
Claude Code 的权限模型
好的权限系统应该是:高频安全操作默认放行,低频危险操作才拦。
Claude Code 的权限系统不是一个简单的"允许/拒绝"开关,而是一个多层决策系统。
四种权限模式
Claude Code 支持四种权限模式,从最严格到最宽松:
模式 | 行为 | 适用场景 |
|---|---|---|
plan | 只能读和搜索,不能写任何东西 | 设计方案阶段 |
default | 读操作自动允许,写操作需要确认 | 日常开发(默认) |
acceptEdits | 文件编辑自动允许,Bash 仍需确认 | 信任模型改代码,但不信任它跑命令 |
bypassPermissions | 绕过所有权限检查 | 测试环境(非常危险) |
default 模式下,Read、Grep、Glob 这些只读工具自动放行,Edit、Write、Bash 需要确认。acceptEdits 进一步放开了文件编辑,但 Bash 命令仍然需要审批。
这个分层的核心思想是:按操作的可逆性分级。
三类规则:Allow / Deny / Ask

除了全局模式,Claude Code 还支持细粒度规则。你可以针对具体的工具和参数定义规则:
PLAINTEXT
alwaysAllow: ["Bash(npm:*)", "Bash(git:*)", "Edit"]
alwaysDeny: ["Bash(rm -rf:*)"]
alwaysAsk: ["Bash(curl:*)", "Bash(ssh:*)"]规则的匹配语法是 ToolName(prefix:*)。Bash(npm:*) 表示"所有以 npm 开头的 Bash 命令都自动允许"。这些规则配在哪?Claude Code 有两层配置文件:
~/.claude/settings.json(用户全局):你个人的默认偏好,所有项目生效.claude/settings.json(项目级):跟着 Git 仓库走,团队共享
项目级覆盖用户全局。另外用户在审批时选择"总是允许"也会自动写入规则,下次同类操作不再问。
危险命令模式识别
Bash 命令是权限系统里最难搞的部分——因为模型可以通过 Bash 执行任何事情。
Claude Code 维护了一个危险模式列表,包括:
代码执行入口:python、node、ruby、perl、eval、exec——这些都是"可以执行任意代码"的命令
系统修改:sudo、rm -rf、chmod、chown
网络操作:curl、wget、ssh——可能用于数据泄露
包管理器运行命令:npm run、yarn run、pnpm run——这些实际上可以执行 package.json 里定义的任意脚本
有意思的是,这个列表不只是用来拦截命令的——它还用来识别和清理过于宽泛的 allow 规则。
一次完整的权限检查长什么样
把上面的机制串起来,走一遍完整的流程。假设你在 default 模式下,配置了 alwaysAllow: ["Bash(git:*)"],模型要执行 Bash("git push origin main"):
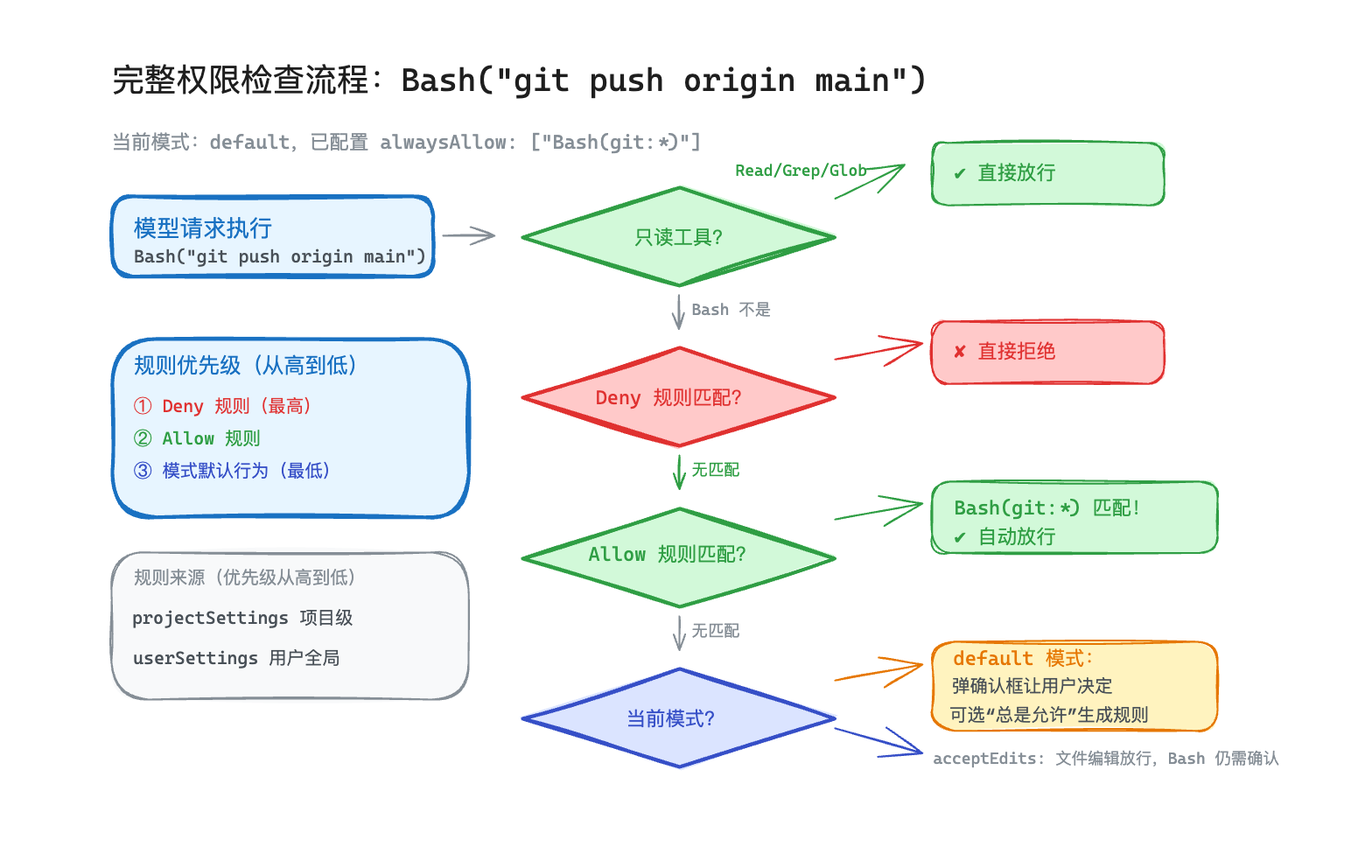
整个流程分几步:先查 Deny 规则(有匹配就直接拒绝),再查 Allow 规则——Bash(git:*) 匹配上了,直接放行。
如果没有匹配的 Allow 规则呢?在 default 模式下,Bash 命令需要确认,弹确认框给用户。用户可以选择"允许一次"或者"总是允许这类操作"——选后者就自动生成一条 Allow 规则,下次不再问。
注意一个细节:Deny 规则的优先级高于 Allow 规则,Allow 规则的优先级高于模式默认行为。
OpenClaw的五层过滤
OpenClaw 的权限思路不太一样——它不用分类器,而是用多层确定性过滤。
第一层:Profile Policy
还记得第 10 篇讲的 Tool Profile 吗?minimal / coding / messaging / full——Profile 决定了哪些工具可用。不在当前 Profile 里的工具,连调用的机会都没有。
第二层:Allow / Deny 白名单
跟 Claude Code 类似,但 OpenClaw 的规则粒度到了 Provider 级别——不同的模型提供商可以有不同的权限策略。
第三层:Owner-only 工具
某些工具只有"Owner"身份才能调用。OpenClaw 是一个多用户系统(支持 Telegram、Discord、Slack 等渠道),Owner 是 OpenClaw 实例的管理员。
具体哪些工具是 Owner-only?cron(定时任务)、gateway(网关控制)。这些工具能改变系统的全局行为,普通用户用不了。
第四层:Exec Approval
执行类工具(exec、shell、write、delete)需要显式审批。OpenClaw 的审批是两阶段的:
服务端注册一个审批 ID。
等待用户在 Telegram/Discord 里做决策(60 秒超时)。
超时了会自动拒绝。
简单来说就是"先注册后等待",两阶段设计防止了 race condition——如果多个工具调用同时请求审批,每个都有自己的 ID,不会互相干扰。
第五层:Workspace 路径边界
所有文件操作被限制在 workspace root 之内。试图读写 workspace 之外的路径的时候,直接拒绝,不问用户。注意这不是操作系统级的沙箱隔离,而是应用层的路径校验——在调用文件操作之前,先检查目标路径是否在允许范围内。
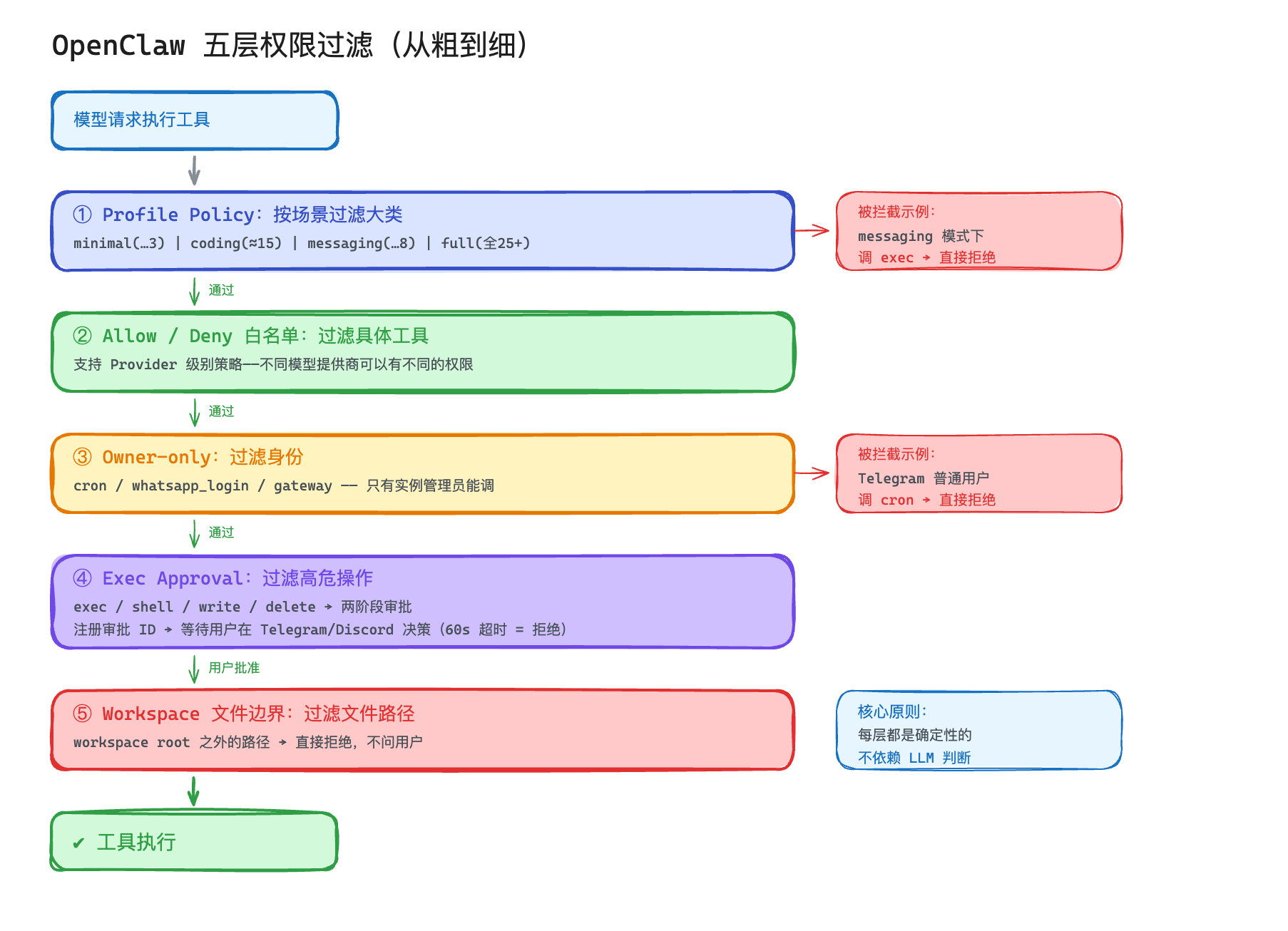
这五层从粗到细:先用 Profile 过滤掉大类,再用白名单过滤具体工具,然后 Owner-only 过滤身份,接着 Exec Approval 过滤高危操作,最后路径边界校验过滤文件访问范围。每一层都是确定性的,不依赖 LLM 判断。
OpenCode 的权限设计:拒绝也是一种反馈
OpenCode 的权限系统在基础规则层面跟 Claude Code 类似——也是 allow / deny / ask 三种 action。但它有两个设计值得单独拎出来说。
纠正反馈(Corrected Error)
大部分 Agent 权限系统里,用户拒绝一个操作,模型收到的信息就是"被拒绝了"。但这对模型来说信息量太少了——它不知道为什么被拒绝,下次可能还犯同样的错。
OpenCode 的做法是:用户拒绝时可以附带一段文字反馈。模型收到的不是 "Permission rejected",而是 "用户拒绝了这个操作,并告诉你:不要直接改 production 分支,先创建一个新分支"。
这个设计把"拒绝"从一个终止信号变成了一个学习信号——模型可以根据反馈调整后续行为,而不是盲目重试或放弃。
拒绝级联
用户拒绝一个权限请求时,OpenCode 会自动拒绝同一 session 里所有正在排队的请求。反过来,用户选"总是允许"时,会自动检查排队中的请求,把匹配新规则的请求也一并放行。
这解决了一个实际问题:模型经常一口气请求 3-5 个工具调用,如果用户拒绝了第一个,说明当前方向不对——后面的请求大概率也不该执行。级联拒绝帮用户省了逐个点"拒绝"的操作。
审批疲劳的终极解法
我们说清楚了问题,也研究透了各家 Agent 产品的生产实践,最后我们回到那个最根本的问题:怎么避免审批疲劳?这里我总结了一些最佳实践,如果你要设计权限系统,可以直接拿过去用:
第一,操作分级是基础。把只读操作和写操作分开,把文件操作和 shell 命令分开,把可逆操作和不可逆操作分开。只读 + 可逆的操作默认放行。
第二,规则要能记忆。用户允许了一次 npm install,下次同类操作应该自动放行,而不是再问一遍。Claude Code 的 alwaysAllow 规则就是干这个的——用户可以在审批时选择"总是允许这类操作"。
第三,确认界面要有信息量。不是弹一个"是否允许?"就完了。好的确认界面应该告诉用户:这个操作要做什么、为什么需要审批、风险等级是什么。Claude Code 的权限提示会显示具体的命令内容和触发审批的原因(是因为规则还是 Hook)。
第四,尽可能自动化。OpenClaw 的五层过滤就是典型——大部分决策在规则层面自动完成,只有真正需要人判断的才弹出来。
进阶方向:用 LLM 分类器做自动审批
上面讲的都是规则驱动的权限系统——规则写死了,系统照着执行。但规则有个天然的局限:它只能处理你预见到的情况。
一个更激进的思路是:用一个轻量 LLM 调用来做权限判断。
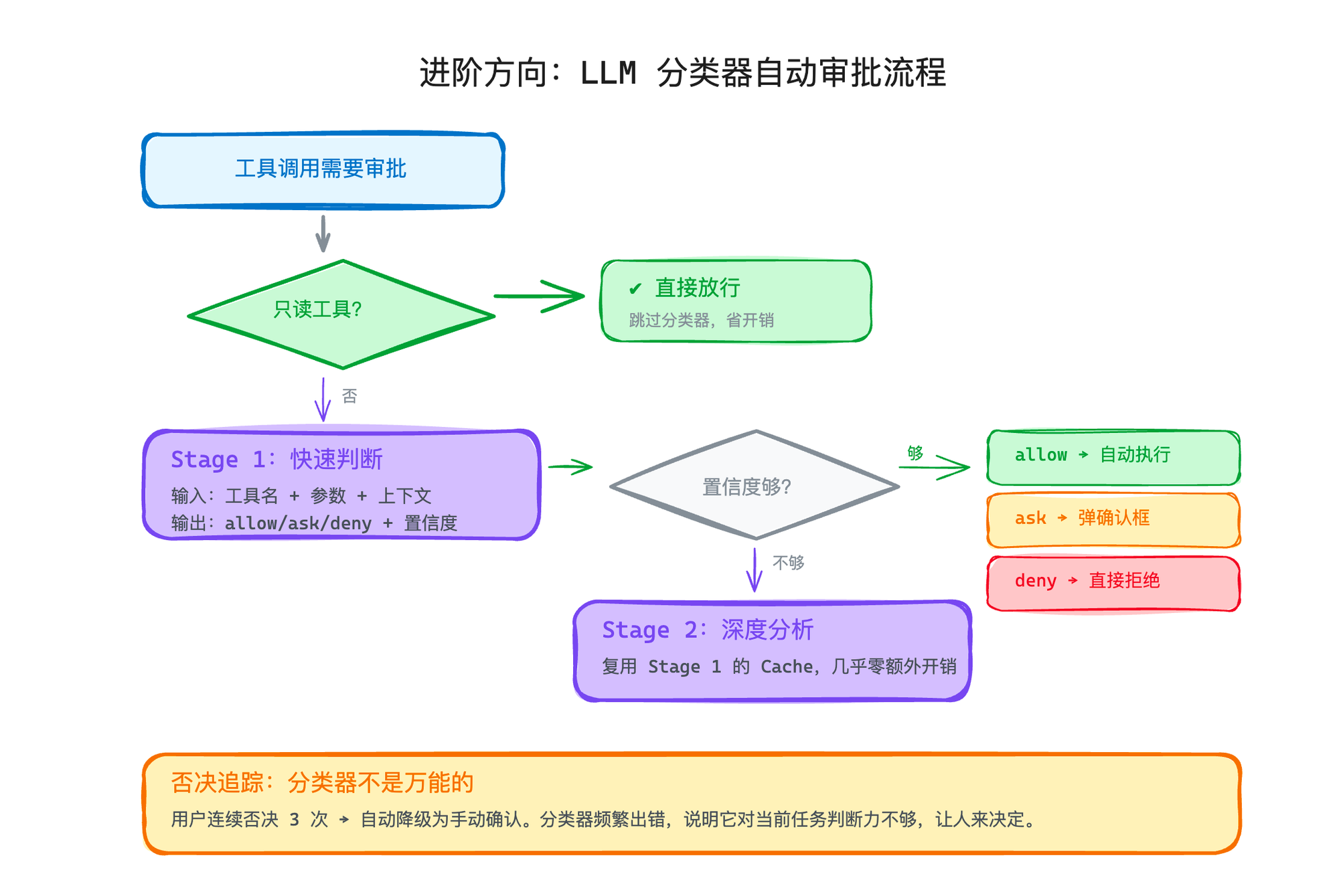
具体怎么做?每次工具调用需要审批时,不是弹框给用户,而是先发一个 query 给模型(一般是比较小的模型,比如 qwen-3.5-flash)——把当前的对话上下文、要执行的工具调用、用户定义的安全规则打包发过去,让模型判断"这个操作在当前上下文下是否合理"。
模型返回 allow / ask / deny + 置信度。置信度高就自动执行,不高就弹确认框让人看。
这个方案有几个工程要点:
首先,只读工具直接放行。Read、Grep、Glob 这些只读工具不需要经过分类器,走快速路径直接放行。没必要花钱让模型判断"读一个文件安不安全"——当然安全。
然后是两阶段判断,这个设计希望你能仔细品味。
你可以把它想象成安检。Stage 1 就是过安检门——你走过去,没响,直接放行。响了,不一定有问题,但需要进一步检查。
Stage 1 怎么做的?给模型的指令很简单粗暴:「宁可错杀不可放过,有问题马上拦住。」模型只被允许输出几十个 token——逼它凭直觉做判断,不给它"想太多"的机会。大部分正常操作(npm install、git add)在这一步就直接放行了,耗时很短、成本也极低。
Stage 2 呢?就是安检门响了之后,安检员让你把包打开、过一遍 X 光。给模型的指令变成了:「仔细想想,一步步分析这个操作到底安不安全,把推理过程写出来。」模型被允许输出 4000 多个 token,可以做完整的思维链推理推理——分析对话上下文、用户意图、操作风险,然后给出最终判断。
关键是:两个阶段共享同一段对话上下文作为 Prompt Cache 前缀。Stage 1 已经帮你把上下文缓存好了,Stage 2 几乎是零额外输入开销——只多了那几十个字的分析指令。
最后,分类器不是万能的,要有兜底。如果用户连续否决分类器 3 次(分类器说 allow,用户说不行),系统就不再信任分类器了,自动降级为手动确认模式。这个"否决追踪"机制很重要——它承认了一个事实:分类器在某些场景下就是会判断失误,与其让它继续犯错,不如让人来。
这个方向目前还比较前沿,但它代表了权限系统的演进方向——从静态规则到动态判断,从"一刀切"到"看上下文决定"。
