
为什么选用SSE,而不是WebSocket?
在讲 Agent 的流式架构之前,先快速讲一个底层选择:为什么所有主流 LLM API(OpenAI、Anthropic、Google)都用 SSE 做流式响应,而不是 WebSocket?
SSE 全称是 Server-Sent Events,服务器发送事件。你可以把它理解成一个单向管道——服务器往客户端推数据,客户端只管接。
WebSocket 是双向管道——两边都能发。
LLM 的流式输出,本质上就是服务器在往客户端推 token。模型生成一个 token,推一个,生成一个,推一个。客户端在这个过程中不需要往服务器发任何东西——它就是在听。
单向推送,SSE 天然适合。
而且 SSE 有几个实际工程上的优势:
跑在标准 HTTP 上。 不需要协议升级,不需要特殊的负载均衡配置,任何 HTTP 基础设施都能直接用。WebSocket 需要升级协议,很多代理和 CDN 对 WebSocket 的支持都有坑。
重连友好。 SSE 协议定义了
Last-Event-ID和重试机制,断了之后重连有据可循。WebSocket 断了就断了,重连和状态恢复逻辑得完全自己写。认证简单。 每次 SSE 请求都是标准 HTTP 请求,API Key 直接放 Header 里。WebSocket 在握手时认证一次,之后连接就是"可信"的——这在安全上有隐患。
SSE 的协议格式也非常简单。每个事件长这样:
PLAINTEXT
event: content_block_delta
data: {"type": "content_block_delta", "delta": {"text": "你好"}}
就是 event: 一行说事件类型,data: 一行放 JSON 数据,然后一个空行表示这个事件结束。就这么朴素。
模型的流式输出长什么样?
当模型在流式输出的时候,你收到的到底是什么?模型是自回归生成的——一个 token 一个 token 往外蹦。API 这边把这个过程包装成了一系列 SSE 事件。
以 Anthropic 的 API 为例,一次完整的流式响应,事件流大概长这样:
PLAINTEXT
1. message_start → 告诉你:一条新消息开始了
2. content_block_start → 告诉你:一个内容块开始了(文本块 or 工具调用块)
3. content_block_delta → 一个个 token 推过来:"你" "好" "," "我" "来" ...
4. content_block_delta → 继续推...
5. content_block_stop → 告诉你:这个内容块结束了
6. message_delta → 告诉你:整条消息的元信息(为什么停了、用了多少 token)
7. message_stop → 告诉你:整条消息结束了
如果模型只是回复一段文字,事情就这么简单。你收到一个个 content_block_delta,把文本拼起来,实时渲染给用户就行了。这就是你在 ChatGPT 或者 Claude 网页版看到的"打字机效果"的原理。
但 Agent 不只是吐文字。Agent 要调工具。
Tool Call 的流式解析:攒碎片
当模型决定调用一个工具的时候,它会输出一个 tool_use 类型的内容块。这个块里有工具名和参数(一个 JSON 对象)。但因为模型是自回归生成的——一个 token 一个 token 蹦——所以你收到的不是一个完整的 JSON,而是一堆 JSON 碎片。
实际上你收到的 SSE 事件流是这样的:
PLAINTEXT
content_block_start → {"type": "tool_use", "name": "read_file", "input": {}}
content_block_delta → partial_json: '{"file_'
content_block_delta → partial_json: 'path": "'
content_block_delta → partial_json: 'src/uti'
content_block_delta → partial_json: 'ls.ts"}'
content_block_stop → (这个工具块结束了)
看到了吗?input 字段在 content_block_start 的时候是个空对象 {}——这只是个占位符。真正的参数内容是通过后续的 input_json_delta 一片一片推过来的。
每一片都不是合法的 JSON。'{"file_' 算什么 JSON?什么都不算。你必须把所有碎片攒起来,等到 content_block_stop 事件到来时,才能拼成完整的 {"file_path": "src/utils.ts"},然后 JSON.parse() 解析。
过早解析 = 崩溃。等全部输出完再解析,确实也可以,但是太慢了。
这就引出了一个工程决策:你什么时候开始执行这个工具?
“边说边执行”:生产级Agent的标配
最简单的做法是:等模型整条消息说完,再依次执行工具。
很多早期的 Agent 实现就是这么做的。模型的流式输出结束后,拿到完整的消息,解析出所有工具调用,然后一个个执行。逻辑简单,不容易出错。但生产级 Agent 通常会做一个优化:不等整条消息说完,工具块一完成就立刻开始执行。
什么意思呢?假设模型在一次回复里要做三件事:
输出一段文字:"好的,我来帮你看一下..."
调用 Read 工具读取 src/utils.ts
调用 Read 工具读取 package.json
用一张图来对比这两种方案:
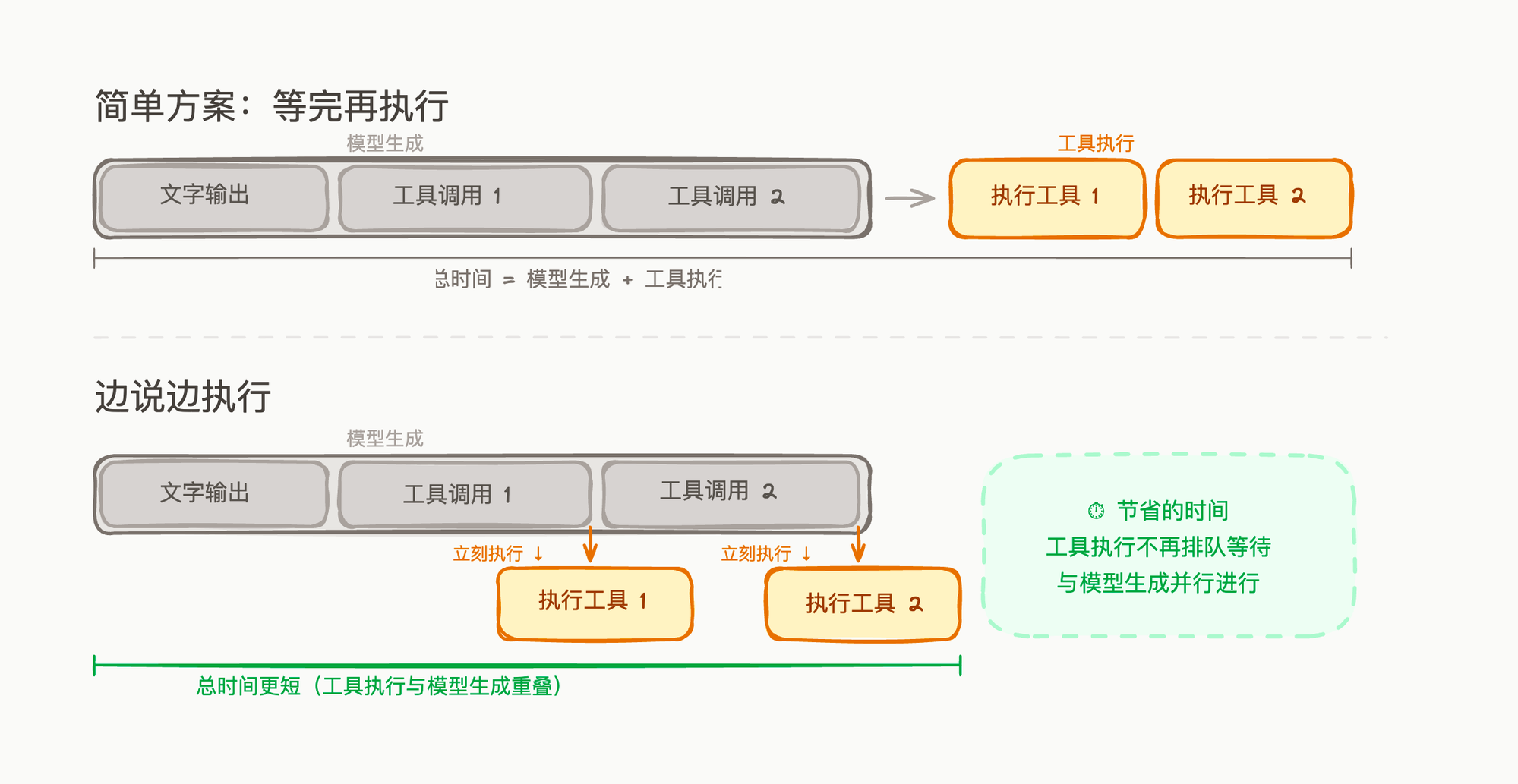
上面的"简单方案"里,模型说完所有内容,你才开始执行工具。总时间 = 模型生成时间 + 工具执行时间。
下面的"边说边执行"里,工具块一结束就立刻开始执行,跟后续的模型生成在时间上重叠。一个需要读 5 个文件的任务,感知延迟可能减少 30-50%。
不是所有的工具都能“边说边执行”
考虑这个场景。模型在一次回复里要:
调用 Read 读取 src/utils.ts
调用 Edit 修改 src/utils.ts
如果你在工具 1 读完之前就开始执行工具 2,而 Edit 的内容依赖于 Read 的结果——那就乱了。
再比如,模型同时调了两个 Edit:
Edit 修改 src/utils.ts 的第 10 行
Edit 修改 src/utils.ts 的第 20 行
如果这两个 Edit 并发执行,行号可能互相干扰——第一个 Edit 改完之后,第 20 行可能已经不是原来的第 20 行了。
所以 Claude Code 做了一个并发安全判断:每个工具、对于每一次具体的输入,判断它能不能安全地跟其他工具并发执行。
判断逻辑大致是这样的:
Read 文件:只读不写,天然安全。多个 Read 可以并发跑。
Glob / Grep:只搜索不修改,安全。可以并发。
Edit 文件:写操作。必须独占执行——等前面所有并发工具都完成了,再执行 Edit,Edit 执行期间不跑别的工具。
Bash 命令:看具体命令。
ls是安全的,rm不是。
而且这个判断不是按工具类型写死的,而是根据具体输入来决定。同样是 Bash 工具,cat README.md 可以并发,npm install 就不行。
这个设计在安全和性能之间找到了平衡。能并发的尽量并发,不能并发的坚决串行。
结果按什么顺序返回?
当多个工具并发执行的时候,结果按什么顺序返回给模型?你可能会想,谁先执行完谁先返回嘛。但 Claude Code 不是这样做的。结果按原始调用顺序返回,不是按完成顺序。
假设模型调了三个工具:Read A、Read B、Read C。B 执行最快,0.1 秒就完了;A 要 0.5 秒;C 要 0.3 秒。
完成顺序是 B → C → A。但返回给模型的顺序是 A → B → C——按模型原始调用它们的顺序。
你可能会问:顺序真的重要吗?其实从 API 协议层面来说,工具结果是通过 tool_use_id 匹配的——每个工具调用有唯一 ID,返回结果时带上对应 ID,模型靠 ID 配对,而不是靠位置。所以即使你打乱顺序,模型也不会"搞混哪个结果对应哪个调用"。
那为什么还要保持顺序?主要是工程层面的好处:保持消息流的可读性和可调试性。当你在日志里看到工具调用和结果一一对应、顺序一致时,排查问题会轻松很多。这是一个好的工程惯例,而不是协议层的硬性要求。
特殊的级联规则
有一个有意思的设计:Bash 工具的错误会取消兄弟工具,但其他工具不会。
什么意思?假设模型同时调了:
PLAINTEXT
1. Bash: mkdir -p src/components
2. Bash: touch src/components/Button.tsx
3. Read: package.json
如果工具 1 失败了(mkdir 失败),那工具 2 也会被取消——因为 touch 依赖于 mkdir 创建的目录。但工具 3(Read package.json)不会被取消,因为它跟前两个没有依赖关系。
但如果失败的不是 Bash 工具而是 Read 工具——比如读一个不存在的文件——其他工具不会被取消。因为 Read 的失败通常不影响其他工具的执行。
只有 Bash 工具的错误会级联。 这个设计是因为 shell 命令之间经常有依赖链(mkdir → cd → 创建文件),而读文件、搜索这类操作通常是独立的。
这也给我们提了个醒:有些工具的执行结果是会影响其他工具的,要注意防范这种级联影响。
OpenClaw:“边说边执行”+智能分段推送
OpenClaw 也实现了"边说边执行"——底层的 pi-agent-core SDK 在流式过程中会触发 tool_execution_start 事件,工具不用等整条消息输出完就开始执行。执行前会先把攒着的文字推出去,保证用户看到的消息不会被工具执行打断。
除此之外,OpenClaw 还在另一个地方做了很精巧的设计:流式文本的分段推送(Chunked Reply)。
什么问题呢?模型的流式输出是一个 token 一个 token 往外蹦的。如果你收到一个 token 就立刻推给前端,消息就会碎成一个个字,用户体验很差——特别是在 Slack、Discord 这种消息平台上,频繁更新消息会导致闪烁。
OpenClaw 的做法是设一个缓冲区,攒够一定量的文字后,找一个"看起来自然"的地方切一刀推出去:
最优先找段落边界——两个换行,正好是一段说完的地方;
没有段落就找句号,一句话说完也是个不错的切点;
实在找不到就在空白处切;
设了个上限(默认 800 字符),超了就强制切——哪怕在代码块中间。但不是粗暴地一刀切断,而是先把代码块关上,推出去,下一段再重新打开,保证两段的 Markdown 都能正常渲染。
这个分段逻辑在实际产品体验上差别很大。特别是当你的 Agent 需要对接 Slack、Telegram 这些第三方平台的时候——你不可能每收到一个 token 就调一次 chat.update,需要考虑 API 限流的问题。
不同提供商的流式协议差异
如果你的 Agent 需要支持多个模型提供商(很多产品都需要),还有一个坑要注意:各家的流式协议不一样。
Anthropic 用的是带 event: 类型的 SSE。每个事件都有明确的类型标签(content_block_start、content_block_delta、content_block_stop),结构清晰。
OpenAI 也用 SSE,但没有 event: 行——所有事件都是默认的 "message" 类型。你得从 data: 里的 JSON 自己判断这是什么事件。结束标记是一个特殊的 data: [DONE]。
Google Gemini 又不一样。它每个事件推的数据块更大,而且带 safetyRatings 等额外信息。
工具调用的流式格式差异更大。Anthropic 用 input_json_delta 一片一片推 JSON 碎片;OpenAI 用 tool_calls[].function.arguments 推字符串增量——本质都是 JSON 碎片,但字段路径和事件结构不同。
OpenClaw 在这块做了一个很实用的设计:对每个提供商写一个流适配器,把不同的流式协议统一成一个内部格式,上层的 Agent 逻辑只需要消费统一格式就行。
这其实就是我们上一篇讲的"API 适配层"的一个具体体现——Vercel AI SDK 也在做同样的事情,帮你抹平不同提供商的流式协议差异。

总结
核心要点:
SSE 是 LLM 流式输出的标准选择。 单向推送、标准 HTTP、自动重连——比 WebSocket 更简单也更适合。
工具调用的 JSON 参数是碎片式推送的。 你必须把所有 input_json_delta 攒完,在 content_block_stop 时才能解析。过早解析会崩溃。
"边说边执行"是生产级 Agent 的标配。 Claude Code 和 OpenClaw 都采用了这个策略。工具块一完成就开始执行,不等整条消息说完。配合并发安全判断(读操作并发、写操作串行),在安全和性能之间找到平衡。区别在于细节:Claude Code 自研了并发安全判断,OpenClaw 通过 pi-agent-core SDK 实现,并加了智能分段推送来适配 Slack、Telegram 等消息平台。
结果按调用顺序返回,不是完成顺序。 API 层面靠 tool_use_id 匹配不会混淆,但保持顺序是好的工程惯例,利于可读性和调试。
