
我们已经讲过了MCP 的工程真相——标准化协议是好事,但 Token 占用、安全风险、复杂度这三个硬伤让它在很多场景下并不是最优解。那有没有更简单的方式让 Agent 获得新能力?有——Skill。
从一个真实使用场景说起
比如现在你想让 Claude Code 会用 Remotion 做视频。如果走 MCP 的路子:你得找一个 Remotion MCP Server、配置 JSON、启动进程、处理工具注册。Server 暴露的工具定义吃掉几千 token,模型还不一定知道怎么用——因为训练数据里没见过这些 MCP 工具。
如果走 Skills 的路子:
BASH
npx skills add remotion-dev/skills一行命令就完事。装完之后,你的项目目录下多了一个 .claude/skills/remotion/SKILL.md 文件。这个文件告诉 Claude Code:"你现在会用 Remotion 了,这是最佳实践,这是常见坑,这是正确的项目结构。"模型读 Markdown 文件就像读代码文档一样自然——这是它训练数据里最熟悉的格式。不需要学什么新协议,不需要理解 JSON-RPC,就是读文件、然后按文件里说的做。
这就是 Skills 的核心理念:与其教模型使用新协议,不如用它最擅长的方式——读文档。
Skills 最精妙的设计:Progressive Disclosure
Skills 系统面临一个和 MCP 一样的问题:如果你装了 100 个 Skills,不可能把所有内容都塞进上下文。
MCP 的解法是延迟加载(ToolSearch)。Skills 的解法更优雅——三层渐进式加载。
Level 1:Frontmatter(永远加载,~100 token/skill)
每个 SKILL.md 开头有一段 YAML frontmatter:
YAML
---
name: remotion
description: React 视频制作最佳实践
when_to_use: 当用户需要创建、编辑或渲染视频项目时
---
Agent 启动时,只加载这三个字段。100 个 Skills 也就 10,000 token——还不到一个 MCP Server 的开销。这些信息足够模型判断"这个 Skill 跟当前任务有没有关系"。
Level 2:完整内容(按需加载)
当模型判断某个 Skill 跟当前任务相关时,才加载 SKILL.md 的完整内容——最佳实践、代码示例、常见陷阱等等。
Level 3:引用文件(再按需加载)
Skill 目录下还可以有 scripts/(可执行脚本)和 references/(参考文档)。这些文件不会主动加载,模型需要时用 Read 工具去读。
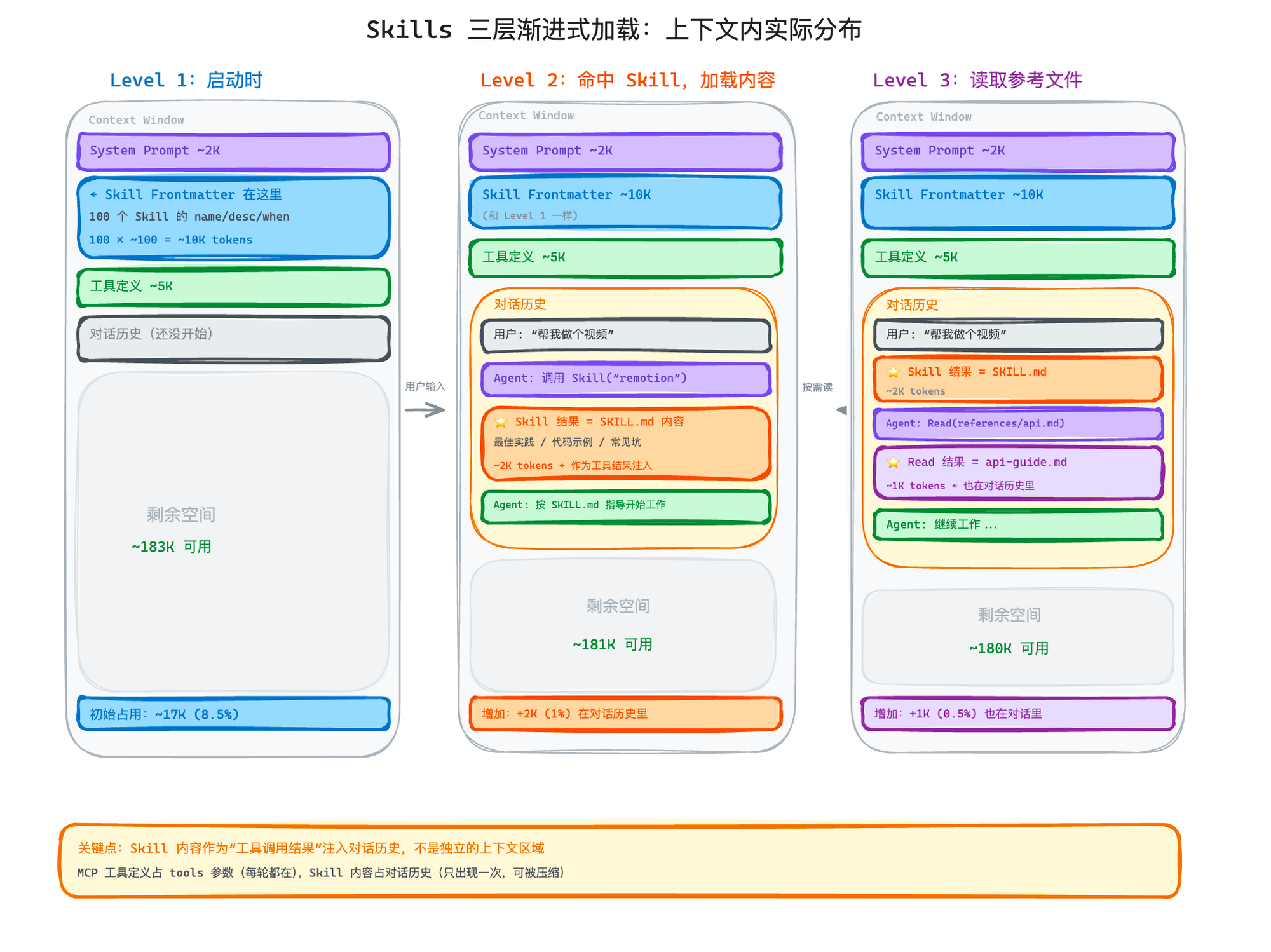
对比一下:MCP 的全量加载是"你还没开口,上下文已经满了"。Skills 的渐进式加载是"用到了才拿,用不到就不占空间"。同样接入 100 个能力,Skills 的初始 Token 消耗可能只有 MCP 的 1/50。
Claude Code 的 Skills 系统
Frontmatter:用 YAML 控制 Skill 的行为边界
SKILL.md 的 frontmatter 不只是填个名字和描述。它实际上是一套行为控制系统——决定了这个 Skill 谁能触发、在哪里跑、用什么模型、有什么权限。
举个例子你就明白了。假设你写了一个"部署到生产环境"的 Skill:
YAML
---
name: deploy-prod
description: 部署当前分支到生产环境
when_to_use: 当用户明确要求部署到生产时
allowed-tools:
- Bash(git:*)
- Bash(kubectl:*)
disable-model-invocation: true
context: fork
model: sonnet
hooks:
PreToolUse:
- matcher: Bash
hooks:
- command: "echo '即将执行: '$TOOL_INPUT' ' >&2 && exit 2"
paths:
- deploy/**
- k8s/**
---我们来拆解一下这段 frontmatter 做了什么。
allowed-tools 限定了权限边界——这个 Skill 只能用 git 和 kubectl 相关的 Bash 命令,不能乱动文件、不能调其他工具。这是最小权限原则在 Skill 层面的体现。
disable-model-invocation: true 锁死了触发方式——模型再聪明也不能自作主张触发部署,必须是用户手动输入 /deploy-prod 才行。
context: fork 隔离了执行环境——部署过程在一个独立的子 Agent 里跑,有自己的上下文窗口和 token 预算。部署的日志输出不会污染你的主对话,跑完之后只返回一个结果摘要。
model: sonnet 控制了成本——部署流程是确定性的,不需要最强的推理能力,用 Sonnet 就够了,省钱。
hooks 加了执行前的拦截——这是 Skill 级别的安全钩子,跟全局 Hook 系统打通。这里有个细节值得说一下:PreToolUse hook 是同步阻塞的,但阻不阻塞取决于 hook 脚本的退出码。
exit code 0 表示放行,工具正常执行;exit code 2 才是真正的拦截——工具调用会被阻断,hook 的 stderr 输出会作为错误信息反馈给模型。所以如果你想在部署前强制人工确认,hook 脚本得返回 exit code 2,而不是简单 echo 一句话就完事。
paths 做了条件激活——只有当你在 deploy/ 或 k8s/ 目录下工作时,这个 Skill 才会出现在模型的视野里。你写前端代码的时候,它不会冒出来干扰。
你看,一个 YAML 头部就把"谁能触发、怎么触发、在哪跑、用什么模型、有什么权限、什么时候可见"全定义清楚了。这比 MCP 的工具定义(只有参数 Schema,没有行为控制)丰富了不少。
context 动态注入
这是一个很强大的特性。SKILL.md 里可以嵌入 shell 命令,用 ! 前缀标记:
MARKDOWN
当前 Git 状态:
!`git status --short`
当前分支:
!`git branch --show-current`
Skill 被激活时,这些命令会实时执行,结果注入到 Skill 内容里。这意味着 Skill 不是一个静态的文档,而是可以动态感知环境。
加载来源与优先级
你可能会问:如果你的团队和某个外部开发者都写了一个同名的 Skill,听谁的?
Claude Code 的答案是来源决定优先级。Skill 可以来自内置的(bundled),你自己装的(.claude/skills/,项目级配置优先于全局配置)和 MCP Server 转换过来的,优先级从高到低排列。
其中一个重要的安全设计是:MCP Server 提供的 Prompt 也能被自动转成 Skill 格式加载,但它的信任等级最低——前面提到的 shell 命令执行语法就被禁掉了,原因很简单:来自远程的内容不可信。
OpenClaw 的 Skills 系统
如果说 Claude Code 的 Skills 是"简洁优雅",OpenClaw 的 Skills 就是"功能丰富"。OpenClaw 在 Skills 上做了很多 Claude Code 没做的事情。
安装配方:五种包管理器全覆盖
一个 Skill 可能依赖外部工具。比如一个 TTS Skill 需要 sherpa-onnx 二进制文件,一个浏览器 Skill 需要 playwright/agent-browser。
OpenClaw 的 SKILL.md 里可以声明"安装配方",给展示展示:
YAML
---
openclaw:
install:
- kind: brew
formula: sherpa-onnx
bins: [sherpa-onnx-offline-tts]
- kind: node
package: playwright
bins: [playwright]
- kind: go
module: github.com/example/tool@latest
- kind: uv
package: some-python-tool
- kind: download
url: https://github.com/.../release.tar.gz
extract: true
---
五种安装方式——brew、npm、go、uv(Python)、直接下载——覆盖了主流的包管理生态。系统会根据用户环境自动选择最合适的安装方式(优先 brew,fallback 到其他)。
这里有个很实际的问题解决了:Skill 不只是知识,还需要工具。你告诉模型"用 ffmpeg 处理视频",如果 ffmpeg 没装,那就啥也干不了,此时会首先安装 ffmpeg,再进入后续流程。
资格检查:这个 Skill 能不能在你这跑
不是每个 Skill 都适用于所有环境。一个 macOS 专属的 Skill 放到 Linux 上没法用,一个需要 API Key 的 Skill 没配 Key 就是摆设。
OpenClaw 的 frontmatter 支持资格声明:
YAML
---
openclaw:
os: [darwin, linux]
requires:
bins: [ffmpeg, ffprobe]
anyBins: [chromium, google-chrome]
env: [OPENAI_API_KEY]
config: [browser.enabled]
---
系统在加载 Skill 时会检查这些条件:操作系统对不对?需要的二进制文件装了没?环境变量配了没?配置项开了没?不满足条件的 Skill 直接跳过,不会出现在模型的视野里。这相当于就能实现 Skill 的按需加载,根据环境来装配对应的 Skill 内容。
这比"加载了但用不了"要好得多——模型不会浪费时间尝试一个注定会失败的 Skill。
安全扫描:Skill 里有没有危险代码
Skills 本质上可以执行脚本。如果有人写了一个恶意 Skill,里面藏了 rm -rf / 或者偷偷上传文件的代码怎么办?
OpenClaw 意识到了这个问题,它会使用 skill-scanner 工具,在安装时扫描 Skill 目录下的所有脚本文件(.js、.ts、.mjs 等),检测危险代码模式:
critical 级别:高危操作,直接警告
warn 级别:可疑模式,建议审查
info 级别:信息提示
扫描结果会在安装过程中展示给用户。如果发现 critical 级别的问题,会有明确的警告。
这解决了一个 MCP 到现在还没有好办法解决的问题——第三方扩展的代码安全审查。MCP Server 是个黑盒进程,你很难审计它内部做了什么。Skill 的脚本是明文代码,可以被扫描、被审查、被 Git 追踪。
调用策略:谁来决定何时触发
OpenClaw 的 Skill 有两种调用模式:
user-invocable(默认 true):用户可以通过
/skillName命令手动触发disable-model-invocation(默认 false):设为 true 后,模型不能自动触发,只能用户手动
这俩参数都能直接定义在 Skill.md 的 frontmatter 里面,和 Claude Code 支持的参数名都是一样的。
这个区分很重要。有些 Skill(比如"发送消息"、"执行部署")你不希望模型自作主张地触发——必须是用户明确要求才行。而有些 Skill(比如"代码风格检查"、"自动补全最佳实践")模型可以在合适的时机自动启用。
Skill 的分发生态
Skill 做得再好,如果没有分发体系,就只是"自己写自己用"。MCP 有 Smithery、mcp.run 这些第三方 Hub,Skill 生态也在快速长出自己的分发机制。
这一块 Claude Code 和 OpenClaw 走了两条不同的路,但都在回答同一个问题:怎么让一个好用的 Skill 从一个人的项目,流动到一万个人的项目?
Claude Code:Marketplace + Plugin 体系
Claude Code 的思路是搭一套 marketplace 分发体系。
用户通过 claude plugin marketplace 命令来管理 Skill 来源。你可以添加多个 marketplace 源,每个源提供一批经过审核的插件,每个插件可以包含一个或多个 Skill。
安装一个 marketplace 插件后,它的 Skill 会被放到项目目录下,走正常的加载流程。但这里有个关键的信任分级——Claude Code 区分了"official marketplace"和"third-party"来源。来自官方 marketplace 的 Skill 会被专门打上标记,在权限检查上享受不同的待遇。
这意味着什么?意味着 Claude Code 在分发层就内置了一套信任链:官方审核的 Skill 可以自动获得更高的信任等级,而第三方来源的 Skill 则需要更多的用户确认。
不过目前 Claude Code 的 marketplace 还比较早期,skills.sh(Vercel 搞的那个一行命令装 Skill 的项目,这个网址你可以直接访问)反而是社区里用得更多的分发方式——npx skills add remotion-dev/skills 这种体验确实太丝滑了。
OpenClaw:三层来源 + 跨设备能力感知
OpenClaw 的分发体系更复杂,也更有意思。社区也有了专门的 Skill 市场——ClawHub,开发者可以在上面发布和安装 OpenClaw 的 Skill。它的 Skill 有三层来源:
Bundled Skills:内置的,随 OpenClaw 一起发布,有
allowBundled配置控制启用哪些。Workspace Skills:项目目录下的
.openclaw/skills/,跟着代码仓库走。Remote Skills:从远程节点同步过来的 Skill,跨设备共享。
前两个比较好理解,第三个才是 OpenClaw 独特的地方。
你想想这个场景:你有一台 Mac 做日常开发,还有一台 Linux 服务器跑部署。Mac 上装了一堆 macOS 专属的 Skill(比如调用 say 命令做语音合成、用 Shortcuts 做自动化)。现在你想在 Linux 服务器上也能用这些能力——怎么办?
OpenClaw 的做法是通过 Gateway 节点网络。多台设备通过 WebSocket 连接到同一个 Gateway,每台设备作为一个"节点"注册自己的信息(操作系统、设备类型、支持的命令列表)。
关键来了——当一个远程节点连接上来后,OpenClaw 会做一次Remote Bin Probe,你可以理解为远程 Bin 文件探测。怎么探测?它会收集本地所有 Skill 声明需要的二进制文件(frontmatter 里的 requires.bins),然后向远程节点发一个 system.which 命令(如果远程节点支持的话),或者 fallback 到直接跑一段 shell 脚本:
BASH
for b in 'ffmpeg' 'sherpa-onnx-offline-tts' 'playwright'; do
if command -v "$b" >/dev/null 2>&1; then echo "$b"; fi
done远程节点执行完,返回它上面有哪些二进制。OpenClaw 拿到这个列表后,就知道了:这个远程节点能跑哪些 Skill。
这个信息会被缓存起来,并且在远程节点的二进制列表变化时(装了新软件、卸载了旧的),自动触发整个 Skill 列表刷新。
这就形成了一个实时能力感知与分发——不是简单地"把 Skill 文件复制过去",而是"根据目标环境的实际能力,动态决定哪些 Skill 可用"。一个需要 ffmpeg 的视频处理 Skill,如果远程节点没装 ffmpeg,它就不会出现在那个节点的可用 Skill 列表里。
安装不只是"复制文件"
不管是哪个平台,Skill 安装都不是简单的文件复制。OpenClaw 的安装流程是个值得关注的工程闭环:
第一步:下载 Skill 文件。支持从 Git 仓库、HTTP URL 等来源获取。
第二步:安全扫描。安装完文件后,立刻用 skill-scanner 扫描 Skill 目录下所有脚本文件,检测危险代码模式。扫描结果分三级:
critical:高危操作(比如删除系统文件、上传敏感数据),直接在安装结果里以 WARNING 形式呈现,告诉你具体哪个文件的哪一行有问题
warn:可疑模式,建议手动审查,提示你跑
openclaw security audit --deepinfo:信息提示,不影响安装
注意,即使有 critical 发现,安装也不会被阻断——因为有些模式可能是误报。但警告信息会非常明确地摆在你面前。
第三步:依赖安装。根据 SKILL.md 里的安装配置,调用对应的包管理器安装依赖。
第四步:二进制验证。安装完依赖后,检查需要的二进制文件是否真的可用了(hasBinary 检查)。如果不可用,会在安装结果里给出明确的失败信息。
整个流程下来,一个 Skill 从"安装"到"可用",中间经过了来源获取 → 安全审计 → 依赖安装 → 能力验证四道关卡。这才是"Skill 作为可分发的能力单元"该有的样子——不是一个松散的 Markdown 文件,而是一个自包含、自验证、安全前置的能力包。
对比一下 MCP 的安装体验:配置一段 JSON,启动一个 Server 进程,至于这个 Server 内部做了什么、安全不安全、依赖装没装——全凭运气。Skill 的分发体系虽然还在早期,但工程成熟度已经领先 MCP 生态不少了。
Skills vs MCP:本质区别
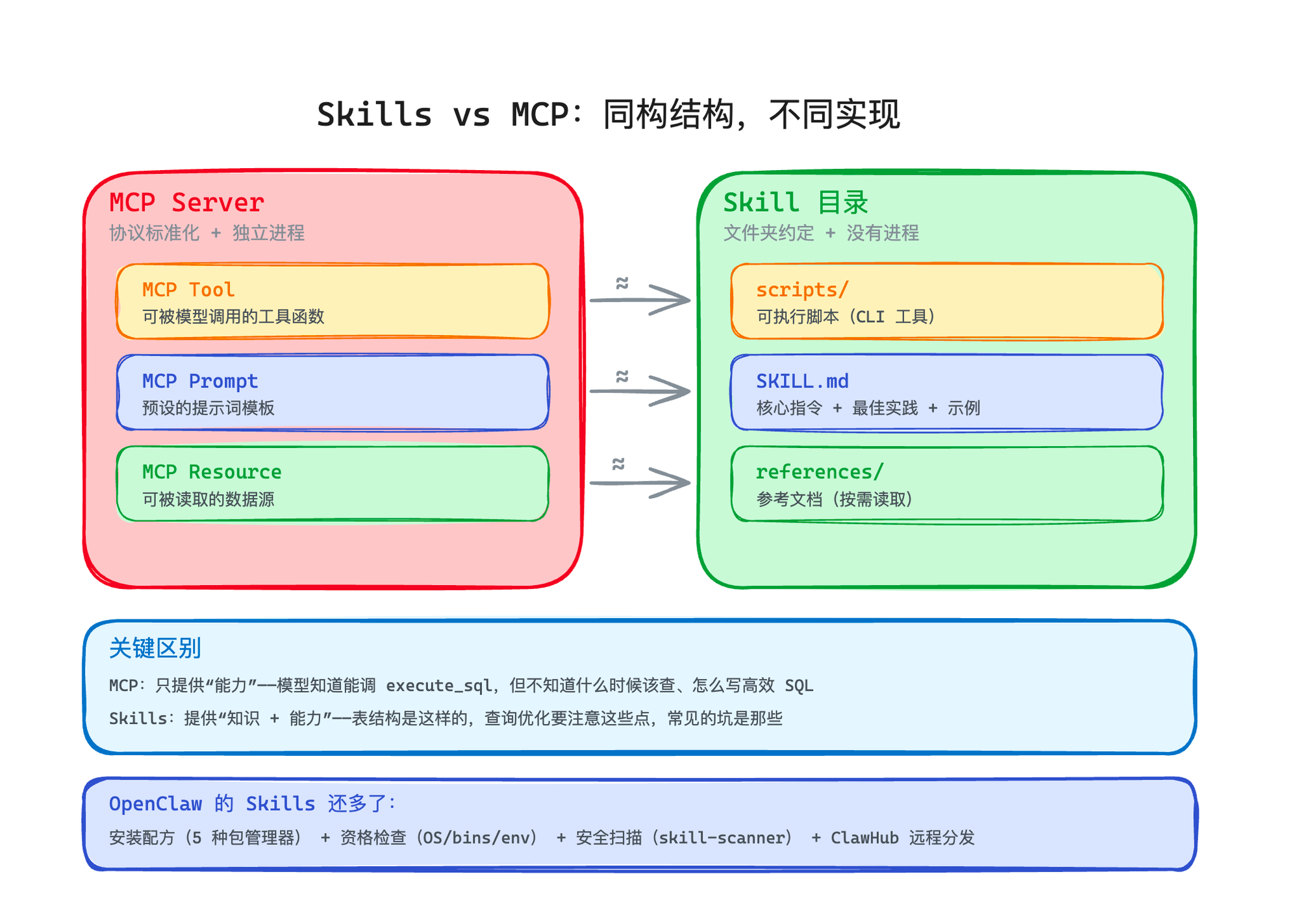
拆开来看,两者其实在解决同一个问题的不同层面:
PLAINTEXT
MCP Server Skill 目录
├── Tool (工具调用) ←→ scripts/ (可执行脚本)
├── Prompt (提示词) ←→ SKILL.md (核心指令)
└── Resource (数据源) ←→ references/ (参考文档)
结构是同构的。但实现路径完全不同:
MCP 走的是"协议标准化"——定义一套通用协议,任何客户端都能接。好处是跨平台,坏处是协议本身的开销(进程、通信、认证、Token)。
Skills 走的是"文件夹约定"——一个文件夹、一个 Markdown、几个脚本。好处是简单、轻量、模型天然会用,坏处是没有标准化的跨平台协议。
说白了,MCP 是"能力"(Capability),Skills 是"知识 + 能力"(Knowledge + Capability)。
MCP 告诉模型"你可以调 execute_sql",但不告诉它什么时候该查、怎么写高效的 SQL、哪些表结构是什么。Skills 把这些知识也一并给了——"这个项目用 Supabase,表结构是这样的,查询优化要注意这些点,常见的坑是那些"。
Skills 和 MCP 的真实关系
随着 OpenClaw 的爆火,以及 OpenClaw 作者对 Skills + CLI 模式的极力推崇,社区里有一种很流行的声音:"MCP 要被 Skills 干掉了"。说实话,这个判断太粗糙了——它忽略了一个关键变量:你的 Agent 跑在哪。
Skills 是通用的"知识层",这一点没问题。但"能力层"用什么,得看场景。
本地 Agent:Skills + CLI
如果你的 Agent 跑在用户本机(像 Claude Code、OpenClaw 这种),它有完整的文件系统、shell、包管理器。这种场景下 Skills + CLI 确实比 MCP 更合适——SKILL.md 提供知识,模型直接通过 Bash 调用 ffmpeg、kubectl、git,不需要中间加一层 MCP 协议。
大量原本用 MCP 做的事情,在本地场景下用 Skills 做更简单。你想让 AI 知道怎么用自定义组件库?以前专门搞个 MCP Server 把文档放进去,现在一个 SKILL.md 搞定。如果你想让 AI 会用某个 CLI 工具,SKILL.md 里写清楚用法,模型直接调。agent-browser 就是这个模式——一个 SKILL.md + 一个 CLI,搞定浏览器操作。
社区里 Supabase、Vercel 这些产品也在主推 Skills 的集成方式。在本地开发场景下,Skills + CLI 确实是更简洁高效的方案。
云端 Agent:Skills + MCP
而现实情况是,越来越多的 Agent 跑在云上——Web 应用里嵌的 Agent、移动端 Agent、API 服务型 Agent。这些场景下没有本地文件系统,没有 shell 可以调,CLI 这条路走不通。
Anthropic 在 2026 年 4 月发的《Building Agents That Reach Production Systems with MCP》里把这个问题说得很清楚——生产环境的 Agent 需要连接 Salesforce、Google Drive、数据库这些外部服务,MCP 作为标准化的远程协议,就是解决这个问题的。MCP 的月下载量已经突破 3 亿了,不是在萎缩,是在加速增长。
而且 MCP 之前被诟病的 Token 开销问题,也在快速改善。Anthropic 做了两个优化:
Tool Search——工具多了不全塞上下文,按需搜索加载,Token 降了 85%。这套机制我们在工具调用那一章详细拆解过。
Code Orchestration——Cloudflare 2500 个 API 端点只暴露 2 个工具(搜索 + 执行),Agent 自己写代码来调用,整套工具定义只占 1000 token。
这些进展说明 MCP 的工程问题不是无解的,社区在持续优化。
最好的做法:Skills + MCP 一起发
Anthropic 最新推荐的模式是:MCP Server 捆绑发布 Skills。Canva、Notion、Sentry 已经在这么做了——MCP Server 提供 API 能力("手"),配套的 Skills 提供最佳实践和使用指南("脑子里的经验"),两个一起给 Agent,效果最好。
说白了,Skills 和 MCP 不是竞争关系,是分工关系——Skills 负责"知道怎么做",MCP 负责"能做到"。本地有完善环境就 Skills + CLI,云端就 Skills + MCP。在需要交互式 UI 的场景(MCP Apps),MCP 更是无法被替代。
设计你自己的 Skill 系统
如果你要做自己的 Agent 产品,Skills 的几个设计原则值得借鉴:
渐进式加载是必须的。不管你叫它 Skills 还是 Plugins 还是 Extensions,初始加载只放摘要,完整内容按需加载。这是唯一能 scale 到几百个扩展的方式。
文件即配置。一个 Markdown 文件比一个配置 JSON + Server 进程简单太多了。降低创作门槛,大家才能贡献生态。
知识比工具更重要。与其给模型 20 个精确的工具调用,不如给它一份写得好的最佳实践文档。模型读文档的能力远强于学新工具的能力。
安全要前置保证。不管是 OpenClaw 的 skill-scanner 还是 Claude Code 对 MCP Skill 的 shell 命令禁用,安全检查要在 Skill 安装或加载时就做,而不是等出了问题再补。
