
工具执行7步管线
Function Calling 的原理:模型输出一段 JSON,表达「我想调用 read_file」的意图。但模型说了不算。如果模型说「我要执行 rm -rf /」,你真的就执行了吗?如果模型编了一个不存在的文件路径,如果不做任何检查就去读,肯定会报错。模型生成的输入是不可信的。 这是工具系统设计的第一原则。
不管是 Claude Code、OpenClaw 还是 OpenCode,这些成熟的 Agent 工程化产品,工具执行的管线大同小异。抽象来看,都是这几个阶段:
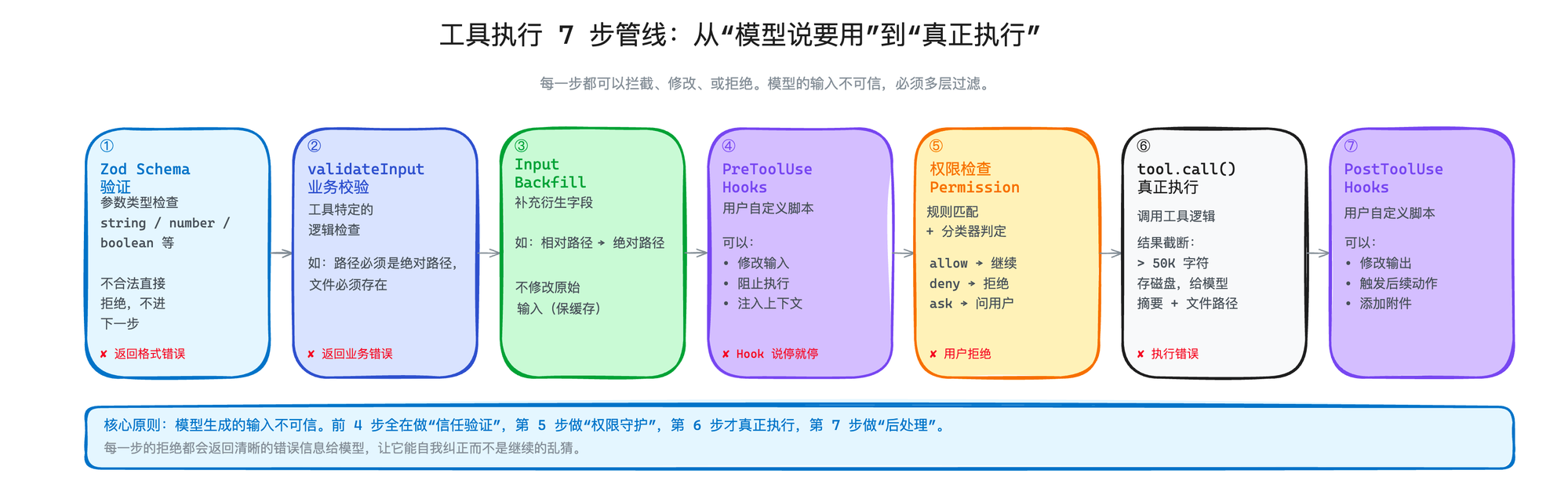
每一步都可以拦截、修改、或者直接拒绝。任何一步失败,工具就不会执行——模型会收到一个错误消息,告诉它为什么失败、该怎么纠正。
第一步:参数格式验证
模型输出了一段 JSON,首先要检查:这段 JSON 的类型对不对?
之前说过,约束解码能保证 JSON 格式 100% 合法。但在实际系统中,你不能假设每个请求都经过了约束解码——可能有旧版本 API、可能有第三方代理中间层,各种意外都可能导致格式不合法。
生产环境通常都用 Zod 做这一层验证:
TYPESCRIPT
import { z } from 'zod'
// 工具定义里声明的 schema
const ReadSchema = z.object({
file_path: z.string(),
offset: z.number().optional(),
})
// 模型实际传过来的输入(file_path 类型错了)
const input = { file_path: 123 }
// 用 schema 校验
const result = ReadSchema.safeParse(input)
// result.success === false
// result.error 里精确指出:input.file_path: Expected string, received number
Zod 的好处是:验证失败时会返回精确的错误路径。不是笼统地说「参数有误」,而是告诉你「input.file_path 应该是 string,但收到了 number」。这个精确性很重要——模型需要这些信息来纠正自己的输出。
第二步:业务逻辑校验
类型对了,但值合不合理呢?我们需要对值本身来做校验,这一步做的是语义层面的检查。
这些都是 validateInput 做的事:
TYPESCRIPT
// Claude Code 的 FileEditTool
validateInput(input) {
// 检查文件是否存在
// 检查 old_string 是否在文件中能找到
// 检查 old_string 是否唯一(不然不知道改哪个)
// 如果不唯一,返回: "old_string 在文件中出现了 3 次,请提供更多上下文使其唯一"
}
注意错误信息的设计。不是返回「校验失败」,而是返回具体的原因 + 建议。
第三步:输入补全和标准化
经过了验证和校验之后,输入在格式和语义上都没问题了。但可能还需要补充一些模型没有提供的信息。
比如说,模型传了 file_path: "src/index.ts"。业务校验这里放宽了——接受相对路径。但工具内部需要绝对路径。这一步就是把相对路径转成绝对路径。
Claude Code 做了这样一件事:在不改变模型原始输入的前提下,生成一份带有补充字段的副本。
这里不能直接改原始输入,为什么?关键在于缓存。模型的输入会被序列化进对话历史,改了它就意味着序列化内容变了,Prompt Cache 直接失效。所以 Claude Code 会保留原始输入(用于缓存),同时生成一份补全后的副本(用于后续步骤)。
这个设计很精妙但容易忽略。你不这么做,每次补全输入都可能导致缓存 miss,累积起来的延迟和成本非常可观
第四步:前置 Hook——用户的「场外指导」
前三步都是系统内部的检查。第四步把控制权交给了用户。
Hook 是用户自定义的脚本,在工具执行的关键节点被触发。前置 Hook(PreToolUse)在工具执行前运行,它可以:
修改输入:比如把所有文件路径重写到一个沙箱目录
阻止执行:比如检测到
rm命令就拒绝注入额外上下文:比如附加一些模型需要知道的信息
JSON
// 用户配置的 Hook
{
"event": "PreToolUse",
"command": "bash /path/to/my-check.sh $TOOL_NAME $TOOL_INPUT"
}
Hook 脚本的返回值决定了下一步怎么走:
返回 0:放行
返回 2(或输出 JSON
{"decision": "block"}):阻止执行输出 JSON
{"updatedInput": {...}}:修改输入后放行
Hook 存在的意义在于定制化。Agent 的使用场景千变万化,没有哪个工具系统能预见到所有需求。有人在 CI 里跑 Agent,需要禁止所有写操作;有人在特定项目里跑,需要把路径映射到某个特定的磁盘位置;有人做打点记录,需要记录每一次工具调用。
这些需求如果都去改框架代码,工具系统很快就会臃肿不堪。Hook 机制让定制化不需要改源码——写个脚本挂上去就行。
第五步:权限检查
通过了所有验证和 Hook 之后,还有一关:用户授权。
权限系统通常有三层:
规则匹配:根据预配置的规则决定。比如「Read 工具永远允许」「Bash(git ) 允许」「Bash(rm ) 拒绝」。
JSON
{
"allow": ["Read", "Glob", "Grep", "Bash(git *)"],
"deny": ["Bash(rm -rf *)"]
}
分类器判定:对于规则没有覆盖到的情况,用一个轻量分类器来判断这次调用是否安全。Claude Code 针对 Bash 工具就有一个专门的分类器——Bash 命令的风险差异太大,简单规则覆盖不了。
这个分类器的做法是结合当前的对话上下文和要执行的具体命令,通过一次轻量的 LLM 调用来评估这个操作是否安全。不是简单的字符串匹配,而是语义层面的理解——它能区分 git status(只读查看)和 git push --force(有风险的覆盖操作),即便两者都以 git 开头。
这比硬编码的 glob 规则(Bash(git *))灵活得多。glob 规则要么全放行、要么全拒绝,没办法根据具体命令的风险程度做细粒度的判断。而 LLM 分类器可以理解命令的实际语义和当前上下文,做出更合理的决策。
说个反直觉的结论,Coding Agent 其实比通用 Agent 更难做,很大一部分原因就在这种系统性的安全问题上。Bash 命令的权限实在是太大了,简单的白名单根本覆盖不住各种边界情况。Claude Code 的思路是让 LLM 提前做判定,用微小的一点延迟换来更高的安全性——这是专门针对 Coding 场景才值得付出的成本。
交互式询问:如果规则和分类器都没法决定,弹窗问用户:「Agent 想执行 npm install express,允许吗?」用户可以选择「这次允许」或「永远允许」。
这三层的设计原则是:能自动判定的就自动判定,减少打扰用户。 Read 这种只读操作不需要问,git status 这种安全命令也不需要问。只有真正有风险的操作才打断用户。
第六步:真正执行
经过了前面五层过滤,输入终于被认为是安全的、合法的、已授权的。
这一步才调用 tool.call()——执行真正的工具逻辑。
但执行完还没完。结果也需要处理。
结果截断是一个关键机制。工具返回的内容可能非常大——比如 Read 工具读了一个 10000 行的文件,Bash 工具执行了一个输出 100KB 日志的命令。
如果把完整结果塞进对话历史,上下文直接就爆了。
所以 Claude Code 设了一个阈值:默认 50,000 字符。超过这个大小,结果被存到磁盘上,对话历史里只放一个摘要 + 文件路径的引用。
PLAINTEXT
结果太大 → 存到 /tmp/tool_results/xxx.txt
对话历史里放:"[结果已保存到文件,使用 Read 工具查看 /tmp/tool_results/xxx.txt]"
这里还有一个容易忽视的点:Claude Code 对单条消息内所有工具结果也有一个总预算(默认 200,000 字符)。因为模型可以并发调用多个工具——如果 10 个工具各返回 40K 字符,单条消息就有 400K,即便每个没超标,总量也爆了。
错误处理同样重要。如果工具执行失败了,错误信息怎么返回给模型,直接影响模型能不能纠正错误。
这里有一个软件设计范式的变化需要你意识到——传统编程里错误信息是写给开发者看的,ENOENT、EACCES 这些错误码开发者一眼就能读懂。但 Agent 系统里接收错误信息的是模型,模型需要的不是错误码,而是纠正所需的上下文。
举个例子,下面是一个好的错误信息:
PLAINTEXT
文件 /src/helpers/utils.ts 不存在。
当前 /src/ 目录下有以下文件:
- /src/utils.ts
- /src/lib/helpers.ts
- /src/common/utils.ts
而下面是一个反面案例:
PLAINTEXT
ENOENT: no such file or directory, open '/src/helpers/utils.ts'
前者给了模型足够的上下文来自我纠正(「哦,应该是 /src/utils.ts」)。后者只是转发了系统错误码,模型看完之后可能换个路径再猜一次,而不是查看实际有哪些文件。
这不是一件小事。错误信息写得好,模型一次就能纠正;写得差,模型可能在同一个错误上打转好几轮,白白烧掉 Token 和时间。
前面每一步返回的错误其实都遵循这个原则——Schema 验证返回的是 "file_path 应该是 string,收到了 number"、业务校验返回的是 "old_string 在文件中出现了 3 次,请提供更多上下文",而不是笼统的 "validation failed"。整条管线的错误返回加起来,共同决定了 Agent 的纠错效率。
第七步:后置 Hook
最后一步,跟第四步对称。后置 Hook(PostToolUse)在工具执行完成后运行,可以:
修改输出:比如过滤掉敏感信息
触发后续动作:比如工具修改了文件后自动跑 lint
记录审计日志:追踪每一次工具调用的详情
比如用户配了一个 PostToolUse Hook,每次 Edit 工具修改文件后自动跑 eslint --fix。这样 Agent 改完的代码自动就被格式化了,不需要额外让模型去做。
总结
这篇介绍单次工具调用的执行管线。回头看整条管线,你会发现一个贯穿始终的原则——错误信息是给模型看的,不是给人看的。这是一种新的软件设计范式,传统编程里 ENOENT 开发者能看懂,但 Agent 系统里接收错误的是模型,它需要的不是错误码而是纠正所需的上下文。这件事看起来很小,但实际决定了模型是一次纠错成功,还是在同一个错误上反复打转。
