
推流到一半断了怎么办?
我们在使用Agent的时候都会遇到一个问题:当你的Agent正在执行一个多步任务的时候,正在准备输出内容总结,突然这个时候出现:
PLAINTEXT
Error: 529 Overloaded这不是极端场景。任何在高峰时段调过 Claude API 或 OpenAI API 的人都见过这些状况:
429 Too Many Requests:请求频率超过了速率限制
529 Overloaded:服务端资源不足,模型过载
连接超时 / ECONNRESET:网络层面的连接中断
流式中断:SSE 推到一半,连接断了
接下来让我们说说:三个工程决策:单次失败怎么重试、重试不管用怎么降级、单个 Provider 不够用怎么做多路容灾。
第零步:错误分类
不是所有错误都值得重试。所以我们在写任何重试逻辑之前,首先要做好错误分类。429 限流和 401 密钥过期,处理方式完全不同。429 等一等就好,401 等多久都没用。
把错误分成三类:
可重试——限流(429)、服务过载(529/503)、请求超时(408)、连接被重置(ECONNRESET)。共同特征:问题出在服务端或网络,等一段时间有可能恢复。
不可重试——请求格式错误(400)、认证失败(401/403)、余额不足(402)。问题出在客户端,重试不会改变结果。
需要降级——连续多次 529、流式连接反复断开。说明问题不是偶发的,单纯重试已经不够了,需要换策略。
决策一:单次失败怎么重试?
一次 API 调用返回了 429 或 529,需要重试。核心策略是指数退避(Exponential Backoff)+ 随机抖动(Jitter)。
为什么不能固定间隔时间重试?假设你的 Agent 产品有 1000 个并发用户。某一刻 API 过载返回了 429。如果所有客户端都等 1 秒后重试——1000 个请求同时打过去,服务端瞬间又被压垮。然后再 429,再等 1 秒,再 1000 个请求……这就是重试风暴(Retry Storm),固定间隔重试在多客户端场景下几乎必然触发。
指数退避解决"等多久"——第一次等 500ms,第二次等 1s,第三次等 2s,间隔翻倍递增。随机抖动解决"别扎堆"——在退避时间基础上加一个随机偏移,把不同客户端的请求在时间轴上打散。
Claude Code 的实现里面,基础退避是 500ms,每次翻倍,最多重试 10 次(可通过环境变量 CLAUDE_CODE_MAX_RETRIES 来配置重试次数)。
Retry-After头:服务端给的答案优先
HTTP 响应里的 Retry-After 头。当服务端返回 429 或 529 时,通常会附带一个 Retry-After 头,告诉你"过多久再来"。这个值比你自己算的退避时间更准确——服务端比客户端更清楚自己什么时候能恢复。Claude Code 在重试逻辑里会解析这个头(秒数转毫秒),并优先使用它作为等待时间。
连续失败的升级机制
光有指数退避不够,还需要一个升级阈值:连续失败到一定次数,就不在同一层继续重试了。继续重试也毫无意义,白白的浪费Token。这时候控制权就交给下一层:降级策略。
流式连接卡住怎么办?
上面讨论的都是"API 返回了错误码"的情况。但生产环境中还有一种更隐蔽的故障:SSE 连接没有报错,也没有断开,但不再推送数据了。用户看到的现象是:AI 输出到一半停住了,光标还在闪,界面仍然显示"正在生成",但等多久都不会有新内容。
为什么会这样?TCP 协议有一个"半开(Half-Open)"状态。当用户的网络发生抖动(WiFi 切换、进出电梯、断网再重连),客户端的 TCP 连接可能已经失效了,但浏览器层面并不知道。reader.read() 会一直挂起等待数据,直到 TCP 层面超时——这个超时可能是几分钟甚至更长。
这期间 try-catch 捕获不到任何错误,因为没有错误发生,只是在"等"。你的重试逻辑完全不会被触发。
解法:服务端心跳+客户端看门狗
服务端:定期发送心跳。 SSE 协议支持注释行(以 : 开头的行),不会触发客户端的事件回调,但会让 reader.read() 返回数据。心跳的目的不是传递信息,而是让客户端确认连接仍然活着:
JAVASCRIPT
// 每 15 秒发一次心跳注释
const heartbeat = setInterval(() => {
res.write(': heartbeat\n\n');
}, 15_000);
一个容易犯的错误是只在连接建立初期发心跳(比如等待模型加载时),加载完就停了。实际上整个请求生命周期都需要保持心跳——模型推理、工具执行、数据库写入,这些环节都可能有数秒甚至十几秒的静默期。
客户端:看门狗定时器(Watchdog Timer)。 记录最后一次收到数据的时间,超过阈值就判定连接已失效:
JAVASCRIPT
const TIMEOUT = 30_000; // 30 秒无数据判定连接失效
let lastDataAt = Date.now();
const watchdog = setInterval(() => {
if (Date.now() - lastDataAt > TIMEOUT) {
clearInterval(watchdog);
reader.cancel(); // 中断挂起的 read()
}
}, 5_000);
while (true) {
const { done, value } = await reader.read();
if (done) break;
lastDataAt = Date.now(); // 收到任何数据(包括心跳),重置计时
// ... 解析 SSE 事件
}
clearInterval(watchdog);
reader.cancel() 是 Streams API 的标准中断方法,会让挂起的 reader.read() 立即返回 { done: true },循环正常退出,后续进入恢复流程。
两个参数的配合很关键:服务端心跳间隔(15s)必须显著小于客户端超时阈值(30s)。正常情况下客户端不会误判,而真正断网时最多 30 秒就能检测到。
你可能想到用
Promise.race([read(), timeout])来实现超时。能用,但不够干净——每次循环创建新的 Promise 和 setTimeout,超时触发后read()仍然悬挂在内存里。看门狗把"读数据"和"检测存活"的职责分开了,reader.cancel()也比 Promise 竞争更标准。
检测到中断后如何恢复?
发现连接失效只是第一步。恢复时有一个关键问题:服务端可能已经处理完了,只是响应没传回来。如果检测到中断就立刻重发请求,服务端会执行两次——已经写入数据库的消息会被写两遍,已经调用的工具会被调两遍。
正确的恢复流程是先跟持久化层对账:
等几秒,给服务端时间完成写入
从数据库拉取这条消息的最终状态
用数据库数据覆盖前端状态
如果数据库也没有记录(服务端也中断了),保留已收到的部分内容
核心原则是:服务端持久化的数据是 source of truth,前端流式接收到的只是"预览"。中断后必须以数据库为准,不能凭前端状态做决策。
整个模式总结为三步:心跳保活 → 看门狗检测 → 对账恢复。缺任何一步都会有问题——没有心跳,看门狗会在正常的长时间工具执行期间误判;没有看门狗,半开连接会让用户永久卡住;没有对账,恢复时可能产生重复数据。
决策二:重试没用,怎么降级?
Agent 的容错不是一个扁平的重试循环,而是分层的——每一层处理不同级别的故障,内层解决不了的才升级到外层。
用一个完整的场景来看这个过程:
Agent 正在用流式请求调用 Claude Opus。模型已经输出了一段分析文本和一个完整的
read_file工具调用,正在输出第二个工具调用的参数 JSON——这时 SSE 连接断了。
已接受内容的处理
此时上下文里有三样东西:一段文本、一个完整的工具调用、一个不完整的工具调用。
处理原则是按完整性区分:
完整的工具调用(JSON 已经闭合):保留,可以正常执行
不完整的工具调用(JSON 还在积累碎片):丢弃,不完整的 JSON 无法解析
用户已经看到的文本:保留,删掉反而造成更大的困惑
这里有一个需要注意的问题:流式中断后如果切换到非流式重试,非流式响应可能返回相同的工具调用。如果之前流式收到的那个完整工具调用已经开始执行了,就会执行两次。所以,重试前需要对已执行的工具调用做去重。
流式->非流式降级
重试了几次,流式请求还是失败。Claude Code 在这个环节的设计是:流式失败后降级为非流式请求。
为什么这么做有效?因为流式和非流式在服务端的资源消耗模式不同。流式需要维持长连接,对服务端的连接池和内存压力更大。切换到非流式后,变成一次性的请求-响应,对服务端更友好。
模型降级
如果非流式也连续 529 了呢?这时候应该意识到:问题不在请求方式,而在模型服务本身。 整个模型厂商的服务可能在持续过载。Claude Code 的做法是:连续 3 次 529 后,触发模型降级——从 Opus 降级到能力稍弱但可用性更高的模型。
为什么这个策略有效?因为不同模型通常有独立的服务资源和算力配额。Opus 过载不代表 Sonnet 也过载。而且同一个 API 提供商的模型共享消息格式,换模型只需要改一个 model 字段,上下文完全不需要重建。
把这几步串起来看就是一个三层降级链:
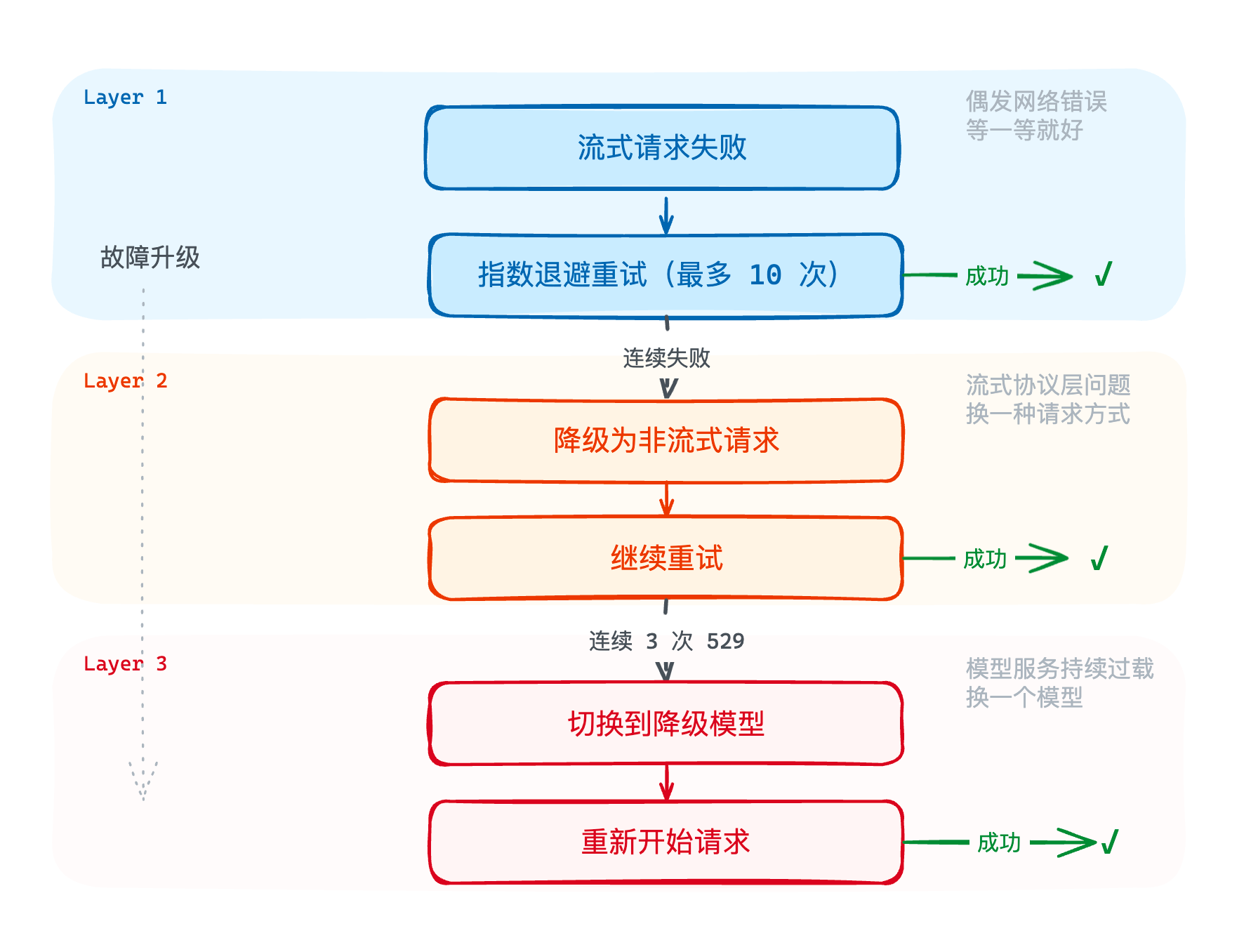
每一层只处理自己擅长的故障类型,解决不了就升级。偶发的网络错误靠重试消化,持续的流式故障靠协议降级应对,模型级别的过载靠模型切换兜底。
决策三:多Provider容灾方案
决策一和决策二说的都是单一的Provider的场景,如果你的产品同时接了多家 API 提供商,就有了更多的回旋空间。
OpenClaw 支持 Anthropic、OpenAI、Google、本地 Ollama 等多个 Provider,它的容灾设计有几个值得注意的工程决策。
临时性故障和持久化故障的区分
OpenClaw 把故障分得比"可重试/不可重试"更细:
临时性故障(rate_limit、overloaded、timeout)——冷却时间用指数退避:1 分钟 → 5 分钟 → 25 分钟,封顶 1 小时。
持久性故障(billing 402、auth_permanent 403)——走单独的"禁用"通道,退避基数直接拉到 5 小时,最长 24 小时。因为账户欠费或密钥失效不是等等就能好的,需要人工介入。
兄弟模型Failover
这是多 Provider 场景下一个很实用的设计。Agent 配置了 Claude Sonnet 4.6 作为主模型,突然 429 限流了。传统做法是等一等重试。OpenClaw 的做法是先试同 Provider 的其他模型——比如 Sonnet 4.5 或 Haiku。
原因在于:API 的速率限制通常是按模型区分的。Sonnet 4.6 达到了速率上限,不代表 Haiku 也满了。跟跨 Provider 切换相比,兄弟模型切换的成本更低——消息格式完全一致,上下文不需要任何转换。
但不是所有故障都适合走兄弟模型。只有 rate_limit 和 overloaded 这类模型级别的问题才值得切换——billing 和 auth 是 Provider 级别的问题,同一家的其他模型也一样不可用。
总结
核心原则:
1. 错误分类先于重试策略。 先把错误分成"可重试""不可重试""需要降级"三类。这个分类决定了后面所有的设计方向——429 和 401 用同一套逻辑处理是生产事故的常见来源。
2. 降级要分层,每层职责明确。 偶发网络错误靠重试,协议层问题靠降级,服务级故障靠换模型或换 Provider。不要在同一层反复死磕。
3. 沉默故障比报错更危险。 返回错误码的失败反而好处理,真正棘手的是"没有错误但也没有响应"的半开连接。心跳保活、看门狗检测、对账恢复——这套组合拳解决的就是 try-catch 捕获不到的那类故障。
