
工具执行的七步管线,从验证到权限再到执行,每一步都在防止模型做蠢事。但有一个问题:工具本身的数量。之前在Function Calling中我们说过,工具从10个涨到50个,选择准确率从90%掉到不到50%,模型的性能直线下降,在超过了一定的阈值之后,工具越多,模型越犯傻。另外:上下文窗口就那么大,每个工具的JSON Schema定义平均500-800 token。光是工具的定义占掉了上下文的40%-60%。留给“真正干活的空间已经不多了”。
思路一:延迟加载-Deferred Tool Loading
面对多工具的情况下,Claude Code的做法是-Deferred Tool Loading ——不是一开始就把所有工具的完整定义塞给模型,而是按需加载。具体怎么做?
两类工具会被延迟加载:
MCP工具:所有通过MCP Server 接入的外部工具,默认全部延迟加载。原因很简单,MCP工具是用户自己装的,数量不可控,而且大部分对话用不上。
内置工具中标记了shouldDefer:true的:Claude Code 把自己的工具分为了两组:
分类的依据:使用的频率。
核心工具:Read,Edit,Write,Bash,Grep,Glob,Agent,Skill—这些常用的,每次对话都要用的,永远加载。
低频工具:WebSearch,WebFetch,Task管理—增加shouldDefer标记。
那么工具被延迟加载了,如何在对话中被发现呢?
模型的prompt里看到的不是完整的工具Scheme,而是一个工具名字列表。类似于:
PLAINTEXT
以下工具可用,但需要先通过 ToolSearch 获取完整定义:
WebSearch, WebFetch, NotebookEdit, LSP, CronCreate, CronList...然后Claude Code提供了一个特殊的元工具——ToolSearch。模型需要使用某个延迟加载的工具时,先通过调用 ToolSearch,传入查询关键词或者工具名,ToolSearch返回匹配工具的完整Schema定义。这样的处理相当于是给工具集加了一个“搜索引擎”。
ToolSearch支持三种查询方式:
精确选择:select:Read,Edit,Grep——直接按照名字获取。
关键词搜索:notebook,jupyter——模糊匹配。
必选+排序:+slack send——名字里必须包含slack。
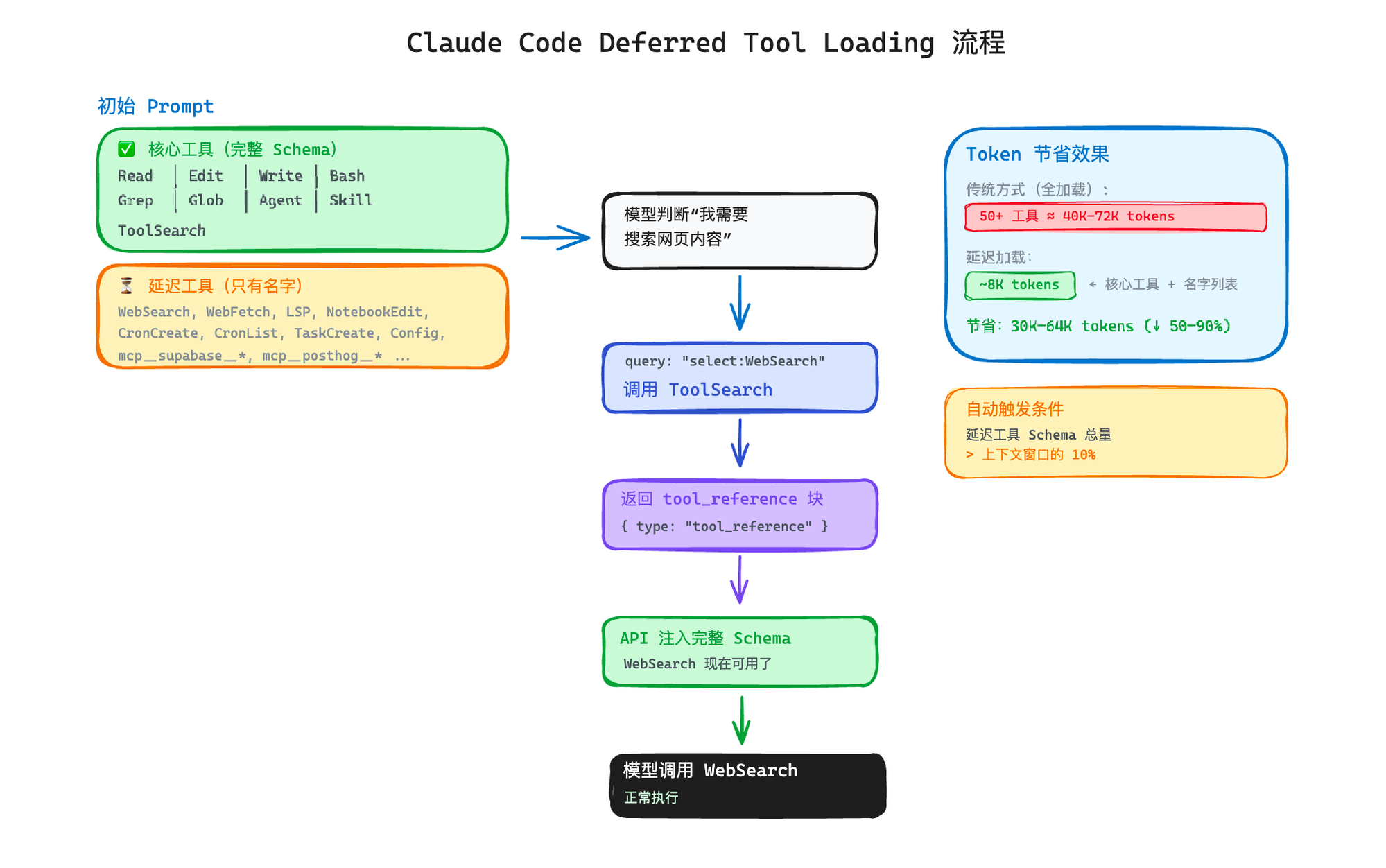
但是,不是所有的场景都需要延迟加载。如果用户只接了一个MCP Server,3个工具,没必要多此一举。所以Claude Code设了一个自动触发的阈值:当延迟工具的JSON Schema总量超过上下文窗口的10%时,才启用延迟加载。低于这个阈值,所有工具正常加载,没有额外的开销。高于这个阈值,自动切换到延迟加载模式。
但是这个延迟加载的方案有个前提:你得使用Anthropic原生的API。如果你用的是第三方代理或者自建的API Gateway,代理不认识tool_reference块就会直接报错400错误。什么意思呢?也就是说:延迟加载defer_loading 和 tool_reference都是API的beta特性,Claude Code在请求里带上beta header,API端菜接受这些字段,你用代理的API,它不认识。Claude Code里面专门有个检测请求地址是不是Anthropic原生域名,如果不是原生域名,会自动禁用延迟加载,退回到传统的全量加载模式。
具体机制如下:
Claude Code在发送工具定义时,会给被延迟加载的工具打上defer_loading:true标记。API收到后,知道这个工具只需要在必要时加载到模型的上下文里。
当ToolSearch返回结果时,它不是返回纯文本,而是返回tool_reference类型的内容块,API看到是tool_reference,就会把对应工具的完整Schema注入到模型的上下文中。
整个流程的闭环如上面的图:初始prompt只是给核心工具的完整Schema和延迟工具的名字列表,模型识别到需要延迟加载的工具会调用ToolSearch,拿到tool_reference后API把完整的Schema注入到上下文,模型就能正常调用延迟加载的工具了。多了一次工具调用的开销,但省下来了所有工具加载的token消耗。
对Prompt Cache的影响:
你可能会想:模型通过ToolSearch加载了一个新工具的完整Schema,相当于修改了工具列表,Cache就炸了,实际上并不会,关键在于defer_loading:true的工具从一开始就不参与Cache的计算。
什么意思呢?就是在计算prompt的cache key时,所有标记了defer_loadin的工具会被直接过滤掉。因为API端也不会把这些工具塞进模型的prompt,他们压根不会出现cache的范围内。
tool_reference返回后,新加载的工具Schema去向也不是你想的那样,他们会出现在对话历史里。也就是出现在tool_result消息中,不是在工具定义区域。工具定义区域(prompt前部)从头到尾只有那几个核心工具,永远不变。
所以整个过程对Cache的影响是:核心工具的Cache前缀始终稳定,不管你通过ToolSearch加载了多少个延迟工具。这也是为什么这个方案比直接动态增删工具列表要好得多——他把工具发现这件事从prompt结构层面移到了对话内容层面。
一个值得注意的细节:每个延迟工具都有一个 searchHint 字段——一个 3-10 个词的短语,帮助 ToolSearch 做关键词匹配。比如 LSP 工具的 hint 是 "code intelligence (definitions, references, symbols, hover)",NotebookEdit 是 "edit Jupyter notebook cells (.ipynb)"。这些 hint 不会显示给模型,只在 ToolSearch 内部用于匹配。
小结
Deferred Tool Loading主要三个点:
defer_loading的工具从一开始就不参与Cache key计算,在源码里直接过滤掉。
新加载的Tool Schema出现在对话历史tool_result里,不是在工具定义区域,所以不影响Prompt前缀。
本质是把“工具发现”从Prompt结构层面移到了对话内容层面,这就是它比动态增删工具列表高明的地方。
思路二:Tool Profile——工具配置文件
OpenClaw的思路不太一样,它不是延迟加载,而是按场景预选。也就是OpenClaw定义了4种Tool Profile(工具配置文件):
Profile | 适用场景 | 包含工具数 |
|---|---|---|
minimal | 最基础的交互 | ~3 个(session_status 等) |
coding | 编程场景 | ~15 个(read/write/edit/exec/memory 等) |
messaging | 通讯场景 | ~8 个(message/sessions 等) |
full | 全部能力 | 所有 25+ 个核心工具 |
每个核心工具在定义时就标注了自己属于哪些 Profile。比如 read、write、edit、exec 属于 coding Profile,message 属于 messaging Profile,session_status 在前三个 Profile 中都存在。
系统根据当前会话的场景选择对应的 Profile,然后只加载该 Profile 允许的工具。
Tool Group:批量引用
OpenClaw 还有一个 Tool Group 的概念。工具按功能分组:
group:fs→ read, write, edit, apply_patchgroup:runtime→ exec, processgroup:web→ web_search, web_fetchgroup:memory→ memory_search, memory_getgroup:sessions→ sessions_list, sessions_history, sessions_send, sessions_spawn
配置时可以直接引用整个组,而不是逐个列出工具名。这个设计的好处是可预测——你知道每个场景下模型能用什么工具,不会有意外。坏处是不够灵活——如果用户在 coding 场景下突然需要发消息,messaging 工具不可用,需要切换 Profile。
小结
Claude Code的延迟加载是按需发现——所有工具都可用,只是模型需要先搜索。
OpenClaw的Profile是按场景裁剪——不在当前Profile里的工具,模型完全看不到,也不能用。
前者更灵活,后者更可控。
思路三:小工具集——Manus的极简哲学
Manus采用了一条更激进的路:从源头控制工具数量。核心理念是:不到20个原子工具+CLI sandbox。
Manus的工具集分三层:
第一层:原子工具(~20个),固定的,最小化的Function calling工具集。类似file_write,bash。这些工具定义永远不变。
CLI 工具(通过sandbox暴露),遇到原子工具覆盖不了的能力,Manus 的思路是不加新工具,让模型通过
bash调用系统命令。要用 ffmpeg 的时候,执行bash("ffmpeg -i input.mp4 ...")。要用 curl 的时候,执行bash("curl https://...")。甚至 MCP 工具也通过mcp-cli命令行包装器暴露。写脚本:更复杂的组合逻辑就让模型写 Python 或 Node.js 脚本放到 sandbox 里跑。
Manus 的原话是:"heavily armed agents get dumber"——给 Agent 堆太多武器,它反而变笨了。
这个哲学非常反直觉。大多数人的第一反应是"工具越多越好",但 Manus 反过来做——用最少的工具覆盖最多的场景,复杂操作通过组合原子工具来实现。
KV Cache杀手:为什么不能随便改工具列表
三种思路都绕不开一个底层问题:KV Cache。
前面讲过,KV Cache 是模型推理的加速器——上下文的前缀不变,计算结果就能复用。Anthropic 的 Prompt Caching 缓存命中是 $0.30/百万 token,未命中是 $3.00/百万 token,10 倍差距。
工具的 JSON Schema 定义在 prompt 的前部(system prompt 之后、对话历史之前)。如果你在对话过程中动态增减工具,从工具定义的位置开始,后面所有内容的 KV Cache 全部失效。
什么意思呢?假设你第一轮有 10 个工具,第二轮变成 12 个——不是只多算那 2 个工具的 token,而是从工具定义开始到对话末尾的所有 token 都要重新计算。如果对话已经有 100K token 了,你多加 2 个工具的代价是重新计算 100K token。
这就是为什么 Claude Code 的延迟加载要和 API 配合——被延迟的工具用
defer_loading: true标记,API 知道这些工具不影响 Cache 计算。ToolSearch 加载新工具后,通过tool_reference块注入,而不是直接修改工具列表。
Manus 的 "Mask Don't Remove"
Manus 对 Cache 问题有一个特别好的解法:不删除工具定义,用 mask 标记不可用。
传统做法是:要禁用某个工具就从工具列表里移除。但这样改变了 prompt 结构,Cache 直接失效。
Manus 的做法:工具列表永远不变。需要禁用某些工具时,不修改定义,而是在解码阶段通过 response prefill 让模型选不了那些工具——把被禁工具的生成概率直接设为零。
工具名用一致的前缀(browser_*、shell_*),这样可以按组整体 mask,不需要逐个管理。
效果是:Manus 的 Prompt Cache 命中率达到 ~95%,相比动态增删工具的传统做法(~20% 命中率),成本降低 60%-85%,响应速度提升 2-3 倍。
小结:三种思路的权衡
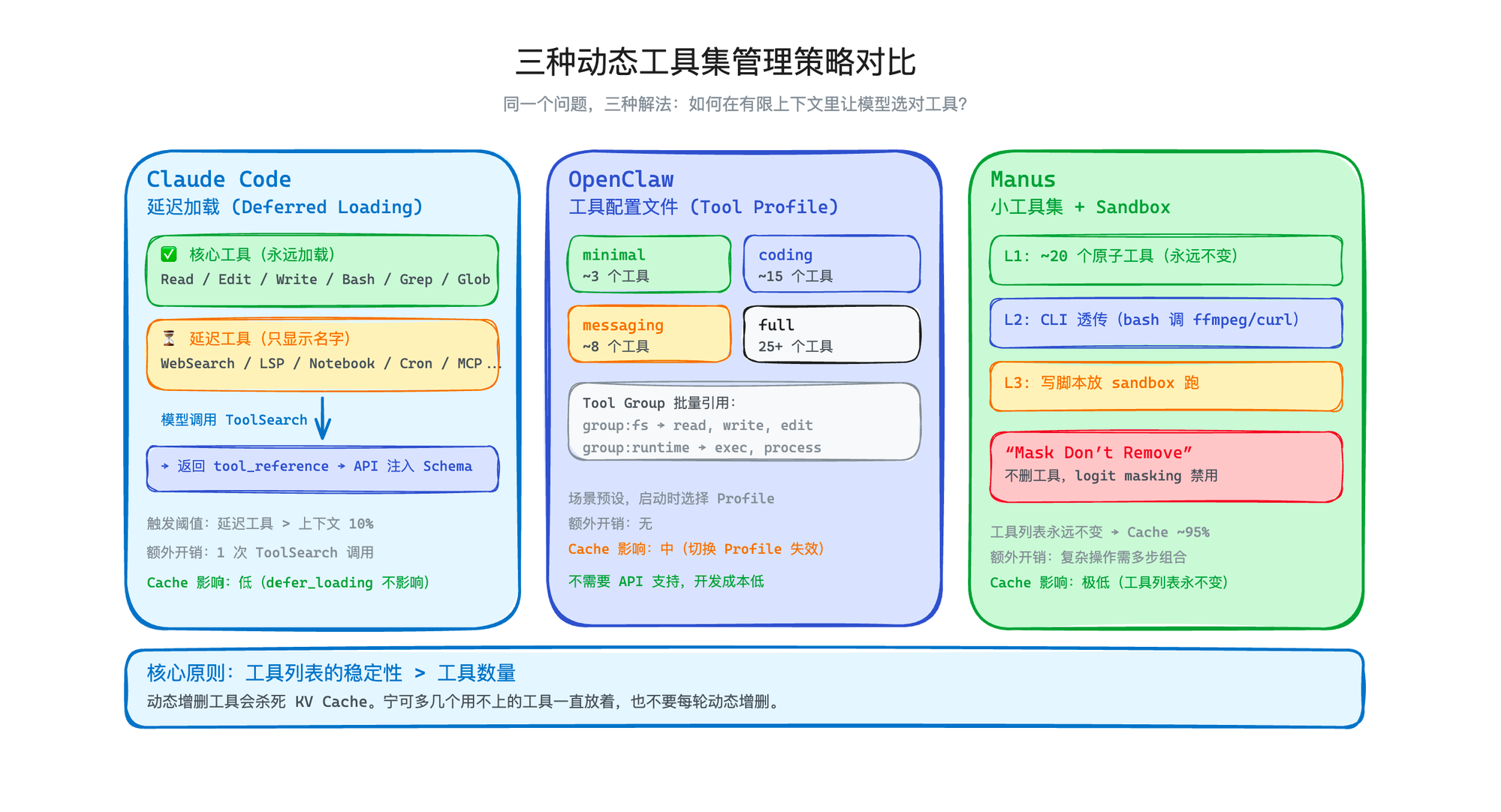
Claude Code 延迟加载 | OpenClaw Profile | Manus 小工具集 | |
|---|---|---|---|
核心思路 | 按需发现 | 按场景裁剪 | 从源头控制 |
工具上限 | 无限(延迟的不占空间) | 由 Profile 决定 | ~20 |
Cache 影响 | 低(API 支持 defer_loading) | 切换 Profile 会影响 | 极低(工具列表永远不变) |
额外开销 | 多一次 ToolSearch 调用 | 无 | 复杂操作需要多步组合 |
灵活性 | 最高 | 中等 | 最低但最可控 |
需要 API 支持 | 是(defer_loading + tool_reference) | 否 | 是(logit masking) |
没有哪种方案是绝对最优的。Claude Code 的延迟加载最灵活,但依赖 API 层的 beta 特性。Manus 的小工具集最省 token、Cache 最友好,但需要模型有更强的组合能力。OpenClaw 的 Profile 是个务实的中间路线——不需要 API 支持,开发成本低,大多数场景够用。
你想想,这三种方案本质上在解决同一个问题:怎么在有限的上下文窗口里,让模型既能"看到"足够多的能力,又不被太多选项搞晕?
说白了就是一个信息架构问题——跟搜索引擎的索引、电商的商品分类、操作系统的文件系统没什么本质区别。你不会把 100 万个商品全铺在首页,你也不应该把 100 个工具全塞进 prompt。
