
Agent自身“死”了怎么处理?
在生产环境里,Agent 出问题最常见的三种方式就是:
死循环:反复调用同一个工具,做同样的事
Token 烧穿:无限续写,上下文越来越大,钱越烧越多
输出截断:模型话说到一半被截了,自己还不知道
保险丝1:工具死循环检测
先说死循环。这是 Agent 开发中最常见也最危险的问题。因为它看起来在正常工作。日志里一堆成功的工具调用,每一次都返回了正常结果。你不仔细看,根本发现不了它在原地踏步。
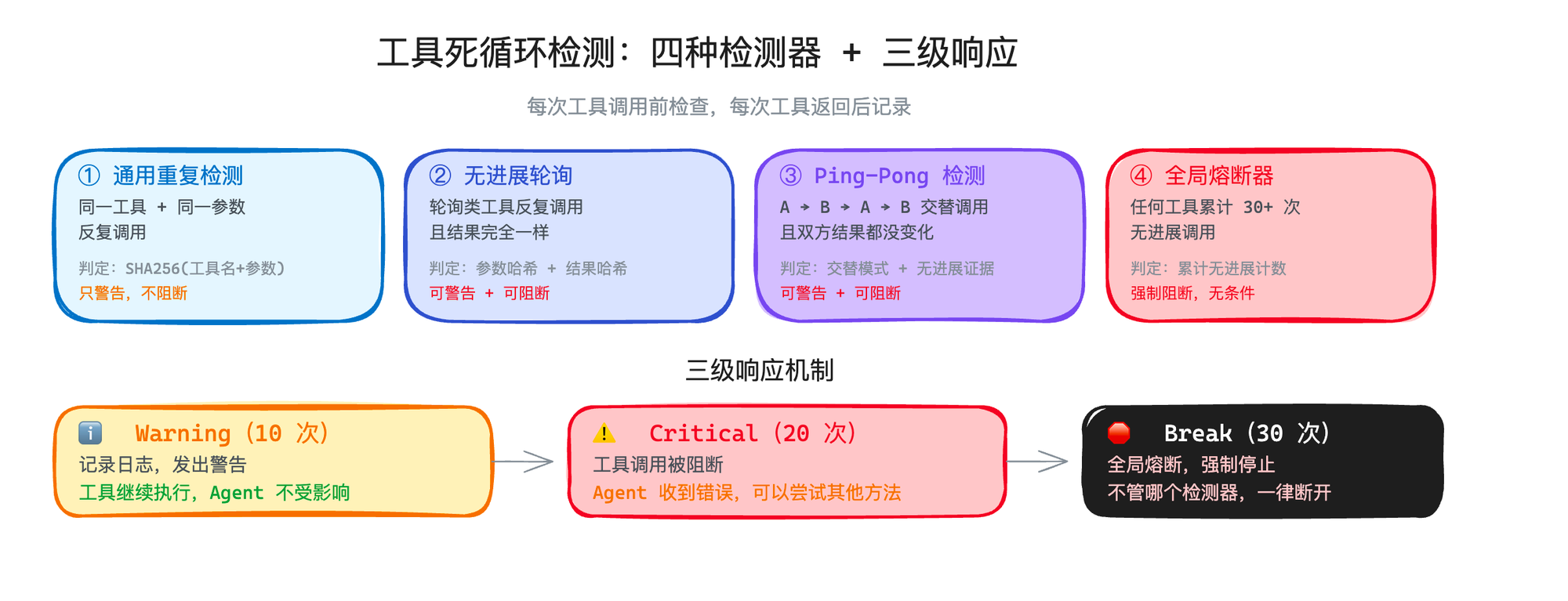
OpenClaw 在这个问题上下了很大功夫,设计了四种检测器来抓不同类型的死循环。
核心思路:“打指纹”
怎么判断一个工具调用是不是重复的?最直观的想法:比较工具名 + 参数是否一样。但参数可能是个很大的对象(比如一整个文件内容),逐字比较太慢。
OpenClaw 的做法是哈希指纹:把工具名和参数丢进 SHA256,算出一个固定长度的哈希值。两次调用的哈希值一样,就认为是同样的调用。
PLAINTEXT
指纹 = SHA256(工具名 + 稳定序列化(参数))
这里有个细节:稳定序列化。JavaScript 对象的 key 顺序是不确定的,{a: 1, b: 2} 和 {b: 2, a: 1} 序列化出来可能不一样。所以在哈希之前,要先把 key 排序,确保同样的参数一定产出同样的哈希值。
但光看参数相同还不够。同样的参数,结果可能不一样。 比如你读同一个文件 10 次,但每次读到的内容都不一样(因为有其他进程在修改),这不算死循环——每次都有新信息。
所以 OpenClaw 不光记录调用指纹,还记录结果指纹。只有「同样的调用 + 同样的结果」才被认定为无进展。
类比一个场景:你打电话给客服 10 次,每次得到的答复都是「正在处理中」——这是死循环。但如果每次得到不同的进展信息——这是正常跟进。
四种检测器
第一种:通用重复检测
最简单粗暴:同一个工具 + 同一个参数被调用了 N 次。
触发阈值是 10 次。但这个检测器只告警,不阻断。为什么不阻断?因为有些工具确实会被合法地反复调用。比如你让 Agent 处理 20 个文件,read_file 被用相同的参数调用多次可能只是因为 Agent 在不同的推理步骤需要重新读取
第二种:无进展轮训检测
专门针对轮询类的工具。什么是轮询?比如 Agent 启动了一个后台任务,然后不停地查状态,比如轮训部署状态、检查服务的健康检查——如果每次查到的状态都一样,这就是无进展的轮询。
轮询检测更多是一个防御性设计——你不一定会频繁遇到,但一旦遇到(比如模型误判某个任务没完成,反复查同一个状态),没有这根保险丝就会烧 token。
轮询检测更多是一个防御性设计——你不一定会频繁遇到,但一旦遇到(比如模型误判某个任务没完成,反复查同一个状态),没有这根保险丝就会烧 token。
第三种:Ping-Pong检测
这是最巧妙的一种。检测两个工具交替调用的模式:
PLAINTEXT
read_file → write_file → read_file → write_file → ...
检测算法是从最近的调用往回扫,看是否存在 A→B→A→B 的交替模式。关键判断条件是:两边的结果都没变化。
如果读文件每次内容不同(说明写入确实生效了),那不算——这是正常的读-改-读-改流程。只有读文件每次内容一样、写文件每次也是一样的内容,才说明 Agent 在原地打转。
第四种:全局熔断器
上面的三种情况,说白了就是无进展调用。只要累计 30 次无进展调用,强制停止,没有例外。这是最后一道防线。即便前三种检测器都被关了或者都没触发,全局熔断器永远在线。
三级响应:不是一上来就断
这四种检测器共享一套三级响应机制:
级别 | 阈值 | 行为 |
|---|---|---|
Warning | 10 次 | 记日志,工具继续执行 |
Critical | 20 次 | 阻断工具,Agent 收到错误 |
Break | 30 次 | 全局熔断,强制停止 |
为什么不在第一次重复就停?
因为误杀的代价太大。你把一个正在正常工作的 Agent 强行停了,比让它多跑几轮浪费的时间和金钱更多。所以第一级只是告警——给 Agent 一个提醒,看它能不能自己调整策略。到了 20 次,基本可以确认是死循环了,这时候才动手阻断。还有一个防刷屏的设计:告警不是每次都发的,而是每 10 次发一次。第 10 次发一个、第 20 次发一个,不会在 10 到 19 之间每次都发。
这里画了张图给你总结一下:
保险丝2:Token预算控制
死循环检测管的是工具层面的重复。但还有一种作死方式不涉及重复工具调用——模型无限续写。
你有没有遇到过这种情况:让 Agent 生成一个文档,它写了 2000 字还没停,越写越长,把整个上下文都快塞满了。这个偶然会发生,我自己也多次遇到过这种问题,如果你要做 Agent,这种问题不得不专门来防范。
Claude Code 有一个 Token 预算系统来应对这个问题。
核心逻辑:给 Agent 设一个输出 Token 预算。比如这次任务最多允许输出 30000 个 Token。系统会跟踪累计的输出 Token 数,然后做两件事:
第一件:90%时注入nudge消息
当输出量达到预算的 90% 时,系统往消息流里注入一条提醒:
"已完成 Token 目标的 87%(26,100 / 30,000)。继续工作——不要总结。"
为什么是 90% 而不是 100%?因为模型不能精确控制自己的输出长度。如果在 100% 的时候才提醒,可能已经超了。提前 10% 提醒,给模型一个缓冲区来收尾。
为什么说「不要总结」?因为模型收到「快到限制了」的信号后,本能反应就是开始总结、收尾。模型也会"慌"。
但如果任务还没完成,总结反而浪费 Token。明确告诉它「继续干活,别总结」,能更有效地利用剩余预算。
第二件:检测递减回报
如果 Agent 已经续写了 3 次以上,而且最近两次每次只增加了不到 500 个 Token——系统判定为递减回报,直接停止。
什么意思呢?就是 Agent 可能陷入了一种「每次只说一点点新东西」的模式。可能在反复润色同一段文字,或者在添加一些无关紧要的细节。每轮增量不到 500 Token,说明没有实质性进展了。
PLAINTEXT
续写第1次:+3000 Token ✓ 正常
续写第2次:+2500 Token ✓ 正常
续写第3次:+400 Token ⚠️ 增量很小
续写第4次:+300 Token ⛔ 连续两次递减,停止保险丝3:输出截断恢复
第三种作死方式更隐蔽:模型的话说到一半被截了。
每个模型都有一个 max_output_tokens 限制。Claude 默认是 8192 个 Token。如果模型要说的话超过了这个限制,输出会被硬截断。
问题是:模型自己不知道被截了。 它以为自己说完了(因为生成确实停止了),但实际上后面还有半句话没说出来。
如果这个截断发生在一个工具调用的 JSON 中间呢?JSON 不完整,解析直接失败,Agent 不知道该干什么。
Claude Code 的处理方式比较通用,分为三步递进恢复:
第一步:提高上限
默认 8K 不够?那试试 64K。这是最简单的办法——很多时候模型只是碰巧输出多了一点,把上限提高就行。这一步是静默重试,用户完全无感。
第二步:注入恢复消息
如果 64K 也不够(或者提高之后还是被截了),往消息流里注入一条指令:
"输出 Token 限制被触发了。直接从断点继续——不要道歉,不要回顾你在做什么。如果是说到一半被截了,从那个思路接着说。把剩下的工作拆成更小的块。"
这条消息设计得很精准:
「不要道歉」——模型的第一反应是「抱歉,我的回复被截断了」,这浪费 Token
「不要回顾」——模型的第二反应是把前面说的复述一遍,也浪费 Token
「从断点继续」——直接接上
「拆成更小的块」——防止下一次又被截断
这一步最多执行 3 次。
第三步:认栽
3 次恢复都不行?那就把不完整的结果返回给用户,标记为输出被截断。
为什么不无限重试?因为如果模型在 64K 的限制下连续 3 次都说不完,说明要么任务拆分有问题,要么模型在做一些不必要的展开。这时候人工介入比自动重试更有效。
Agent什么时候该停止?
七种退出路径
讲完三个保险丝,最后来看一个更大的问题:Agent 到底有哪些方式退出循环?
很多人只想到两种:任务完成了退出,或者出错了退出。但实际上,一个生产级的 Agent 至少有七种退出路径。

1.completed-正常完成
模型返回 end_turn,表示它认为任务做完了。这是最理想的退出方式。
2.max_truns-超过最大轮次
你给 Agent 设了一个上限,比如最多 20 轮。跑满了就强制停。
这个上限有两层含义:
防死循环:如果 Agent 在某种不被前面的检测器覆盖的模式下空转,max_turns 是兜底
成本控制:即便 Agent 真的在做有用的事,20 轮也够了。如果 20 轮还没完,说明任务可能需要拆分
关键设计:max_turns 的检查发生在工具执行完成后、下一轮 API 调用前。这意味着最后一轮的工具是会被执行的,不会出现「差一步就完成了但被硬停」的情况。
3.aborted_streaming-用户在流式输出时中断
用户按了 Esc 或者 Ctrl+C,或者手动退出。说明模型还在输出,被用户打断了。
处理方式:保留已经收到的文本,标记为「被用户中断」。
4.aborted_tools-用户在工具执行时中断
跟上一个类似,但发生在工具执行阶段。比如 Agent 正在跑一个 Bash 命令,用户按了 Esc。
这个更复杂一点:已经启动的工具可能还在后台运行(比如一个正在编译的进程),系统需要等工具完成或者超时后再退出。
5.hook_stopped-钩子触发停止
用户可以设置自定义 Hook:「每次 Agent 想执行工具的时候,先跑一下我的检查脚本」。如果脚本返回「不允许」,Agent 就停了。
典型场景:CI 环境里,Hook 检查代码是否通过 lint,不通过就阻止 Agent 继续。
6.bolcking_limit-上下文快满了,提前拦截
在发 API 请求之前,系统先算一下当前上下文的 token 数。如果超过了 上下文窗口 - 一定阈值,直接不发请求,立刻退出。
一定阈值的缓冲区是为了确保判断足够保守,Claude Code 里面把这个阈值设为 3000 token。为什么不发出去让 API 自己拒绝?因为那样用户要白等一个网络往返(可能几秒钟),还可能被计费。提前拦截更快更省。
7.prompt_too_long-上下文真的满了,但还有救
blocking_limit 是客户端的估算,有时候会有误差——算出来没超,发过去 API 还是返回了 413。
但这时候 Claude Code 不会直接退出,而是做两轮恢复尝试:
Context Collapse:轻量操作,把上下文中可以折叠的部分(比如很久之前已执行完的工具结果)压缩掉。
Reactive Compact:重量级操作,调用模型对早期的对话历史做摘要压缩,把几千 token 的详细记录缩成几百 token 的摘要。
两轮都试过还是太长,才真正退出。
所以 blocking_limit 和 prompt_too_long 的关系是:blocking_limit 是预检,能挡住大部分情况;prompt_too_long 是预检漏掉之后的恢复机制,带两次自救的尝试。
设计原则:每种退出都要有上下文
不管是哪种退出方式,Agent 都应该告诉用户三件事:
停了:明确表示 Agent 已经停止工作
为什么停了:是正常完成?被用户中断?达到限制?出错了?
能做什么:是否可以继续?需要调整什么参数?
没有上下文的「已停止」是用户体验灾难。用户不知道发生了什么,不知道之前的工作有没有保存,不知道下一步该怎么办。
三个保险丝协作
把三个保险丝和七种退出路径串在一起看:
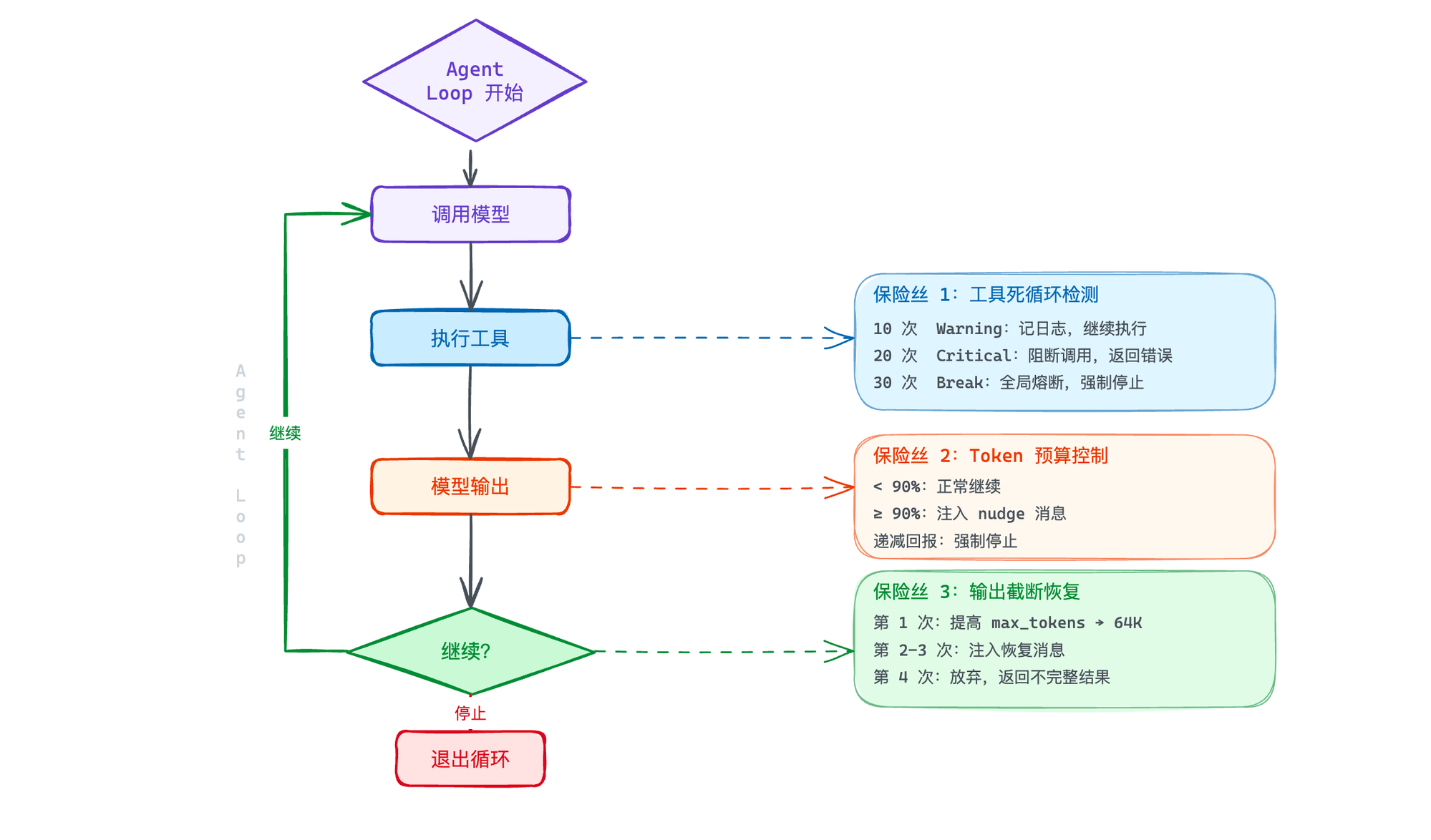
你会发现,这些保险丝不是互斥的——它们在 Agent Loop 的不同阶段分别守护不同的风险:
工具调用前:死循环检测负责
模型输出后:Token 预算负责
输出异常时:截断恢复负责
全局层面:max_turns + 上下文检查兜底
