
什么是Agent Skills?
官方定义一句话拆开来看:
Agent Skills = 一个有组织的文件夹,内含指令、脚本、资产和资源,让 Agent 能精准执行特定任务。
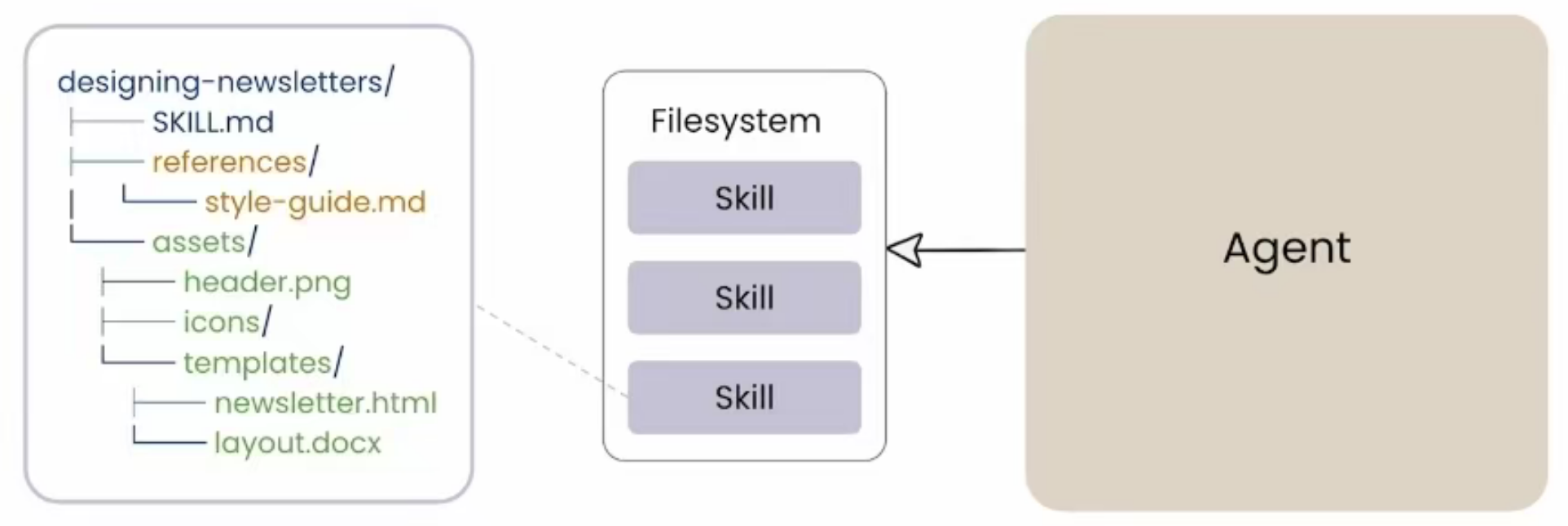
注意三个关键词:
有组织:不是随意堆文件,是结构化的知识体系
文件夹:轻量级、文件系统原生,不需要复杂基础设施
精准执行:解决的是"做对"的问题,而不只是"能做"
Skills 为什么那么重要?
用我们的大白话来说就是:**Skills = 给AI的岗前培训 + 标准作业手册 + 技能认证体系。**你想想,你给AI清晰的岗前培训资料和清晰的作业手册,和给AI一个模糊的作业手册,AI的工作产出能一样吗?答案不言而喻,你不能让模型去猜该怎么做。
这就是 Skills 的核心理念:与其教模型使用新协议,不如用它最擅长的方式——读文档。
那么如何评判一个skill是否是高质量?如何写出规范的skills技能包?
接下来我们一起分析一下:
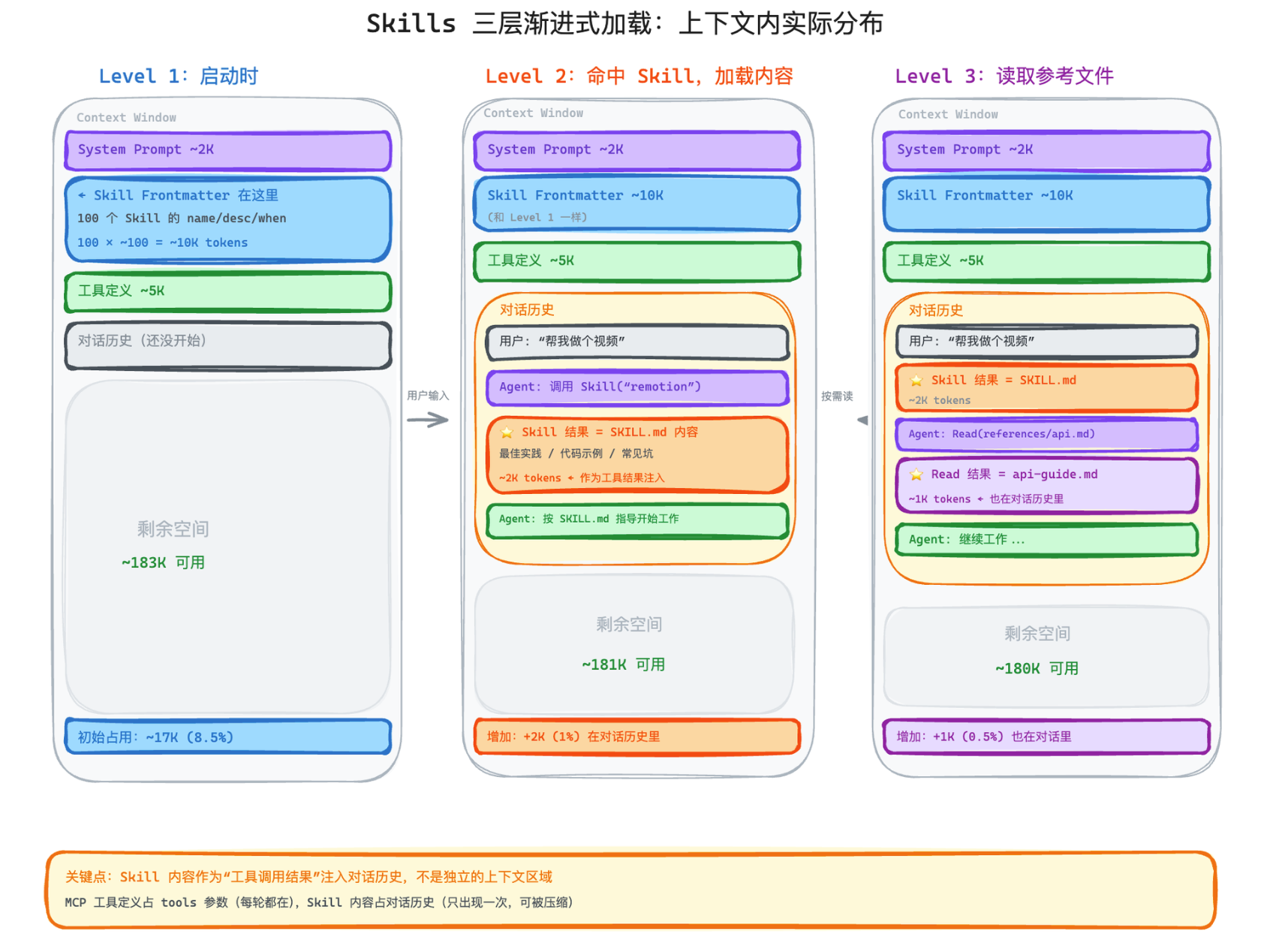
技巧一:Progressive Disclosure — 渐进式加载
Skills 系统面临一个和 MCP 一样的问题:如果你装了 100 个 Skills,不可能把所有内容都塞进上下文。
MCP 的解法是延迟加载。Skills 的解法更优雅——三层渐进式加载。
如何做:
Level 1:Frontmatter(永远加载)
Level 2:完整内容(按需加载)
Level 3:引用文件(再按需加载)
技巧二:关键词轰炸Description
Description是触发前唯一能被模型看到的门面,你想想,如果门面都写不好怎么让模型来发现你?一个好的门面要像SEO+用户原话合集。
即使你Skill写的再好,触发不到也是白搭。
写得好的 description 长什么样?
看看 ui-ux-pro-max 的 description,教科书级别的关键词轰炸:
PLAINTEXT
description: "UI/UX design intelligence. 50 styles, 21 palettes,
50 font pairings, 20 charts, 8 stacks (React, Next.js, Vue, Svelte,
SwiftUI, React Native, Flutter, Tailwind). Actions: plan, build,
create, design, implement, review, fix, improve, optimize, enhance,
refactor, check UI/UX code. Projects: website, landing page,
dashboard, admin panel, e-commerce, SaaS, portfolio, blog, mobile app.
Styles: glassmorphism, claymorphism, minimalism, brutalism..."
技巧三:工作流清单模式
用【】清单给模型轨道,关键步骤用⚠️ REQUIRED / ⛔ BLOCKING标出来
MARKDOWN
## Suggested fix pattern
```markdown
## Workflow checklist (copy and tick as you go)
- [ ] Step 0 Preferences check ⛔ BLOCKING
- [ ] Found → load → continue
- [ ] Missing → run first-time setup
- [ ] Step 1 Analyse content
- [ ] Step 2 Confirm with user ⚠️ REQUIRED
- [ ] Step 3 Generate
- [ ] Step 4 Pre-delivery checks
PLAINTEXT
# 技巧四:用脚本封装确定性操作
一句话来解释:能重复,能算准的事交给scripts/,别让模型每轮现场编一长段代码。
ui-ux-pro-max 这个 Skill 的做法就特别典型。它把所有的设计知识——50 种 UI 风格、21 种配色方案、50 种字体组合——全塞进了一个本地数据库里,然后写了个 `search.py` 脚本:
```plaintext
python3 .claude/skills/ui-ux-pro-max/scripts/search.py "beauty spa" --domain color
模型不需要去"回忆"或者"编造"配色方案,直接查就行。结果精准、一致、不会幻觉。
技巧五:给模型“该问的问题”,而不是“该找的答案”
把保证质量改为模型能对着产物回答的具体问题:是否,数量,条件等
举个反例:注意并发,遵守SOLID。若无操作化等于没说。相反,正确的做法:用可勾选,可数,可对照的问法。
一般人写 Skill 会这么写:
PLAINTEXT
检查代码是否违反了单一职责原则(SRP)。
太笼统了。模型看到这句话,可能会泛泛地说"这个类做了太多事情"之类的废话。
但如果你换成一个具体的问题:
PLAINTEXT
问自己:这个模块有几个不同的修改理由?
如果答案超过一个,它可能违反了 SRP。
效果完全不一样。模型会真正去分析代码,数一数"这个模块有几个修改理由",然后给出具体的结论。
技巧六:确认节点-别让模型自作主张
这个技巧在涉及"生成"或"修改"操作的 Skill 里特别重要。
核心思路:在关键操作之前,强制模型先停下来跟用户确认。写删改,调外部API,部署前要有结构化确认,不要一路自动到底。
baoyu-cover-image 把这个做到了极致。它有两个确认节点:
Step 0 ⛔ BLOCKING:加载用户偏好。如果是第一次用,必须完成偏好设置才能继续——不能跳过,不能默认。
Step 2 ⚠️ REQUIRED:确认五个维度(类型、配色、渲染风格、文字密度、情绪)。除非用户明确用了
--quick参数,否则必须过这关。
技巧七:Pre-Delivery(交付前自检)
这个技巧特别适合输出型的 Skill(生成代码、生成设计、生成文档)。
MARKDOWN
```markdown
## Step N — Pre-delivery self-check
- [ ] Every required tool call from earlier steps was actually performed.
- [ ] All findings reference a real rule / file / line range.
- [ ] No file was modified without the user's Step 4 consent.
- [ ] If fixes were applied, the lint script was re-run and the new
verdict is included in the report.
PLAINTEXT
在回复用户之前,用可验证的清单对照,声称做了的事是否真的做了。
# 技巧八:参数系统——让 Skill 变成"可配置工具"
用 flag / $ARGUMENTS 把「全量流水线」拆成瑞士军刀,并配 argument-hint。
- **怎么写**:用户只想 \--quick 或只评某几条规则时的体验;表格列出每个选项的默认值与语义;多模式(审查 / 模板)时更要用参数显式切换。
看看 baoyu-slide-deck 的参数设计:
```plaintext
/baoyu-slide-deck content.md --style sketch-notes --audience executives --lang zh --slides 10
/baoyu-slide-deck content.md --outline-only
/baoyu-slide-deck content.md --prompts-only
/baoyu-slide-deck slide-deck/topic/ --images-only
/baoyu-slide-deck slide-deck/topic/ --regenerate 3
它支持局部重做(--regenerate 3 只重新生成第 3 张幻灯片)、分阶段执行(--outline-only 只生成大纲)、全自定义参数。这意味着用户可以根据需要灵活组合,而不是每次都从头到尾跑一遍。
baoyu-cover-image 同样出色,5 个维度的参数各自独立,可以任意组合:
PLAINTEXT
/baoyu-cover-image article.md --type conceptual --palette warm --rendering flat-vector
/baoyu-cover-image article.md --quick # 跳过确认,全自动
/baoyu-cover-image article.md --ref style-ref.png # 带参考图
实现方式很简单——用 $ARGUMENTS 变量接收参数,然后在 SKILL.md 里说明解析规则:
PLAINTEXT
## Options
| Option | Description |
| ---------------- | ----------- |
| `--style <name>` | 视觉风格 |
| `--quick` | 跳过确认 |
| `--ref <files>` | 参考图 |
同时别忘了在 frontmatter 里加 argument-hint,这样用户输入 / 的时候能看到参数提示:
PLAINTEXT
argument-hint: [content] [--style name] [--quick]
技巧九:References 的分类组织——不是一股脑堆文件
当你的 references 文件变多之后,怎么组织就变得很重要了。
baoyu-cover-image 的 references 组织方式是我见过最讲究的:
PLAINTEXT
references/
├── palettes/ # 9 种配色方案,每种一个文件
├── renderings/ # 6 种渲染风格,每种一个文件
├── dimensions/ # 风格维度说明
│ ├── text.md
│ └── mood.md
├── config/ # 配置相关
│ ├── preferences-schema.md
│ ├── first-time-setup.md
│ └── watermark-guide.md
├── workflow/ # 工作流相关
│ ├── confirm-options.md
│ └── prompt-template.md
├── auto-selection.md # 自动选择规则
├── compatibility.md # 兼容性矩阵
└── types.md # 封面类型说明
这种按"领域"分类的组织方式有一个巨大的好处:模型只需要加载相关领域的文件。
技巧十:CLI 工具 + Skill = MCP 替代方案
这个技巧不是写 SKILL.md 的技巧,而是 Skill 的一种设计模式——用 CLI 工具来替代 MCP Server。
最典型的例子就是 agent-browser。以前要让 AI 操作浏览器,你得启动 Playwright MCP Server,20+ 个工具的定义全塞进上下文。现在呢?一个 CLI + 一个 SKILL.md:
PLAINTEXT
agent-browser open https://example.com
agent-browser snapshot -i
agent-browser click @e1
agent-browser fill @e2 "text"
SKILL.md 只需要列出命令参考,模型通过 Bash 直接调用。上下文消耗对比 MCP 减少高达 93%。
agent-browser 的 SKILL.md 很有意思,它在 frontmatter 里限制了工具权限:
PLAINTEXT
allowed-tools: Bash(agent-browser:*)
这意味着这个 Skill 只能执行以 agent-browser 开头的 Bash 命令,不能乱执行其他东西。安全性拉满。
这个模式的核心逻辑是:把复杂的协议层(MCP)替换成简单的命令行接口(CLI),再用 Skill 来教模型怎么用这些命令。
以后如果你想给 AI 添加某种能力,先想想能不能写成 CLI 工具 + Skill,而不是直接上 MCP。
写在最后
说到底,写 Skill 不是写文档,是在设计一个 AI 工作流。如果你不知道如何写一个高质量的skill 或者 你想检测一个skill 是否过关,哪里需要修改。我这里贴一下我个人的skill-review。它可以帮你检查现有skill的质量,同时可以帮助你生成高质量的skill。欢迎使用体验:
我自己 code-review-expert 的实现在这里,欢迎参考:
GitHub: https://github.com/Liu-PenPen/skill-review
安装:npx skills add Liu-PenPen/skill-review
记得点个小star哦!
