
上下文压缩到底在干嘛?
你的上下文里有这些东西:
System Prompt(身份、规则、工具定义)
对话历史(用户消息 + 模型回复)
工具调用记录(调用参数 + 返回结果)
System Prompt 不能压——压了模型就"失忆"了,不知道自己是谁、该怎么做。
所以能压的就两大块:对话历史和工具调用记录。而工具调用记录通常是大头——你读一个文件返回 3000 token,grep 一下返回 2000 token,跑个命令返回 5000 token。50 轮下来,工具结果占上下文的 60-80% 并不夸张。
理解了这个,后面的设计就好懂了——各种压缩手段本质上都是在回答同一个问题:这些工具结果和对话历史里,哪些还有用,哪些可以扔掉或者缩短?
还有一个重要的区分需要先搞清楚:Compaction 和 Summarization 是两种本质不同的策略。
Compaction(紧凑化)——不改对话结构,只缩小内容。比如把老旧的工具结果替换成 [Old tool result cleared],或者把工具调用的参数缩短,去掉 content 字段只留 path。消息还在,结构不变,只是每条消息变小了。好处是可逆——原始内容可能还在文件系统里,需要的时候能读回来。
Summarization(摘要化)——用一段 LLM 生成的摘要替换整段对话历史。消息结构被打破了,多条消息变成了一段总结文字。token 回收更多,但信息损失也更大,而且不可逆——原始对话永久丢失。
这个区分为什么重要?因为它决定了你的压缩策略应该怎么排优先级:先 Compaction,后 Summarization。 能不丢结构就不丢,能可逆就不做不可逆的操作。下面你会看到 Claude Code 和 OpenClaw 的方案都遵循这个原则。
这里提前说一下,Claude Code 的命名有点容易混淆:它的 "Microcompact" 是真正的 Compaction(就地缩小工具结果),但 "Auto-compact" 其实是 Summarization(用 LLM 生成摘要替换旧消息)。别被名字误导了,看背后实际做的事就行。
Claude Code 的三层压缩:渐进式降级
Claude Code 的压缩策略是"先试轻手段,不行再上重手段"。它把压缩分成了三层,从轻到重依次是:Microcompact → Snip → Auto-compact。
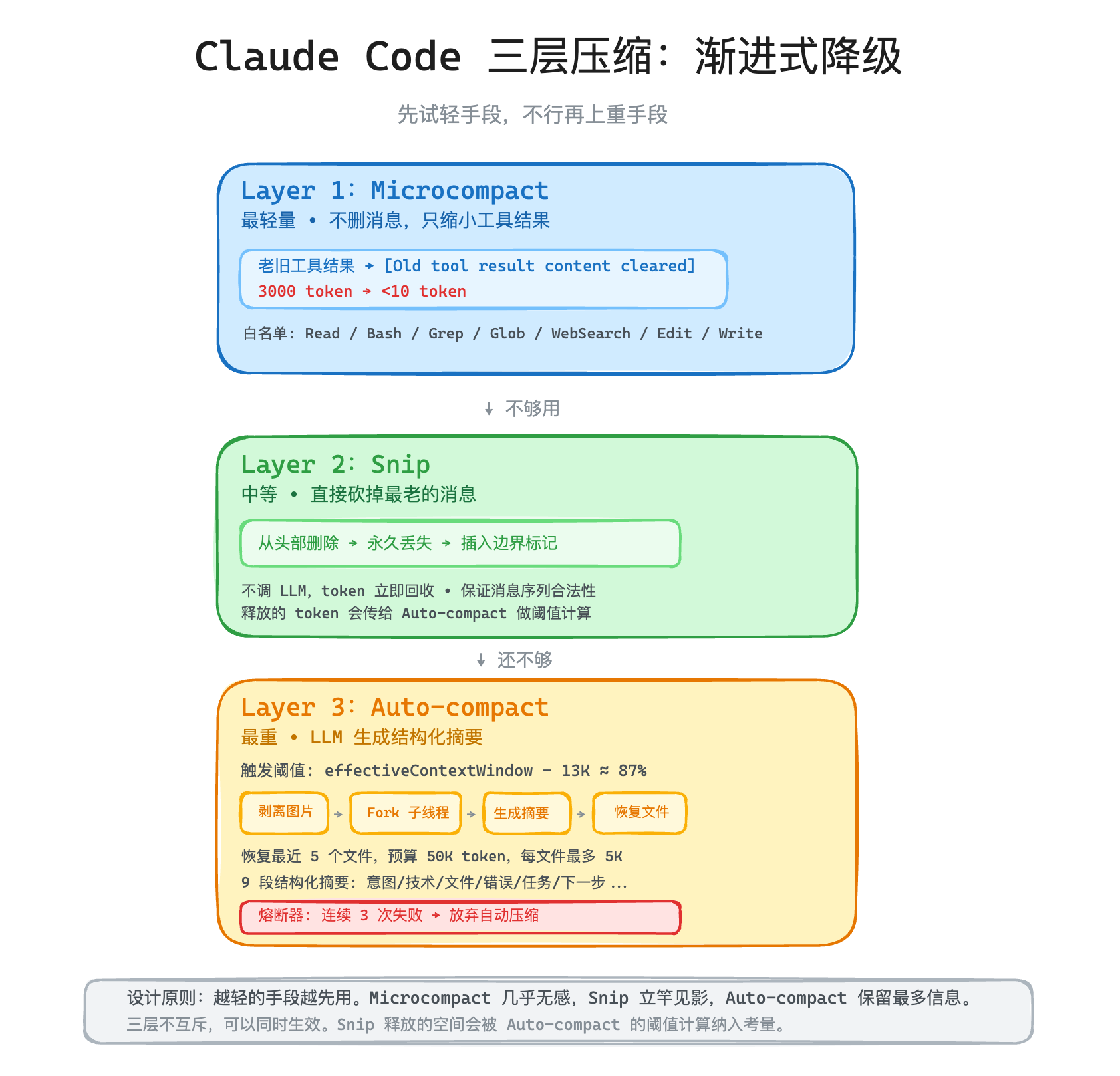
Layer 1:Microcompact——在工具结果上"动刀"
这是最轻的一层。它不删消息,不改对话结构,只是把老旧的工具结果缩小。
Microcompact 的做法是:不删消息,只替换工具结果的内容。把那 3000 token 的文件内容替换成一句话——[Old tool result content cleared]。消息结构完好无损,但 token 占用从 3000 降到了不到 10。
哪些工具的结果可以被清理?Claude Code 定义了两类白名单:一类是清理工具返回结果的——Read、Bash(shell 命令)、Grep、Glob、WebSearch、WebFetch,这些查询类工具的结果是一次性的;另一类是清理工具调用参数的——Edit、Write,因为它们的输入参数(文件完整内容)往往比返回值更大。两类加在一起,覆盖了绝大部分的 token 大户。
这一层的触发时机也很巧妙——它不是等上下文快满了才触发,而是会在 Claude API 根据 token 使用情况,自动清理旧的工具结果,客户端几乎无感。这个就和 Claude 内部 API 的实现绑定了,API 内部的上下文阈值设置为多少我们不得而已,但这个思路你能 get 到就可以。
还有一个有意思的细节:Microcompact 会保留最近 N 轮的工具结果不动。因为最近几轮的结果很可能还在被模型引用——你刚读的文件、刚跑的命令,模型下一步可能还要用。换句话会所就是只清理"足够老"的结果。
Layer 2:Snip——直接砍掉老消息
如果 Microcompact 之后上下文还是太大,上第二层:直接砍掉最老的消息。
Snip 的逻辑很简单粗暴——从对话历史的头部开始删,保留尾部(最近的上下文)。被删掉的消息永久丢失,不做任何摘要。
Snip 之所以这么暴力,是因为它的定位就是"快速释放空间"。它不调用 LLM 生成摘要(那本身就要花 token 和时间),直接把最老的消息扔掉,token 立即回收。
但 Snip 不是随便砍的。它要保证砍完之后,消息序列还是合法的——API 要求第一条消息必须是 user 角色,而且 tool_use 和 tool_result 必须成对出现。所以 Snip 在砍的时候要小心处理边界,确保 tool_use 和 tool_result 能成对保存,不会产生"孤儿"消息,否则就会导致 LLM API 直接报错。
Snip 砍完之后会插入一个边界标记,告诉模型:"前面的对话历史被截断了。"模型看到这个标记就知道自己可能遗漏了一些早期信息,会更谨慎地做判断。
一个关键设计:Snip 和 Microcompact 不是互斥的,它们可以同时生效。先跑 Microcompact 清理工具结果,再跑 Snip 砍老消息。Snip 释放的 token 数量会被传给下一层的 Auto-compact,让它在判断"要不要触发"时考虑到 Snip 已经做过的工作。
Layer 3:Auto-compact——用 LLM 生成摘要
前两层都是"无损"或"有损但简单"的操作。第三层上大招——调用 LLM 对整个对话做一次摘要压缩。
这是最重的操作,但也是信息保留最好的。
什么时候触发?
Claude Code 有一个精确的阈值公式:
PLAINTEXT
触发阈值 = effectiveContextWindow - 13K(缓冲)
effectiveContextWindow 是上下文窗口大小减去摘要输出预留的 20K token。对于 200K 窗口的模型,大概是在 167K token 时触发。换算一下,大约是上下文窗口的 87% 左右。
接下来我们就来拆开 Auto-compact 的内幕,跟你详细讲讲。整个压缩流程有 5 个关键步骤:
第一步:剥离图片。 图片 token 极其昂贵(一张图可能几千 token),而且对生成摘要来说没有意义。Claude Code 把所有图片块替换成 [image] 文本标记,保留"这里有张图"的信息,但不再占用 token。文档类附件也同样处理。
第二步:Fork 一个子线程生成摘要。 这是一个非常重要的设计——摘要生成不在主循环里跑,而是在一个独立的 forked agent 线程里跑。为什么?因为摘要生成可能需要几秒甚至十几秒,如果在主循环里跑,Agent 就会卡住——用户在等,什么都做不了。放在子线程里,主循环可以继续响应用户。
第三步:生成摘要。 这一步是整个 Auto-compact 的核心。LLM 收到的指令要求它先写一段 <analysis> 分析(按时间顺序梳理每一轮做了什么),再写 <summary> 摘要。分析部分在后处理时会被剥离,只保留最终摘要。摘要本身是一个严格的 9 段结构——用户意图、技术概念、文件改动、错误修复、问题解决、用户消息、待办任务、当前工作、下一步。
也就是说,让 LLM 像填表一样,把这九小段内容给填进去,保证压缩内容的完整和稳定。
第四步:恢复关键文件。 压缩完之后,模型的上下文里只剩摘要和最近几轮对话。但有个问题——如果模型之前在读某个文件并且正在修改它,压缩后它就"忘了"文件内容。
所以 Claude Code 会在压缩后重新附加最近读过的 5 个文件的内容,每个文件最多 5K token,整个恢复阶段(文件 + skills)的总预算是 50K token。这确保模型不会因为压缩就"失忆"正在操作的文件。
第五步:替换消息。 把旧的消息列表替换成下面的结构:
PLAINTEXT
[压缩边界标记]
[摘要]
[恢复的文件]
[最近的对话]
如果压缩本身失败了呢?可能是网络问题,可能是摘要生成被中断了。Claude Code 会重试,但连续 3 次失败后直接放弃,不再尝试自动压缩。
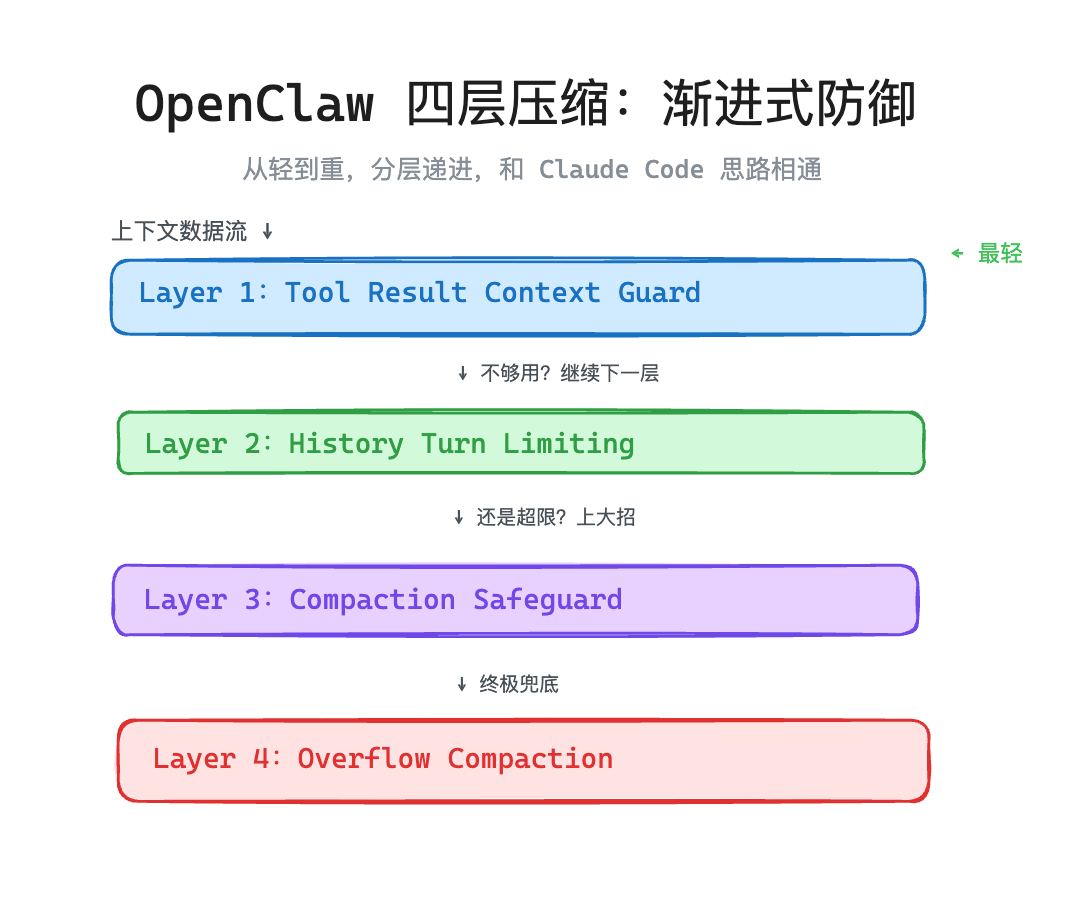
OpenClaw 的四层压缩:渐进式防御
OpenClaw 的思路其实和 Claude Code 相通——也是分层递进,从轻到重。它把压缩分成了四层,从轻到重依次是:
Tool Result Guard:截断工具结果。
History Limiting:裁剪历史对话内容。
LLM Compaction:用 LLM 来做摘要。
Overflow Retry:如果上面压缩过的内容还是太大,那么启动这一步终极兜底,后面会讲具体措施。
接下来我们一层层来拆解。
Layer 1:Tool Result Context Guard——工具结果实时截断
这是最前置的一层防线。和 Claude Code 的 Microcompact 定位类似,但机制完全不同。
OpenClaw 不是等老旧的工具结果"过期"了再清理,而是在每次准备发送上下文给模型之前(transformContext 阶段),就对所有工具结果做实时检查和截断。
关键区别在于:截断限制不是固定的,而是基于当前模型的上下文窗口动态计算的:
单个工具结果上限:上下文窗口的 50%(按 tool result 的 2 chars/token 换算)
总上下文预算:上下文窗口的 75%(按通用的 4 chars/token 换算)
超限的时候,先对单条做截断——在内容的 70% 位置找最近的换行符切断,附加 [truncated: output exceeded context limit]。
如果截完单条还是超预算呢?OpenClaw 会从最老的 tool result 开始,逐条替换成一句话:[compacted: tool output removed to free context]。从老到新一条条替换,直到总上下文回到预算内。
这个设计背后有一个关键洞察:老的工具结果几乎一定比新的更没用。你 5 分钟前读的文件内容,大概率已经不影响当前决策了。所以从最老的开始清理,信息损失最小。
Layer 2:History Turn Limiting——历史轮次裁剪
这一层和 Claude Code 的 Snip 定位类似——砍掉最老的对话,给上下文腾空间。
但 OpenClaw 是按轮次计数而不是按 token 数来决定砍多少。它保留最近 N 轮 user turn 及其关联的 assistant 回复和 tool result,更早的直接丢弃。
裁剪后会做一轮 tool_use/tool_result 配对修复——因为裁掉老消息可能产生"孤儿" tool_result(它对应的 tool_use 在被裁掉的 assistant 消息里),这种孤儿消息会导致 API 报错。这部分跟我们上面的 Claude Code 一模一样。
Layer 3:Compaction Safeguard——LLM 结构化摘要
这是整个压缩系统的核心,也是和 Claude Code 差异最大的地方。
触发时机跟 Claude Code 类似——pi-coding-agent(pi 框架的包,我们在"回到框架"这一章会展开说,暂时不用深究) 框架检测到上下文接近窗口上限时自动触发。
第一步:分离"可压缩"和"要保留"的消息。 默认保留最近 3 轮对话不动(可配,最大 12 轮)。保留的消息包括完整的 user/assistant 交互及其关联的 tool result。剩下的才进入压缩流程。
第二步:Token 估算与分段。 这里 OpenClaw 用 chars / 4 的启发式方法估算 token 数,加 1.2x 安全系数(因为中文等多字节字符会被低估)。然后把消息切成多段,每段不超过模型能处理的范围。
第三步:分段摘要 → 合并。 每段独立调用 LLM 做摘要,多段再合并成最终版本。这解决了"要压缩的对话可能比模型输入还大"的问题。
第四步:结构化输出。 这是 OpenClaw 最独特的设计——摘要不是自由文本,而是必须包含 5 个固定 section:
## Decisions——做了哪些决策## Open TODOs——还有哪些待办## Constraints/Rules——有什么约束和规则## Pending user asks——用户还有什么未回应的请求## Exact identifiers——关键标识符的精确值
这比 Claude Code 的 9 段结构更精简,但每一项都直接对应 Agent 继续工作所需的核心信息。
第五步:质量守卫。 摘要生成后,OpenClaw 会做质量检查:检查 5 个 section 是否齐全、关键标识符是否被完整保留、最近一次用户请求是否在摘要中有所体现。不通过就重试,最多 3 次。
关于标识符保留行为,这里展开说一下。OpenClaw 在 Agent 配置文件的 compaction.identifierPolicy 字段里提供了三种策略:strict(默认,要求摘要必须原样保留所有 UUID、hash、API key 等等)、off(不注入任何标识符保留指令)、custom(自定义规则,通过 compaction.identifierInstructions 传入)。默认 strict 够用了,只有在你明确想放宽或者有特殊标识符格式时才需要切到 custom。
Layer 4:Overflow Compaction——溢出重试
如果前面三层都没能把上下文压到窗口以内,模型 API 会返回 context overflow 错误。这时 OpenClaw 进入最后的兜底机制:
检测到溢出错误后,最多重试 3 次。
每次重试都会再跑一轮 Compaction。
如果 3 次压缩都不够,最后手段——激进的工具结果截断,把所有大的 tool result 一次性砍到极限。简单粗暴,求生欲拉满。
整个流程有一个 5 分钟的硬性超时——防止 LLM 摘要调用 hang 住整个 session。
Manus 的"可恢复压缩 + 文件系统卸载"
除了 Claude Code 和 OpenClaw,Manus 的 Context Engineering 博客里提到了一个非常值得说的理念——所有压缩都应该是可恢复的。
什么意思?Manus 给每个工具调用维护两个版本:完整版和紧凑版。完整版是原始工具输出,存在 sandbox 文件系统里;紧凑版只保留一个引用,比如文件路径。随着对话推进,老的工具结果从完整版切换到紧凑版。
关键在于:信息没有真正丢掉,只是暂时不在模型的"视野"里。需要的时候,模型可以通过文件路径把完整内容读回来。上下文是可逆、可恢复的。
这就引出了 Manus 更大的一个洞察——把文件系统当成"外挂大脑"。上下文窗口有 token 限制、有性能衰减、费钱。但文件系统呢?大小不受限,天然持久化,Agent 可以直接读写。
所以 Manus 的 Agent 会主动把信息写到文件里——搜索结果存成文件、中间状态写到 todo.md、分析报告保存到 sandbox。上下文里只留引用,需要时再读回来。这本质上就是把"压缩"变成了"卸载"——不是删信息,是把信息搬到更便宜的存储介质上。
Cursor 也是同样的思路——大输出写文件,Agent 用 grep / tail 按需读取。他们的 A/B 测试显示 token 消耗减少了 46.9%,模型表现反而更好了。
一个被忽视的设计原则:保留错误
说完了各家的压缩方案,有一个反直觉的原则值得强调:
失败尝试是最好的学习样本,不要轻易擦除。
什么意思?如果模型在第 10 轮尝试了一种方案但失败了,在第 15 轮换了另一种方案成功了。你在压缩时把第 10 轮的失败记录删了,模型到第 30 轮可能又会去尝试那个已经失败过的方案——因为它不记得了。
有个细节,Claude Code 的 Auto-compact 在生成摘要时,prompt 里有一条明确的指令:"Errors that you ran into and how you fixed them"——要求摘要必须保留"遇到了什么错误以及怎么修复的"。
