
先说一下LangChain到底是什么?
LangChain是最近两年AI开发领域最火的框架,但真正跑在生产环境的Agent产品---Claude Code 、OpenClaw、Cursor你会发现他们它们都没用 LangChain。为什么这么火的框架却很难用在生产环境?
在AI圈刚开始发展的时候,如果你想要LLM去读一个PDF然后回答问题,你需要自己写代码把PDF解析成文本,切成小块,存到向量数据库里,然后每次用户提问的时候去检索相关块,拼成prompt,再调用API。每一步实现都需要自己来写。
Harrison Chase 就是在这个背景下做了 LangChain。他的核心设计理念是:把 LLM 应用开发中的常见步骤,封装成可组合的"链条"(Chain)。
看一个最简单的例子。假设你想做一个"读文档、回答问题"的应用:
PYTHON
# 不用框架,你得这样写(伪代码)
text = load_pdf("report.pdf")
chunks = split_text(text, chunk_size=500)
embeddings = openai.embed(chunks)
vector_db.store(embeddings)
question = "这份报告的核心结论是什么?"
relevant_chunks = vector_db.search(question, top_k=3)
prompt = f"根据以下内容回答问题:\n{relevant_chunks}\n\n问题:{question}"
answer = openai.chat(prompt)
每一步你都得自己处理:文件解析、文本切分、向量化、存储、检索、prompt 拼接、API 调用。
用 LangChain,同样的事情可以这样写:
PYTHON
# 用 LangChain
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import Chroma
loader = PyPDFLoader("report.pdf")
docs = loader.load_and_split()
vectordb = Chroma.from_documents(docs, OpenAIEmbeddings())
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(), retriever=vectordb.as_retriever())
answer = qa.run("这份报告的核心结论是什么?")
五六行代码就搞定了。你不需要自己切文本、不需要自己管向量数据库、不需要自己拼 prompt。LangChain 把这些步骤封装成了一个"链条"——RetrievalQA chain,你只需要告诉它用哪个 LLM、用哪个文档加载器、用哪个向量数据库。
这就是 LangChain 的核心理念:一切皆 Chain。 简单任务用一条链,复杂任务把多条链串起来。读文档是一条链,调工具是一条链,做推理是一条链,把它们组合起来就是一个完整的应用。
LangChain做对了什么?
第一,它降低了入门门槛。 在那个大家都不知道怎么用 LLM 做应用的年代,LangChain 给了一个开箱即用的方案。几行代码就能跑起来一个看起来还挺像样的 demo,这对于推动整个行业的 AI 应用探索,功不可没。
第二,它标准化了基本范式。 "Chain"这个概念帮很多人建立了心智模型——哦,原来 LLM 应用就是把一系列步骤串起来。虽然这个心智模型后来被证明是不完整的(后面会讲),但在早期它确实帮人理解了 LLM 应用的基本结构。
第三,它建了一个生态。 几十种向量数据库适配器、几十种模型接口、各种 Document Loader……你想接什么数据源,基本都有现成的 connector。对于做原型验证来说,这省了大量时间。
这三件事加在一起,让 LangChain 在 2023 年成了 AI 开发的"默认选择"。
但问题也恰恰出在这里。
LangChain出了什么问题?
第一个问题:“链条”模型不适合Agent
这是最本质的问题。
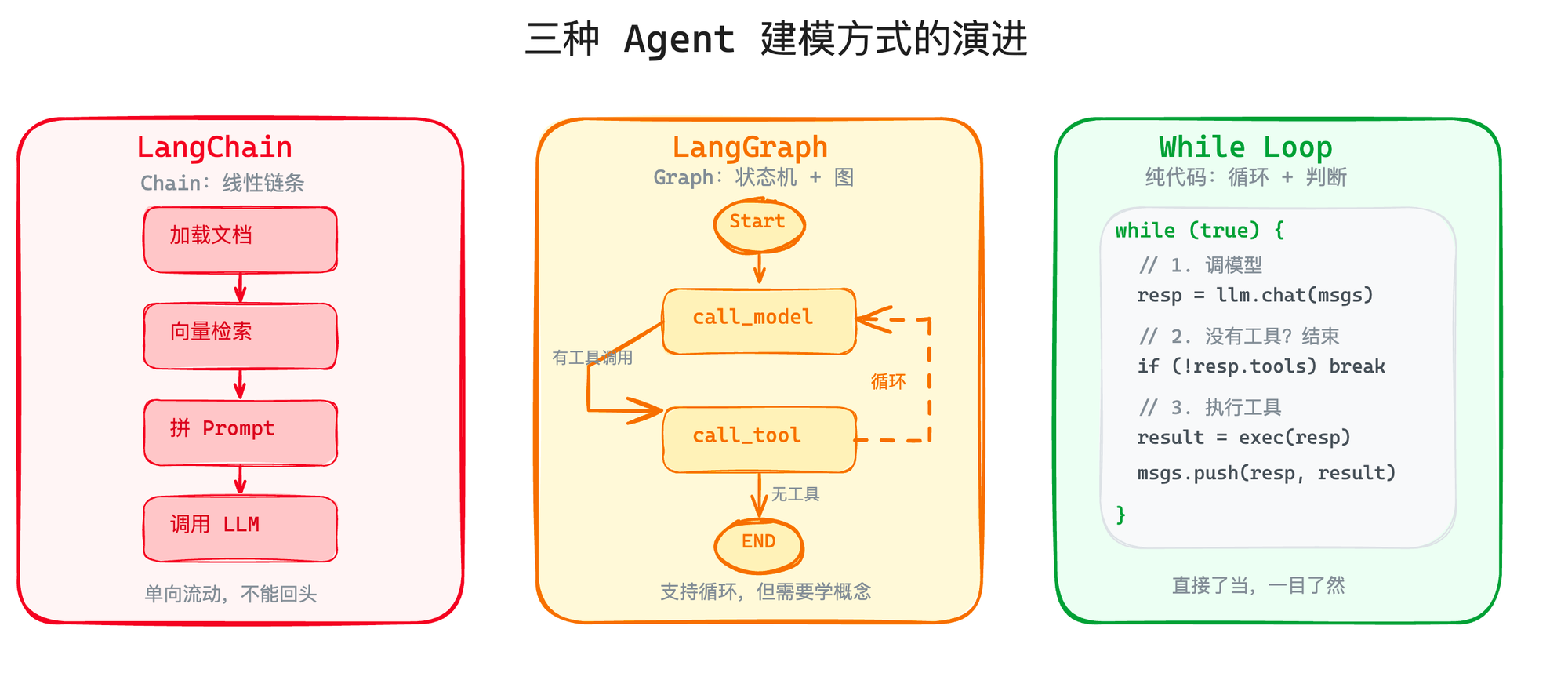
LangChain 的核心概念是"Chain"——链条。A → B → C → D,线性的、预定义的流程。你在写代码的时候就已经决定了每一步做什么。
对于 RAG(检索增强生成)这类场景,Chain 模型是合适的。因为流程确实是固定的:加载文档 → 切分 → 向量化 → 检索 → 生成。每次执行的步骤都一样,只是输入不同。
但 Agent 不是这样工作的。
Agent 的核心是 while(true) { think → act → observe }。它是一个循环,不是一条链。它不知道自己要执行几步,不知道下一步该做什么——这些都是模型实时决定的。
举个具体的例子。你让一个 Agent "帮我重构 utils.ts 里的 formatDate 函数",Agent 可能会:
先读 utils.ts 看看函数长什么样(这一步是确定的)
发现函数用了 moment.js,决定改用 dayjs(这一步是模型临时决定的)
检查 package.json 看有没有 dayjs(这一步取决于上一步的发现)
发现没有,先装 dayjs(又是一个临时决策)
改代码、跑测试、发现报错、再修……
这个过程里,每一步都取决于上一步的结果。你没法提前画好流程图,因为你不知道模型会走哪条路。
Chain 是确定性的:写代码时就定好了路线。 Agent 是非确定性的:运行时才知道下一步做什么。
用一个为链条设计的框架去构建循环驱动的系统,就像用 Coze 工作流去搭一个游戏的逻辑——能跑,但想想就非常难受。
第二个问题:抽象层太多了
LangChain 想帮你做很多事情,所以它建了很多抽象层。这在简单场景下感觉很爽——几行代码就搞定了。但一旦你的需求超出了框架提供的标准路径,问题就来了。你想改一个 prompt 模板的格式?得先理解 PromptTemplate → BasePromptTemplate → Runnable 这条继承链。你想自定义工具的错误处理?得搞清楚 BaseTool → StructuredTool → Tool 这套体系,还要理解 Callback 机制。虽然框架帮你省了写代码的时间,但你会在调试和定制的时候加倍还回来。
第三个问题:原型到生产的鸿沟
用 LangChain 搞一个 demo 确实快——半天就能跑起来一个还不错的 Agent 原型。但当你想把它上生产的时候,你会发现框架的设计目标(降低入门门槛)和生产的需求(精细控制)本身就是矛盾的:
Prompt/Context 掌控——框架会背着你往 prompt 里注入模板文本,你连模型实际收到什么都不知道,内部的 Context Engineering 策略基本让框架给你包了,你能做的很少。
错误恢复——工具失败该重试、跳过还是降级?这是业务决策,但框架只给你一个通用 error handler,给你定制的空间很小。
流式细粒度控制——LangChain 虽然能拿到事件流信息(有一个
astream_events),但要做到流式输出过程的定制,基本得绕过框架自己写,例如重试恢复的策略、流式 chunk 传输的频率控制等等。
结果就是:你一开始用LangChain搭建框架觉得很好用,到项目后期又要花很多时间把LangChain拆掉重写。框架没有帮你节省时间,反而让你走了弯路。
LangGraph:方向对了,但依然比较重
LangGraph解决了什么问题?
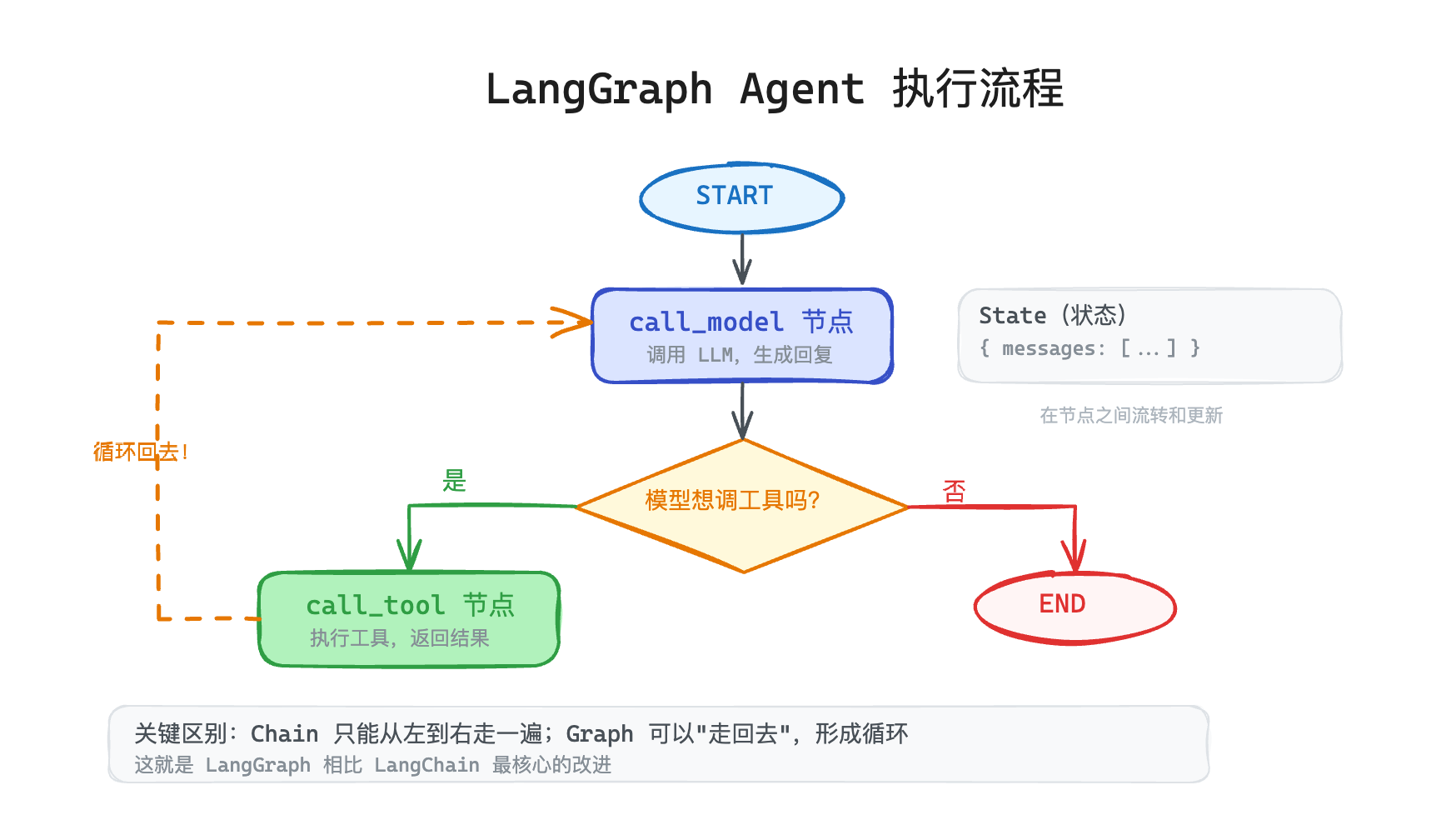
LangGraph 的核心思路是:用"图"替代"链"。
Chain 是线性的——A → B → C → D,走完就结束。但 Agent 需要循环、需要分支、需要根据结果决定下一步。图(Graph)天然支持这些。
LangGraph 把 Agent 的执行流程建模成一个状态机:
节点(Node) = 一个动作。比如"调模型"是一个节点,"执行工具"是一个节点,"检查结果"也是一个节点。
边(Edge) = 节点之间的路由。可以是无条件的(A 执行完永远走 B),也可以是有条件的(根据 A 的结果决定走 B 还是 C)。
状态(State) = 在图上流转的数据。每个节点可以读取状态、修改状态,传给下一个节点。
看一个简单的例子。假设你要做一个能调用工具的 Agent,用 LangGraph 大概长这样:
(Python 伪代码,看懂就行):
PYTHON
# 第一步:定义两个"节点"——模型和工具
def call_model(state):
response = llm.chat(state["messages"])
return {"messages": state["messages"] + [response]}
def call_tool(state):
last_msg = state["messages"][-1]
result = execute(last_msg.tool_calls)
return {"messages": state["messages"] + [result]}
# 第二步:定义"图"——节点之间怎么连
graph = StateGraph()
graph.add_node("model", call_model)
graph.add_node("tool", call_tool)
# 第三步:定义"路由"——模型输出后,走哪条路?
graph.add_conditional_edges("model",
# 如果模型想调工具 → 去 tool 节点;否则 → 结束
lambda state: "tool" if has_tool_calls(state) else "end"
)
graph.add_edge("tool", "model") # 工具执行完 → 回到模型(这就形成了循环)
# 第四步:编译成一个可运行的应用
app = graph.compile()
app.invoke({"messages": ["帮我查一下天气"]})
核心就三步:定义节点(做什么)→ 定义边(怎么连)→ 编译运行。
model → tool → model → tool → ... 这就形成了一个循环。跟 Chain 的 A → B → C → 结束 不同,图天然支持"走回去"这个操作。
而且 LangGraph 还提供了一些很实用的能力:
人工审核:工具要执行危险操作时,暂停图的执行,等人确认了再继续
子图:把一段复杂逻辑封装成子图,嵌套在主图里,跟函数调用一个道理
检查点:保存执行到某一步的完整状态,挂了可以从断点恢复
这些确实是 Agent 开发的刚需。2025 年 LangGraph 月下载量 3400 万+,一些大公司也用了起来,说明它确实解决了真实问题。
LangGraph的问题是什么?
LangGraph 的方向没问题——用图替代链来建模 Agent,思路是对的。但你有没有注意到一件事?上面那段 LangGraph 代码做的事情,用纯代码写其实就是这样:
对比一下等价的纯代码:
TYPESCRIPT
while (true) {
const response = await llm.chat(messages)
if (!response.toolCalls) break // 没有工具调用,结束
const result = await executeTool(response.toolCalls)
messages.push(response, result) // 把结果加回去,继续循环
}
十行代码不到,逻辑一目了然。你不需要理解什么是 Node、Edge、State、Conditional Edge、Checkpoint。
当然,简单场景下两者差不多。但当逻辑变复杂的时候——比如你需要流式输出、需要并发执行多个工具、需要在工具执行中途中断——框架的概念反而会碍事。因为你得先想"这个需求在图的模型里怎么表达",而不是直接想"代码怎么写"。
第二个问题:LangGraph跟LangChain生态绑定
LangGraph 虽然可以独立使用,但它的很多功能——LangSmith 可观测性、LangServe 部署、预置的 ReAct Agent 模板——都和 LangChain 生态深度绑定。一旦用了 LangGraph,你很容易把整个 LangChain 生态都带进来。
第三个问题:LangGraph解决的不是最难的问题
图编排帮你定义了"模型节点完了走工具节点,工具节点完了回模型节点"——但这个路由逻辑本身就是一个 if 判断的事。真正难的是每个节点内部:流式输出怎么做平滑、工具并发怎么控制安全性、上下文快爆了怎么压缩。这些 LangGraph 管不了,因为它在编排层,不在执行层。
什么时候适合用LangGraph?
不是说 LangGraph 没用。它有自己适合的场景,如果你要开发企业级的 Agent 应用,又不需要做深层的定制,那直接团队统一用 LangGraph 即可。如果你需要的是——精细的上下文控制、流式工具执行、自定义压缩策略、极致的性能——这些 Agent 开发里最硬核的部分,LangGraph 帮不了你太多。因为这些东西不在"图怎么编排"这个层面,而在每个节点内部的实现细节里。
做一个类比:LangGraph 帮你设计了城市的交通网络(哪些路口连哪些路口),但真正难的是每条路上的红绿灯怎么调度、出了车祸怎么应急、高峰期怎么分流。后者才是 Agent 工程的核心挑战。
好,说完了框架这条路。我们来看看另一条路——自研。
真正的Agent产品都在用什么?
讲完 LangChain 的问题,你可能会好奇:那些真正跑在生产环境的 Agent 产品,它们的技术选型是什么?
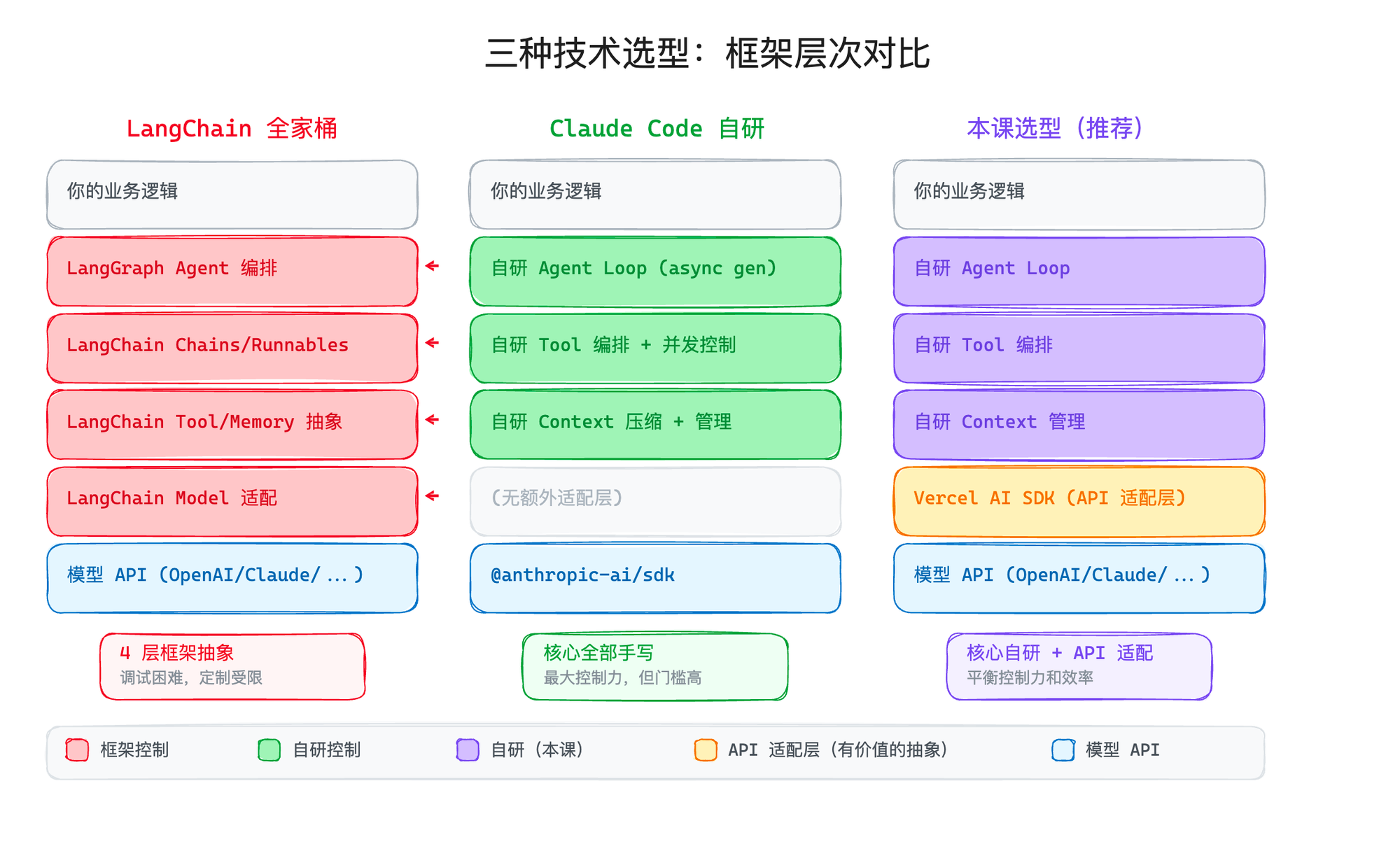
Claude Code: 纯手写,零框架
Claude Code 的 Agent 核心逻辑,没用任何外部 AI 框架。
没有 LangChain,没有 LangGraph,没有 Vercel AI SDK,什么都没有。当然,这个也跟 Anthropic 这家公司的利益相关,只能接 Claude 模型,其他模型不需要接,因此也就没有 Vercel AI SDK 抹平模型差异的需求了。
它的整个 Agent Loop——我们第二篇讲的那个 while(true) 循环——是用纯 TypeScript 手写的 async generator。
它唯一的 AI 相关依赖是 @anthropic-ai/sdk——Anthropic 自家的 API SDK。这个 SDK 做的事情很简单:帮你封装 HTTP 请求,处理流式响应的底层细节。它不管你怎么编排 Agent,不管你怎么管理上下文,不管你怎么调度工具。
工具系统也是 Claude Code 自己写的。每个工具一个独立的 TypeScript 文件,用 Zod 做参数校验。
流式执行的机制也是自己写的。模型还在输出的时候,就已经开始并发执行安全的工具了。
上下文管理同样是自己写的。三层压缩策略,每一层的触发时机和压缩方式都是针对 Agent 场景专门设计的。
为什么要这么做? 因为 Agent 的核心逻辑太需要精细控制了。
你想想,流式工具执行需要判断哪些工具可以并发、哪些必须串行——Read 可以并发跑,但 Edit 必须排队,因为两个 Edit 同时改一个文件会冲突。这个判断逻辑跟工具类型、输入参数、当前上下文都有关。有哪个通用框架能帮你做这个决策?在 LangChain 里面很难实现。
上下文压缩需要在恰好正确的时机触发——太早了会丢关键信息,太晚了模型就"爆了"。压缩时保留什么、丢弃什么,完全取决于具体业务。框架怎么可能帮你定义"什么是关键信息"?
OpenClaw:加一层薄薄的框架,核心自研
OpenClaw 的选择稍有不同。它没有完全从零开始,而是用了一个叫 pi-agent-core(也叫 Pi) 的开源库作为底层。
npm 地址: https://www.npmjs.com/package/@mariozechner/pi-agent-core
但注意,这不是 LangChain 那种大而全的框架。pi-agent-core 提供的是最基础的东西:消息格式定义、工具接口抽象、会话管理的骨架。相当于给你搭了个毛坯房,里面怎么装修完全由你决定。
而 OpenClaw 真正花功夫的地方——上下文引擎、工具策略系统、Memory 搜索——全是自研的。
特别值得说的是它的工具策略系统。OpenClaw 的工具不是简单地注册了就能用,它有一套多层策略过滤,确保每个 Agent 只能调用它被允许调用的工具。这种精细度,你觉得 LangChain 的 BaseTool 能做到吗?
Memory 也是一样。OpenClaw 用的是向量搜索 + BM25 文本搜索的混合方案,支持多种 embedding 提供商,用 SQLite 做向量存储,还有记忆随时间衰减的策略。这些都是高度贴合自身业务的设计,不可能从通用框架里"配置"出来。
一个共同的规律
越是做到生产级别的 Agent 产品,在核心逻辑上越倾向于自研。
不是因为他们有"非我发明不用"的技术洁癖,而是因为 Agent 的核心——循环控制、上下文管理、工具编排——这些东西太贴合具体场景了,通用框架的抽象反而成了障碍。
框架毫无价值了吗?
不是。关键是区分"什么时候该用"和"什么时候不该用"。
该用框架的场景:
某些标准化应用。 你要做的是一个比较标准的 RAG 应用,或者一个简单的工具调用 Agent,需求不太会偏离框架的标准路径。
团队快速对齐。 团队里大部分人没做过 Agent 开发,框架提供的结构和约定能帮大家快速上手。
不该用框架的场景:
上下文需要精细控制。 Agent 跑了 50 轮,上下文快爆了,你需要决定压缩什么、保留什么。这种决策高度依赖业务,框架帮不了你。
性能敏感。 框架的抽象层带来的额外开销,在延迟敏感的场景下不可接受。
工具编排逻辑复杂。 并发控制、权限管理、错误恢复——这些一旦复杂起来,框架的标准接口就不够用了。
你需要能快速定位问题。 生产环境出了 bug,你得能在几分钟内找到根因。Agent 逻辑埋在五层框架抽象里的话,这基本不可能,用框架就等于是灾难。
有一条很粗暴但也很实际的判断标准:你在用框架省力地解决问题,还是在跟框架搏斗?如果是后者,那就该切了。
Vercel AI SDK:它不是框架
很多人把它和 LangChain 放在一起比较,但它们完全不是同一类东西。
Vercel AI SDK 不是 Agent 框架,它是 API 适配层。
什么叫 API 适配层?就是帮你抹平不同模型提供商之间的 API 差异。
你今天用 OpenAI 的 gpt-5.4,明天想换成 Anthropic 的 claude-sonnet-4-6——两家的 API 格式不一样、流式协议不一样、工具调用的参数结构也不一样。如果你直接对接原生 API,换一个提供商就得改一大堆代码。
Vercel AI SDK 帮你做的就是这件事:统一的接口,底下自动适配不同的提供商。你换模型只需要改一行代码,Agent 的核心逻辑完全不用动。
除此之外,它还做了两件有价值的事:处理流式响应的底层细节(SSE 解析、流转发),以及提供前端 UI 组件(React/Svelte/Vue 的流式聊天 hooks)。当然前端这个我也不推荐大家用它的 UI 组件,不如自己来处理 SSE 前后端通信,这部分同理也是非常核心的部分,自研带来的扩展性长期而言收益很大。
注意它不做什么: 不帮你编排 Agent 循环,不帮你管理上下文,不帮你调度工具,不帮你做 Memory。
Vercel 自己说得很好:
"Building AI agents is just regular programming — use if statements, loops, or switches. Don't overthink the structure."
做 Agent 就是普通编程——用 if、用循环、用 switch。别把架构想复杂了。
这个态度我很认同。Agent 的核心逻辑就是一个 while 循环加一些条件判断,你真的不需要一个框架来帮你写 while 循环。你需要的是一个好用的 API 适配层,省掉跟各家 API 打交道的麻烦事。
API 适配层和 Agent 框架,是两个完全不同的东西。 前者是有价值的标准化(帮你屏蔽差异),后者往往是过度抽象(帮你隐藏了你不该被隐藏的逻辑)。
这也是为什么 Vercel AI SDK 能跟"自研 Agent 核心逻辑"完美共存——它管 API 层,你管 Agent 层,各司其职。
总结:
核心观点:
LangChain 是 AI 领域的 jQuery。 它在 API 还不成熟、开发者还不熟悉 LLM 的年代降低了入门门槛,功不可没。但随着模型 API 越来越好用、开发者经验越来越丰富,它的核心价值在下降。
生产级 Agent 的核心逻辑不适合用通用框架。 Claude Code 和 OpenClaw 都用行动证明了这一点。Agent 的循环控制、上下文管理、工具编排太贴合具体场景,通用抽象反而是障碍。
API 适配层 ≠ Agent 框架。 Vercel AI SDK 做前者,LangChain 试图做后者。前者是有价值的标准化,后者容易变成过度抽象。
学原理比学框架重要。 框架每年都在变,LangChain 自己都从 Chain 进化到了 Graph。但 Agent Loop 的核心——think、act、observe——从 ReAct 论文提出到现在,一直没变过。
