
Function Calling的真实过程
模型只生成JSON,执行是代码做的
你在 Claude 或 ChatGPT 里输入「北京今天天气怎么样?」,模型会回一段 JSON:
JSON
{
"type": "tool_use",
"name": "get_weather",
"input": { "city": "北京" }
}
然后你的代码拿到这个 JSON,去调天气 API,把结果塞回给模型,模型再用自然语言回复用户。
看起来很自然,像模型真的「调用了一个函数」。
但如果你停下来想一秒:模型是怎么知道要输出这段 JSON 的?它怎么知道有个工具叫 get_weather?它怎么知道参数应该是 city 而不是 location?
先说结论:模型不会调用任何函数。
Function Calling 这个名字是有误导性的。实际发生的事情是:
你在 API 请求里塞了一份「工具菜单」——一组 JSON Schema,描述了每个工具叫什么、干什么、参数是什么格式
模型看到了这份菜单,结合用户的问题,决定要不要使用某个工具
如果要用,模型生成一段符合 Schema 的 JSON——这就是所谓的「函数调用」
你的代码解析这段 JSON,你来执行真正的函数
执行结果塞回对话,模型看到结果后继续回复
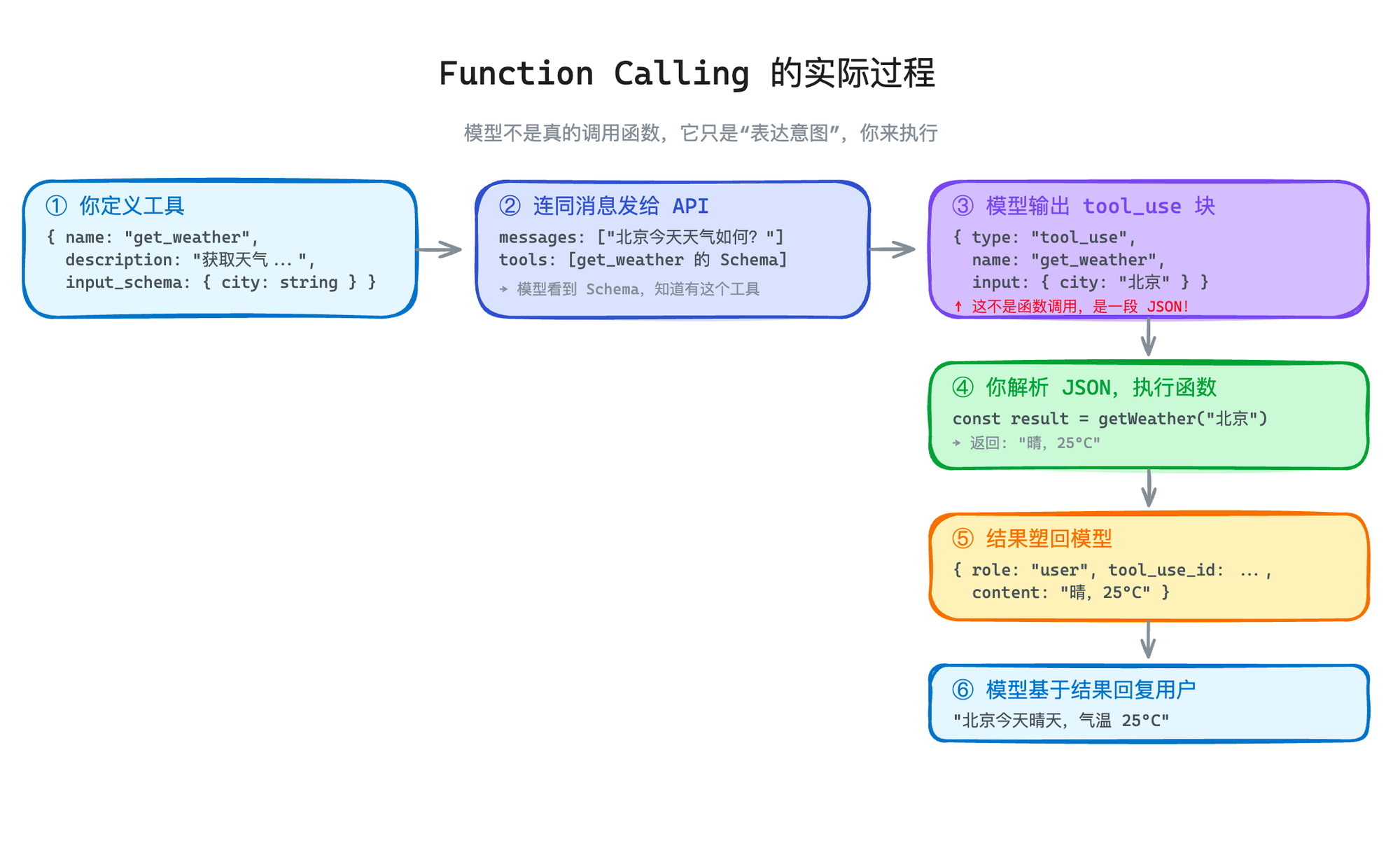
整个过程中,模型做的事只有一件:输出一段符合格式的 JSON。执行是你做的。
这个区分非常重要。如果你把 Function Calling 理解成「模型能调用函数」,你会低估参数校验的重要性——觉得模型既然「调用了」,参数总不会错吧?错。模型只是生成了一段 JSON,它可以把任何东西填进去。
约束解码:如何保证输出的JSON合法?
主要靠两件事:训练 + 约束解码。
训练好理解——模型在训练阶段看过大量的「输入 Schema + 输出符合 Schema 的 JSON」的样本,学会了怎么根据 Schema 生成对应的 JSON。
但光靠训练不够。OpenAI 公布过一个数据:单靠训练,JSON Schema 符合率只有 93%。93% 在生产环境远远不够——100 次调用里有 7 次格式错误,Agent 跑 10 轮就大概率崩一次。
所以还需要约束解码(Constrained Decoding)。
什么是约束解码?
约束解码。它的核心逻辑是:在模型生成每一个 token 时,根据当前的 JSON Schema 语法规则,把那些“语法上不合法”的 token 概率强制设为 0,只让合法的 token 参与采样。
回顾之前说的自回归生成:模型每次只生成一个 Token,从词表里选概率最高的。约束解码做的事就是:在选 Token 之前,把不合法的选项排除掉。约束解码会排除掉数字、布尔值、null 等不符合 string 语法的 token,确保生成的 JSON 在语法结构上是 100% 合法的。但是它不能保证语义正确。
具体来说:
把 JSON Schema 编译成一套语法规则(上下文无关文法)
每生成一个 Token,检查:接下来哪些 Token 在语法上合法
不合法的 Token 概率设为 0
剩下的合法 Token 重新归一化,正常采样
训练 + 约束解码 = 100% 格式合法。
但要注意:约束解码只保证格式,不保证语义。
✅ 能保证:city 字段一定是 string 类型
❌ 不能保证:city 的值是真实存在的城市(模型可以填「哥谭市」)
❌ 不能保证:模型选对了工具(应该用 get_weather 却用了 search)

所以你仍然需要参数校验、执行前检查、以及清晰的错误反馈
工具越多越不准
Function Calling 在少量工具的时候表现很好。但当工具数量上去之后,准确率会明显下降。
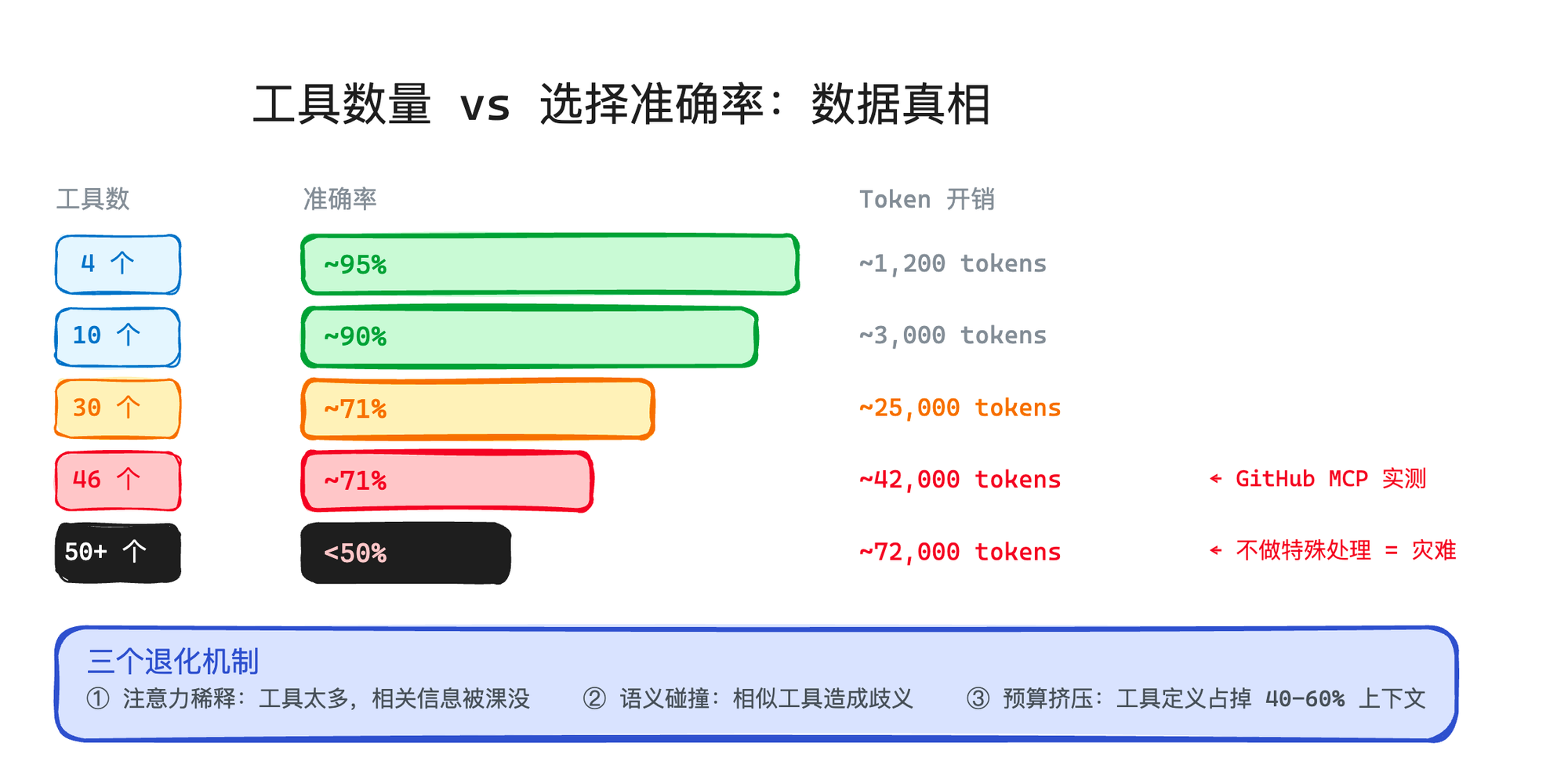
为什么会这样?里面有三个退化机制在起作用:
第一:注意力稀释。 工具越多,每个工具的描述在上下文里占的比例越小。模型的注意力被分散了,就像你同时看 50 个菜单页,反而不知道点什么。
第二:语义碰撞。 当工具多了,难免有功能相似的。search_files 和 find_files 有什么区别?read_file 和 get_file_content 呢?当工程量起来之后,这种重复工具的工具很容易出现,模型容易搞混。
第三:预算挤压。 每个工具的 JSON Schema 都要塞进上下文。46 个 GitHub MCP 工具就吃掉 42,000 Token——还没开始对话,上下文已经被占了一大块。留给用户消息和对话历史的空间就少了。
为了应对这个问题,像 Claude Code 这样的生产级系统采用了一种叫 Deferred Tool Loading(延迟加载) 的策略。它不会一开始就把所有 30+ 个工具都塞给模型,而是先给一个精简的“核心菜单”。只有当模型表现出需要某个特定领域的工具时,系统才会动态地把那部分工具的详细定义“注入”到上下文中。
但是这种“按需加载”的策略虽然节省了 Token,但也带来了一个挑战。如果模型在第一步思考时,根本不知道某个“隐藏工具”的存在,它就无法主动去调用它。
为了解决这个矛盾,生产级系统(如 Claude Code)通常会引入一个中间层,叫做 Tool Search(工具搜索) 或 Retrieval。
它的逻辑是这样的:
元数据索引:给每个工具打上关键词标签(比如
searchHint: "jupyter notebook")。动态检索:当用户输入问题时,先用一个轻量级的模型或者向量搜索,从全局注册表中找出最相关的 5-10 个工具。
精准注入:只把这 5-10 个工具的详细 Schema 塞进当前的对话上下文。
这样既保证了模型在需要时能“看见”工具,又避免了 50 个工具同时出现的注意力稀释。
但是:这种“先检索、后注入”的策略虽然高效,但也存在风险。如果用户的意图非常模糊,或者检索算法不够聪明,可能会漏掉真正需要的工具。可以设计两层兜底:
元数据摘要(Tool List):即使不注入详细的 Schema,也要在系统提示词里保留一份所有工具的简短列表(只包含名字和一句话描述)。这样模型至少知道“世界上存在这个工具”,它可以在回复中主动请求:“我需要调用
complex_analysis工具,请加载它的定义。”递归加载(Recursive Loading):当模型表达出对某个未加载工具的意图时,系统拦截这个请求,动态加载该工具的详细 Schema,并让模型重新生成。
这就好比你去图书馆,虽然书架上没摆那本冷门书,但目录卡片里有它的名字。你可以告诉管理员:“我要找这本书”,管理员再帮你从仓库调出来。
模型出现幻觉
工具选对了,参数格式也对了。但还有一个坑:参数的值可能是假的。
这就是所谓的「工具幻觉」。模型会:
伪造文件路径:你让它读
/src/utils.ts,它可能输出/src/helpers/utils.ts——这个路径不存在,是模型根据常见项目结构「猜」的编造 ID:让它删除某条记录,它可能编一个看起来像 UUID 但完全不存在的 ID
猜测 URL:让它访问某个 API,它可能拼一个看起来合理但并不存在的端点
这些幻觉的麻烦在于:约束解码拦不住它们。 约束解码只管类型——路径是 string 就放行,ID 是 string 就放行,URL 是 string 就放行。至于这个 string 的值是真是假,完全不在它的检查范围内。所以 JSON Schema 验证一路绿灯,但真正执行的时候必然会失败。
要应对这个问题,你需要在 Schema 设计和执行链路上都做防御。
第一:用 enum 约束可选值
如果参数的合法值是有限的,用 enum 而不是裸的 string。
JSON
{
"action": {
"type": "string",
"enum": ["read", "write", "delete"]
}
}
模型在约束解码下只能从这三个值里选,没法编造第四个。
第二:执行前校验
在真正调用函数之前,做一次业务级校验。比如文件路径:先检查文件是否存在;如果不存在,返回一个带有建议的错误信息。
比如在 Claude Code 的工具定义里,有一个专门的 validateInput(input) 方法。在真正执行文件读取之前,代码会先检查:
路径是否是绝对路径?
路径是否包含
..(防止目录遍历攻击)?目标文件在磁盘上真的存在吗?
如果校验失败,代码不会崩溃,而是返回一个清晰的错误信息给模型,比如:“文件 /src/helpers/utils.ts 不存在。当前目录下有 /src/utils.ts,你要找的是这个吗?”
第三:清晰的错误反馈
好的错误信息:
"文件 /src/helpers/utils.ts 不存在。当前目录下有 /src/utils.ts 和 /src/lib/helpers.ts,你要找的是哪个?"
坏的错误信息:
"ENOENT: no such file or directory"
前者给了模型足够的信息来纠正自己。后者让模型一脸懵——可能会换个路径再试,也可能换个完全不相关的策略。
这就是约束解码的边界:它保证了语法的“形”,而业务校验和错误反馈保证了语义的“神”。
Structured Output
你可能意识到了:Function Calling 本质上就是让模型输出一段符合特定格式的 JSON。
那如果我不需要调用函数,只是想让模型按固定格式输出呢?比如让模型打分:
JSON
{
"score": 8,
"issues": ["变量命名不规范", "缺少错误处理"],
"pass": true
}
这就是 Structured Output——跟 Function Calling 用的是同一套技术(约束解码),只是场景不同。
场景一:上下文摘要
Agent 对话跑了几十轮,上下文快满了,需要压缩。你不能让模型自由发挥写摘要——万一漏掉了关键信息呢?
用 Structured Output 强制输出格式:
JSON
{
"summary": "用户要求重构 auth 模块,已完成 login/logout,待处理 token refresh",
"key_decisions": ["使用 JWT 替代 session", "refresh token 存 httpOnly cookie"],
"pending_tasks": ["实现 token refresh 端点", "添加 CSRF 防护"],
"important_context": ["项目用 Next.js 14", "数据库是 PostgreSQL"]
}
强制模型按这个结构输出,每个字段都不能省。这样压缩后的摘要是结构化的,后续 Agent 可以精确地读取 pending_tasks 来继续工作,而不是从一段自然语言里「猜」还有什么没做完。
场景二:生成式 UI
这是 Structured Output 最酷的一个应用。让模型基于 JSON Schema 来描述 UI 组件:
JSON
{
"type": "card",
"title": "天气预报",
"children": [
{ "type": "text", "content": "北京 · 晴 · 25°C", "style": "heading" },
{ "type": "chart", "data": [22, 25, 28, 26, 24], "labels": ["周一", "周二", "周三", "周四", "周五"] },
{ "type": "button", "label": "查看详情", "action": "navigate:/weather/beijing" }
]
}
前端拿到这个 JSON,直接渲染成真实的 UI 组件。模型不用写 HTML/CSS,只需要按 Schema 描述「我想要什么」,渲染层负责「怎么画」。Vercel AI SDK 的 Generative UI 就是这个思路,基于 JSON 来渲染组件 UI。
约束解码在这里的价值特别大——保证输出的 JSON 一定能被前端解析,不会出现格式错误导致页面白屏。
场景三:信息提取
从非结构化文本里提取结构化数据:
JSON
{
"name": "张三",
"company": "某科技公司",
"role": "CTO",
"contact": "zhangsan@example.com"
}
这个场景也特别常见,一个 LLM Call 就能搞定,通过 Structure Output 拿到 JSON 结构化数据。
什么时候不该用 Structured Output
推理的生成是不定的,而约束是僵硬的。
当模型在进行深度思考时,它需要极大的“表达自由度”来权衡利弊、构建逻辑链条。如果此时强制它每一步都符合严格的 JSON 格式(比如必须每行一个键值对),它可能会为了“凑格式”而牺牲掉表达的准确性,或者因为 Token 选择受限而导致逻辑中断。
有个容易踩的坑:在模型需要自由推理的阶段强制 JSON 格式,反而会降低推理质量。
约束解码在每一步都在限制 Token 的选择范围。当模型需要深度思考、权衡多个方案、做复杂推理的时候,这些限制可能影响它「想清楚」的能力。
什么意思呢?想象你在写一篇文章,但每个段落都必须严格按固定模板来。你可能为了凑格式而牺牲了表达的准确性。
所以一般的做法是:
推理阶段(Agent 在思考下一步该做什么):不用 Structured Output,让模型自由生成文本
动作阶段(Agent 决定调用哪个工具、传什么参数):用 tool_use,约束输出格式
输出阶段(需要固定格式的结果):用 Structured Output
Claude 的 tool_use 设计天然就把这两个阶段分开了:模型可以在同一次回复里先输出一段自由文本(思考过程),再输出 tool_use 块(结构化的工具调用)。文本不受约束,JSON 严格约束——各取所需。
在 Claude 的回复中,它允许模型先输出一段自由文本(Free Text),然后再输出一个 tool_use 块。
TEXT
用户:帮我查一下北京今天的天气,如果下雨就提醒我带伞。
Claude (模型输出):
好的,我先查询一下北京的天气情况。
<tool_use>
{
"name": "get_weather",
"input": { "city": "北京" }
}
</tool_use>模型先用自然语言说出了它的“思考过程”(我要去查天气),这部分是完全自由的,不受任何 JSON 格式的限制。然后,当它决定要执行动作时,才进入 <tool_use> 标签,在这里它必须严格遵守 Schema 的约束。
这种设计把“推理”和“行动”解耦了:
推理阶段:让模型像人一样自由表达,保证逻辑质量。
行动阶段:用约束解码锁死格式,保证代码能解析。
