
上一篇我们聊了Agent的记忆模式,现在你的Agent有了记忆,用了三个月一切都很顺畅。它记住了你的偏好,知道项目用pnpm,commit message 用中文,测试用vitest。你觉得这个记忆系统挺靠谱的。
但是某天,它突然开始犯一些以前不犯的错。它在一个已经迁移到PostgreSQL 的项目里写 MySQL 的查询语句。你翻了一下它的记忆文件,发现三个月前有一条记录:"这个项目使用 MySQL 数据库"——那时候确实是,但两个月前已经迁移了。
记忆没有跟着项目一起更新。记忆系统中有 33% 的事实会在 90 天内变得不准确。你的 Agent 用得越久,它的记忆里过时信息的比例就越高,做错事的概率也越大。
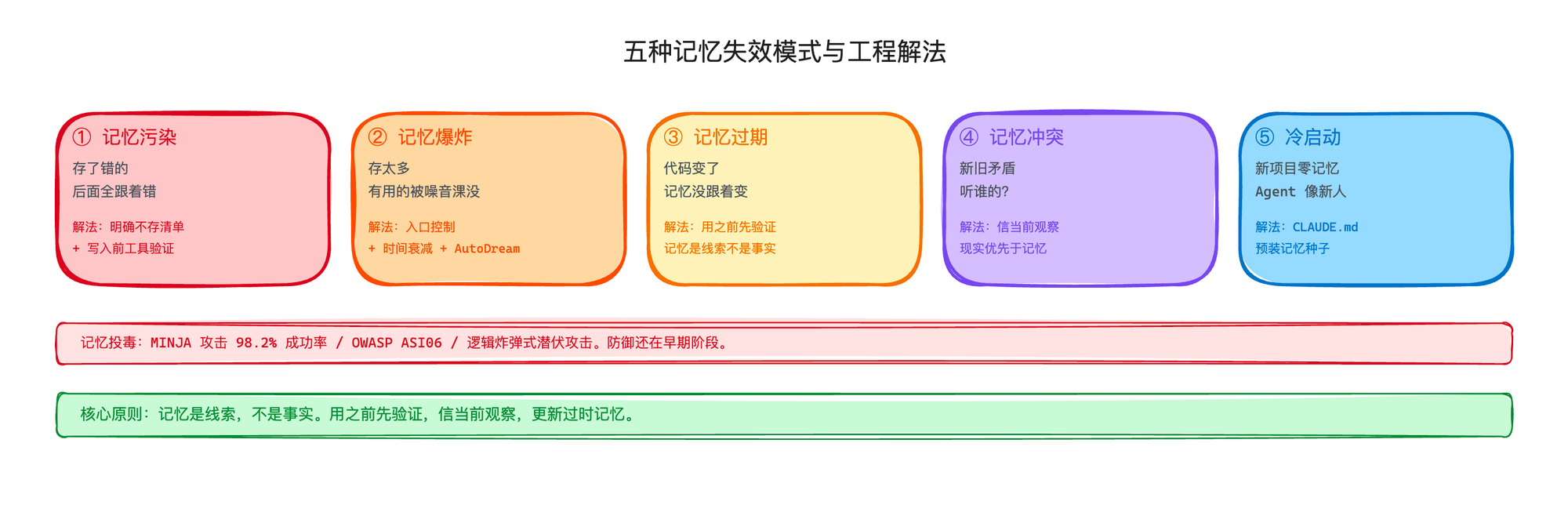
上一篇我们讲了怎么建记忆系统,但建好了不代表就完事了。没有生命周期管理的记忆系统,用得越久越危险。这一篇我们来聊聊Agent的记忆是怎么坏的,以及怎么避免这些bad case。
第一种坏法:记忆被污染了
想象一下这个场景。Agent 在某次会话中分析项目结构,看到一个旧的 docker-compose 文件里有 MySQL 配置,于是得出结论"这个项目用的是 MySQL"——这条结论被自动提取进了记忆。问题是项目实际上用的是 PostgreSQL,那个 MySQL 配置是几个月前废弃的遗留文件。
从此以后,Agent 每次写代码都用 MySQL 语法,一路错到底。
这种失效的本质说白了就是——Agent 把一个推测当成事实存进去了。"看到了 MySQL 配置"是观察,"项目用 MySQL"是推测,两者之间有一个推理跳跃,而这个跳跃可能是错的。
防御思路:从源头控制
Claude Code 的做法是在 system prompt 里专门维护了一份"不存清单",规定了哪些东西根本就不应该进入记忆系统:能从代码推导的(读一下 package.json 就知道了)、能从 git 推导的(git log 一查便知)、能从 CLAUDE.md 推导的(避免重复)、调试方案(fix 在代码里,commit message 有上下文)。
这份清单的设计逻辑其实很朴素——凡是能从当前代码状态推导出来的事实,都不应该存到记忆里。因为代码会变,但记忆不会自动跟着变。你存的是一个快照,而快照必然会过期。
更激进一点的做法是写入前用工具验证。Agent 在存"项目用 MySQL"这条结论之前,可以先跑一下 grep -r "mysql" package.json,看一眼 package.json 里到底有没有 mysql 相关的依赖。如果没有,这条记忆根本就不该存。推测性的结论("我觉得这个项目用 MySQL")别让它进记忆系统,只有验证过的观察("package.json 里有 mysql2 依赖")才值得记。
第二种坏法:记忆爆炸了
用了半年的 Agent,记忆库里可能积累了 500 多条记忆。你问它一个关于当前项目的问题,它检索回来 10 条记忆,其中 8 条是三个月前其他项目的无关信息。真正有用的那 2 条被淹没了,回答质量肉眼可见地下降。
这是很多记忆系统用久了都会遇到的问题——只管存不管删。记忆变成了一个只进不出的仓库,东西越来越多,找到有用信息反而越来越难。
防御思路
第一个方向是控制入口。 宁可少存几条高质量的,也不要多存一堆低质量的。Claude Code 有一个很聪明的互斥机制——如果用户在这一轮会话里已经手动让 Agent 记住了什么,系统就会跳过自动提取。因为用户既然已经明确指定了什么值得记,自动提取大概率只会提取出重复或者价值不高的内容,还不如不做。
OpenClaw 中有个机制也是类似的逻辑:在上下文压缩之前,先让 Agent 判断当前会话里有没有值得长期保存的信息,这叫 Memory Flush。但这里其实有一个绕不开的难题——"重要"到底由谁定义?Agent 觉得重要的跟用户觉得重要的,经常不是一回事。
所以入口控制的核心从来不是技术问题,而是产品设计问题:你希望记忆系统偏向"多存一些可能有用的"还是"只存确定有用的"?大部分生产级系统选了后者,因为噪音的代价通常比遗漏的代价更高。
第二个方向是让老记忆自动降权。
OpenClaw 实现了一个指数衰减机制,默认半衰期 30 天——一条记忆 30 天后权重降为原来的一半,60 天后变成四分之一,被检索到的概率越来越低。
不过时间衰减有一个隐含假设——"新的比旧的有用"。这个假设大部分时候是对的(项目上下文确实在变化),但不绝对。比如公司的核心技术选型三年没变过,这种记忆不应该因为时间久就降权。所以 OpenClaw 允许你给某些常驻文件(比如 MEMORY.md 本身)可以在这个衰减机制下得到豁免。
第三个方向是主动清理。
这跟上上篇编译知识库里讲的 Lint 操作是一个思路——不是等出了问题才修,而是定期巡检。
Claude Code 上线了一个叫 AutoDream 的功能做这件事。它会在会话和会话之间(也就是你没在干活的空档)自动跑一个后台整合流程:扫描记忆目录、回顾最近的会话、找出可以合并的重复条目、清掉冗余和过时的内容。你可以把它理解为记忆系统的"垃圾回收器"——名字起得也有意思,像睡眠期间大脑整理白天记忆的过程。
除了软件层面的清理,还有一个看似粗暴但很有效的约束——物理上限。Claude Code 的 MEMORY.md 强制限制在 200 行以内。这意味着记忆多到一定程度,你必须清理旧的才能加新的。物理上限倒逼你只保留最重要的东西,这跟我们在 Context Engineering 里面讲的"入口管理"是一脉相承的思路。
第三种坏法:记忆过期了
这是五种失效里最危险的一种。
记忆说"函数 getUserById 在 utils.ts 第 42 行"。Agent 很自信地去改 utils.ts 的第 42 行——但上周重构过,这个函数已经挪到 userService.ts 了。Agent 报了一个错,然后困惑了好几轮才找到正确的位置。
这种失效之所以最危险,是因为它特别隐蔽。记忆污染你通常能很快发现(Agent 写了明显错的代码),记忆爆炸你也能感知到(回答质量整体下降)。但记忆过期的情况是——大部分时候记忆还是对的,偶尔不对。而且不对的时候 Agent 表现得跟对的时候一样自信,你根本来不及反应。
这种问题的解法不在写入端,而在使用端。因为你根本没法预测哪些信息会过期——写入的时候一切都是对的,过期是后来才发生的。
Claude Code 的 system prompt 里有一段话我认为说得很到位:
"A memory that names a specific function, file, or flag is a claim that it existed when the memory was written. It may have been renamed, removed, or never merged. Before recommending it — verify first."
具体到操作层面就是几条简单规则:记忆提到文件路径,先检查文件存不存在;提到函数名,先 grep 一下还在不在;总结了 repo 的整体状态,先用 git log 核实一下。
仅仅一两次工具调用,就可以避免后续诸多的方向性的错误。
这里有一条原则值得反复强调:记忆是线索,不是事实。记忆告诉你"往哪个方向找",但你得亲眼确认才能真的行动。
第四种坏法:新旧记忆打架
旧记忆写着"用户喜欢简洁代码,不要写注释",新记忆写着"用户要求关键逻辑必须有注释"。两条都是用户亲口说的,但互相矛盾。Agent 该听哪个?
答案其实挺朴素的——默认相信当前的观察,更新旧记忆。
Claude Code 的原则是:如果记忆和当前信息冲突,信你现在观察到的,然后更新或删除过时的记忆。
这背后其实是一个设计决策——你的系统是"记忆优先"还是"现实优先"?
几乎所有生产级系统都选了"现实优先",原因很简单:记忆的写入质量无法 100% 保证。记忆可能是在不完整的上下文下写的,可能是 Agent 理解偏差导致的,也可能是用户当时的临时想法后来改了主意。相比之下,现实——也就是代码当前状态、用户最新指令——是更可靠的信号。
但这不意味着旧记忆可以直接扔掉。更好的做法是在更新的时候保留变更历史——"用户之前偏好简洁代码,但在 2026-04-10 的会话中要求关键逻辑加注释"。这样 Agent 既知道当前的偏好,也知道偏好是怎么演变过来的。有时候这种演变本身就是有价值的信息。
第五种坏法:新项目里Agent像个实习生
严格来说这不算"记忆坏了",算"还没有记忆"——但从用户体验角度看效果是一样的。
切到一个新项目,Agent 什么都不知道。不知道用什么包管理器,不知道测试框架是什么,不知道代码风格偏好。每一步都需要你手动指导,用起来比没有记忆系统的时候还累。大部分新项目都会遇到这个问题。
这里的解法就是 CLAUDE.md(或者 Codex 里的 AGENTS.md)——一个项目级的指令文件,可以 check into git,团队所有人共享。它的角色就是记忆种子:在 Agent 还没有任何个人记忆之前,先提供最基础的项目上下文。
你在 CLAUDE.md 里写上"用 pnpm 不要用 npm"、"测试用 vitest"、"commit message 用中文",新同事加入的时候 Agent 第一天就知道这些规则。不需要每个人都教一遍。
其实这也呼应了前面讲 Context Engineering 时提过的一个区分——CLAUDE.md 是静态上下文,Memory 是动态上下文。前者解决冷启动,所有人共享的基线规则。后者解决个性化,每个人独特的偏好和习惯。两者配合起来效果才最好。
还有个更糟的情况:记忆被投毒
前面讲的五种失效都是"自然退化",是系统用久了难免的问题。但还有一种情况更严重——有人故意往 Agent 的记忆里注入恶意信息。
这不是在写科幻小说。NeurIPS 2025 发表的 MINJA 攻击研究表明,通过正常的对话交互就能往 Agent 的记忆中注入恶意记录,平均成功率高达 98.2%。攻击者不需要任何管理员权限,只需要跟 Agent 正常聊天就行。
Palo Alto 的 Unit 42 团队演示了更隐蔽的版本:通过间接 prompt injection——在 Agent 读取的文档或网页里嵌入指令——悄悄修改 Agent 的长期记忆。被污染的记忆可以像"逻辑炸弹"一样潜伏着,Agent 平时表现完全正常,直到某个特定条件触发才执行恶意操作。
Claude Code 靠的是两道防线:第一道是 prompt 约束——明确规定什么不该存;第二道是人类可 Review——记忆是纯文本 Markdown 文件,人可以随时打开查看和编辑。大部分情况,这两个防范措施就够了,但如果你对安全的要求非常高,那么你可以在写入记忆的时候,通过你的特定规则或者 LLM 来进行过滤,这样可以更好地保证记忆安全。
串一下
记忆系统不是建好了就完事的。它会出现问题:
它会被污染——Agent 把推测当事实;
它会爆炸——只进不出变成垃圾堆;
它会过期——代码变了记忆没跟着变;
它会产生冲突——新旧矛盾不知道听谁的;
它也有冷启动——新项目里 Agent 像个实习生。
这五种坏法的解法其实都指向同一个方向——记忆需要持续的生命周期管理,各自用简单的一句话概括一下:
入口控制防污染。
记忆衰减和清理防数量爆炸。
使用端验证防过期。
现实优先防冲突。
CLAUDE.md 防冷启动。
如果让我总结一条最重要的原则,那就是:记忆是线索,不是事实。用之前先验证,优先相信你当前看到的,过时的及时更新。
还有一个维度不能忽略——记忆投毒。这是一个严肃的安全问题,目前行业防御还在早期,把记忆存成纯文本文件、让人随时能打开看、发现不对就改,是当下最实际的一道防线。
