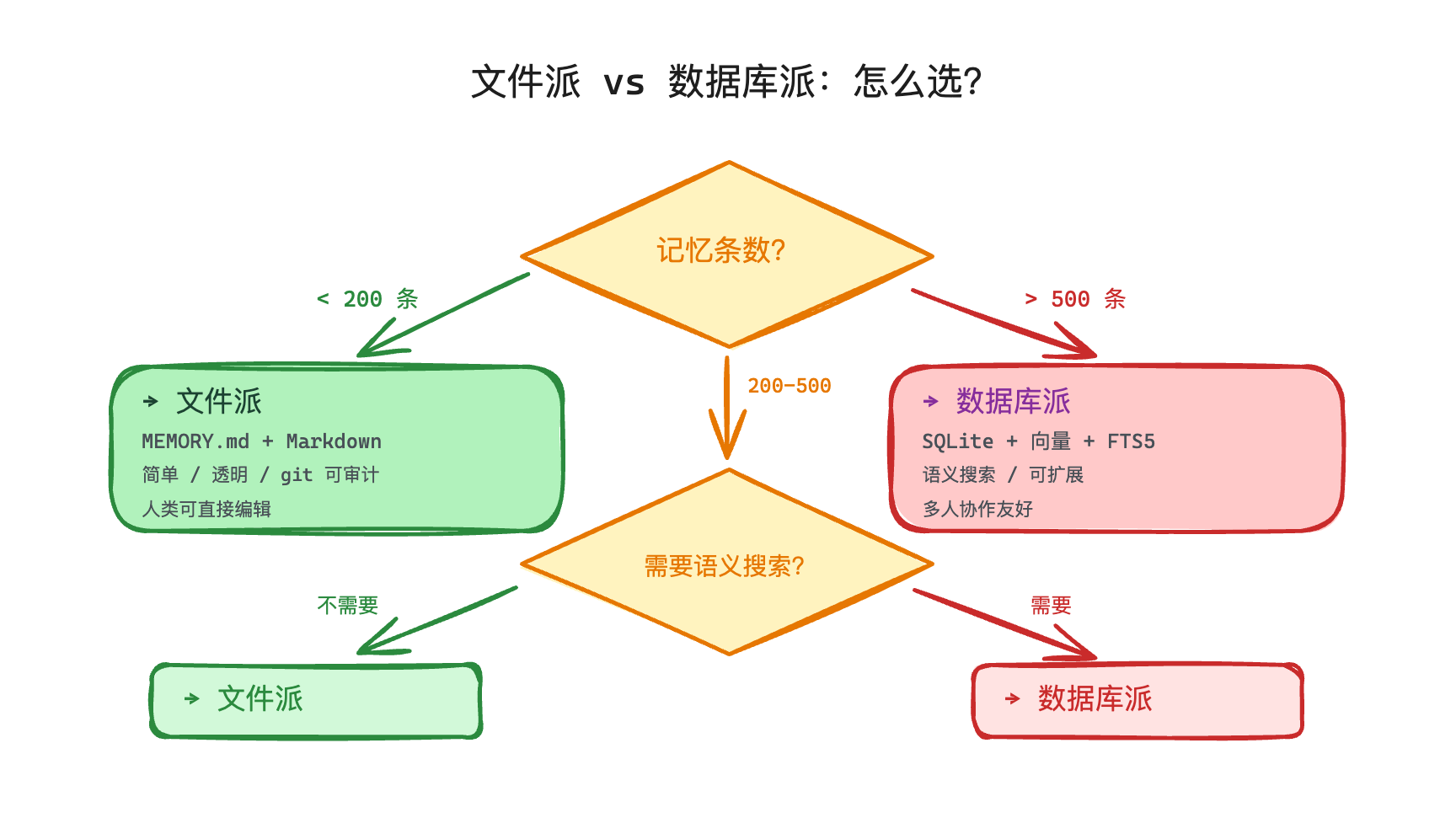
文件派 vs 数据库派:怎么选?
两种方案都讲清楚了,业界的 Agent 产品们其实对于记忆系统而言基本就分这两派。那我们回到标题的问题:谁才是正确答案?
实际上,并没有绝对的"正确答案",只有"适合你场景的答案"。
我可以给你一个简单粗暴但有用的标准:
单人用、记忆少于 200 条,走文件派。 这么做的好处是简单、透明、人可以直接编辑。Claude Code 每天几十万开发者在用,证明了这个方案在个人开发场景下完全够用。但实际上略显粗糙,很多需要语义化匹配的场景是搞不定的。
多人用、记忆超过 500 条、需要语义搜索,走数据库派。 当你的记忆量大到靠文件名已经找不到东西的时候,向量搜索就变成了刚需。
实际场景中,你可以从文件派开始,需要时再迁移。
记忆不是存了就完事
这篇聊的是记忆系统的"怎么存"和"怎么找",但还有一个同样重要的问题我们没展开:记忆会坏。
记忆污染(存了错的,后面全跟着错)、记忆爆炸(存太多,有用的被噪音淹没)、记忆过期(代码变了,记忆没跟着变)、记忆冲突(新旧矛盾,听谁的)、冷启动(新项目零记忆)——这五种失效模式每一种都能让你的 Agent 在生产环境里翻车。
总结
Agent 的记忆系统,和计算机的存储层次结构是同一个模式——快但小的放热数据,慢但大的放冷数据,中间做换入换出。
该记什么——用排除法。能从代码、git、文档推导的不存,只存那些"只存在于对话中、无法从其他地方获取"的信息。
怎么存——两条路。文件派以 Claude Code 为代表,用 MEMORY.md 索引加独立 Markdown 文件,200 行上限,Sonnet 异步精选注入,后台自动提取,简单透明,人类可直接编辑。数据库派以 OpenClaw 为代表,用 SQLite 加 sqlite-vec 加 FTS5 三管齐下,混合检索向量占七成、关键词占三成,配合时间衰减和 Memory Flush,精准可扩展,适合大规模场景。
怎么选——记忆少、单人用,文件派就够了。记忆多、需要语义搜索,数据库派更合适。拿不准的话,从文件派开始,不够再迁移,不需要过早的引入复杂度。
记忆会坏——污染、爆炸、过期、冲突、冷启动,五种失效模式我们会在下一篇篇专门拆解。这里先记住一条核心原则:记忆是线索,不完全是事实。
