
五个维度:一张完整的地图
Context Engineering 到底包含哪些事情?不同团队的实践不一样,但归纳起来其实就是五个维度:
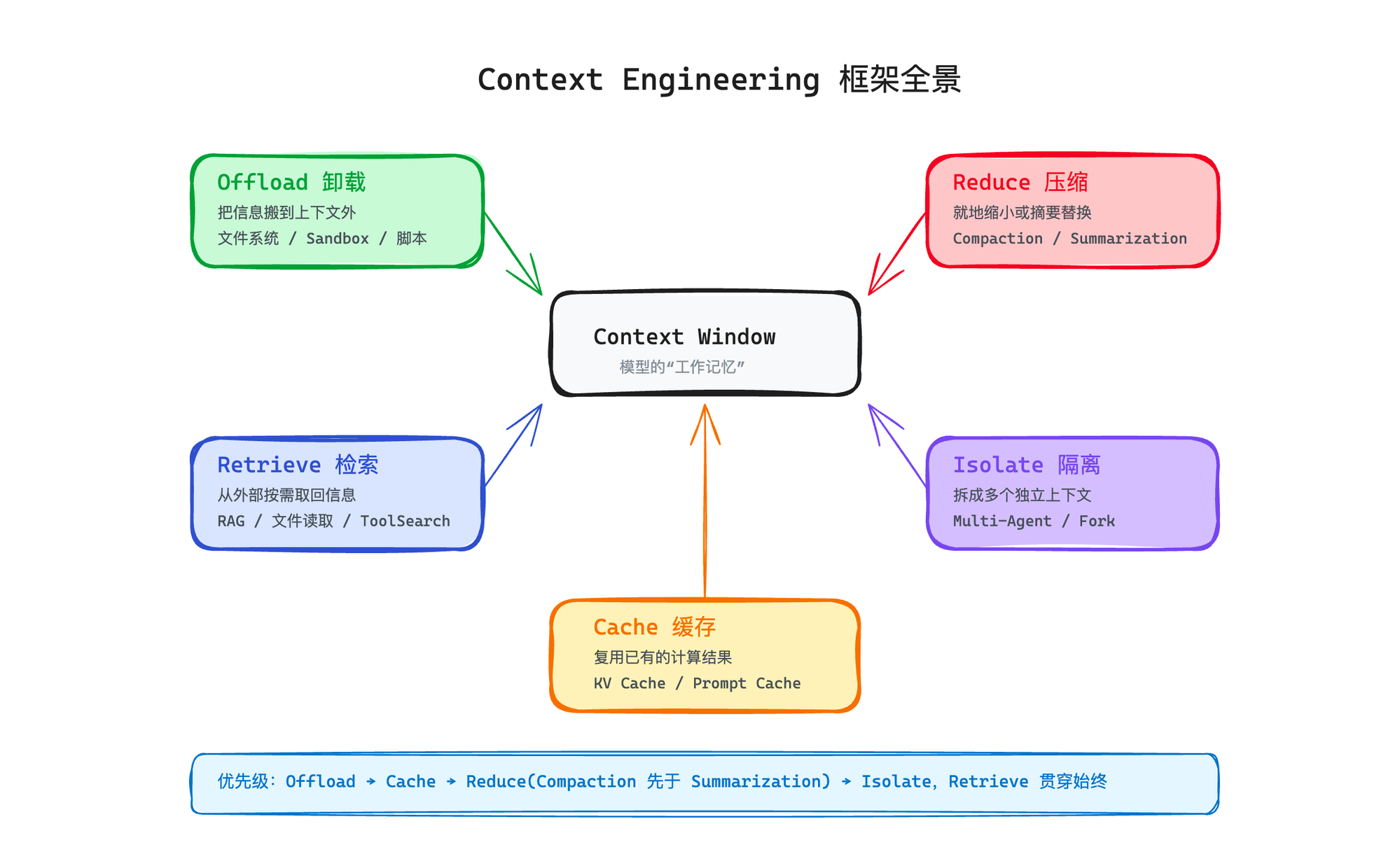
维度 | 核心问题 | 做什么 |
|---|---|---|
Offload(卸载) | 上下文太挤了 | 把信息搬到上下文之外(文件、数据库) |
Reduce(压缩) | 上下文太大了 | 就地缩小(compaction)或用摘要替换(summarization) |
Retrieve(检索) | 需要的信息不在上下文里 | 从外部按需取回(RAG、文件读取) |
Isolate(隔离) | 一个上下文装不下所有事 | 拆成多个独立的上下文(Multi-Agent) |
Cache(缓存) | 重复计算太贵了 | 复用已有的计算结果(KV Cache、Prompt Cache) |
有意思的是,行业对这五个维度并没有共识。
Offload:把信息搬到上下文之外
这个维度的核心思想是:上下文窗口是昂贵且有限的,但文件系统是廉价且无限的。
你的 Agent 读了一个 3000 token 的文件,这个结果放在上下文里。到了第 30 轮,这个文件内容大概率已经没用了,但还占着 3000 token。如果你把它写到文件系统里,上下文里只留一个引用("文件内容已存到 /tmp/auth.ts"),需要的时候再读回来,3000 token 就释放了。
这就是 Manus 说的"文件系统当外挂大脑"。不是删信息,是把信息搬到更便宜的存储介质上。
但 Manus 更进一步,把 Offloading 做成了一个三层的分级体系——不只是数据要卸载,连工具本身也要卸载:
Level 1:Function Calling
标准的工具调用,模型看到完整的工具定义(JSON Schema)然后决定调哪个。好处是安全、规范。但有两个问题:工具定义吃上下文(每个工具几百到几千 token),而且工具列表一变就破坏 Cache。
Level 2:Sandbox Utilities
模型不通过 Function Calling 来调工具,而是直接在 sandbox 里跑 shell 命令。比如要查一个文件,不用定义 read_file 工具,直接 cat /path/to/file。要安装一个包的场景,直接 pip install xxx。
好处是不碰模型的上下文——shell 命令不需要工具定义,新增能力不需要改工具列表,Cache 稳定。而且大输出可以直接写文件,不进上下文。Manus 的每个会话跑在独立的 VM sandbox 里,所以模型可以安全地 sudo 执行命令。
Level 3:Packages & APIs
最极端的卸载方式——模型不直接做数据密集型操作,而是写一段 Python 脚本来做。比如要查 20 个城市的天气,不是模型调 20 次天气 API(每次结果都进上下文),而是模型写一段脚本:取城市列表、循环调 API、汇总结果、写到文件。
整个过程上下文里只有"我写了一段脚本"和"脚本执行完了,结果在 /tmp/weather.json",中间的过程由机器来执行,跟模型无关。
核心原则:上下文留给推理,数据操作交给代码。
这三层每一层都在做同一件事:把不必要的信息从模型上下文里搬出去。
Reduce:就地压缩
上下文已经满了,Offload 来不及了,怎么办?就地压缩。
这里有一个重要的区分,很多人容易混淆:Compaction 和 Summarization 是两种完全不同的策略。
Compaction(紧凑化):不改对话结构,只缩小内容。比如把老旧的工具结果替换成一个占位符("[Old tool result cleared]"),或者把工具调用的参数缩短(去掉 content 字段,只留 path)。消息还在,结构不变,只是每条消息变小了。
Summarization(摘要化):用一段摘要替换整段对话历史。消息结构被破坏了,取而代之的是一段 LLM 生成的总结文字。信息损失更大,但 token 回收也更多。
Compaction 是可逆的(文件还在文件系统里,需要的时候读回来),Summarization 是不可逆的(原始对话永久丢失)。
Retrieve:按需检索
上下文里没有模型需要的信息,怎么办?从外部取回来。
这个维度跟 RAG 直接相关,也跟Deferred Tool Loading 相关——模型发现需要一个工具的完整 Schema,通过 ToolSearch 把它检索回来。
Retrieve 的关键挑战不是"能不能取到",而是"取回来的东西有没有用"。
Isolate:上下文隔离
一个上下文装不下所有事的时候怎么办?拆成多个。
这本质上就是 Multi-Agent,但从 Context Engineering 的角度看,它是一种上下文管理策略,不只是"多个 Agent 协作"。
对于多 Agent 场景,有两种上下文的隔离模式:
By communicating(消息传递):主 Agent 给子 Agent 发一条指令("帮我分析这个文件的安全风险"),子 Agent 有自己完全独立的上下文,完成后只把结果返回给主 Agent。主 Agent 的上下文里只多了一条指令和一个结果,而不是子 Agent 的整个思考过程。
By sharing context(Fork):子 Agent 直接复制主 Agent 的完整上下文,在此基础上继续工作。好处是子 Agent 拥有完整的历史信息,不需要重新解释背景。坏处是上下文被复制了一份,token 开销翻倍。
Claude Code 两种都用——子 Agent 走"by communicating"模式(独立上下文),Auto-Compact 的摘要生成走 Fork 模式(需要看到完整对话历史才能做摘要)。
Cache:复用计算结果
同样的 system prompt 每轮都要发,同样的对话历史每轮都在增长——这些重复的内容有没有办法不重新计算?
Cache 分三层:KV Cache(模型推理层,你管不了)、Prompt Cache(API 层,ROI 最高)、Context Collapse(应用层,可逆折叠)。
这五个维度的优先级
如果你在做自己的 Agent 产品,这五个维度的优先级大致是:
先 Offload——能不放进上下文的就不放。工具结果写文件、比较大的输出存磁盘、数据操作使用脚本完成。
再 Cache——减少重复计算。静态 prompt 缓存、对话历史前缀匹配。
然后 Reduce——先 Compaction(缩小但保留结构),实在不行再 Summarization(摘要替换)。
需要的话 Isolate——一个 Agent 搞不定就拆成多个,每个有自己的上下文。
贯穿始终 Retrieve——模型需要什么信息就按需取,不要预加载。
从轻到重,能用简单手段解决的就不上复杂方案。
