
这篇要讲的是一个更底层、更容易被忽略的问题:当你的 Agent 是一个真实产品的时候,system prompt 不是你手写一段话就完事了——它需要被当成一个工程系统来设计。
怎么把 prompt 拆成可维护的模块?哪些部分该缓存、哪些部分每轮要变?用户想自定义 Agent 行为怎么办?有些上下文信息变化太快放哪里?这些才是做 Agent 产品时真正要解决的问题。
快速对齐认知
Chat Prompt 追求"回答质量"——问一个问题,给一个好答案。
Agent Prompt 追求"行为稳定性"——模型可能连续跑 50 轮,每一轮都要做出正确决策。
所以 Agent 的 system prompt 不是"提示词",而是一套行为控制系统。你不是在"提示"模型,你是在"编程"模型的行为模式。
问题一:Prompt 怎么分模块?
你的 Agent prompt 一开始可能长这样:
TYPESCRIPT
const systemPrompt = `你是一个代码助手。
帮用户完成编程任务。先读文件再修改。
不要加没被要求的功能。执行危险命令要确认。
输出要简洁,不要用 emoji……`
一个大字符串,改一处牵一发动全身。身份定义、行为规则、工具指南、输出风格全揉在一起。
第一个要解决的问题是模块化——把 prompt 拆成独立的 section,每个 section 职责单一:
TYPESCRIPT
// 每个 section 是一个独立的字符串,最后拼成数组
const systemPrompt = [
identitySection(), // "你是 XX,负责 YY"
systemRulesSection(), // 环境约束:权限、压缩、标签
taskGuidelines(), // 做事方式:先读再改、不过度发挥
riskGuidelines(), // 行动准则:什么操作要确认
toolUsageGuide(tools), // 工具指南:根据实际工具列表动态生成
outputStyle(), // 输出风格:简洁、格式要求
]
为什么要这么做?三个好处:
独立修改——改"输出风格"不会影响"行为规则"
条件组装——某些 section 可以按环境决定要不要包含
缓存友好——马上要讲
这个设计跟你写代码一个道理——单一职责原则。prompt 也是代码,也需要模块化。
但是有个更好的设计——Prompt Pipe。
核心思路:每个 section 不是一个简单的字符串,而是一个函数。它接收当前的上下文信息(用户状态、可用工具、记忆等),自己判断要不要输出内容。要输出就返回一段 prompt 字符串,不需要就返回 null。
先看类型定义和 Builder:
TYPESCRIPT
// 上下文:每个 Pipe 都能拿到的运行时信息
interface PromptContext {
memories: Memory[]
capabilities: string[]
modelId?: string
webSearchEnabled?: boolean
// ...根据业务扩展
}
// Pipe:一个函数,拿到上下文,返回 prompt 片段或 null
type PromptPipe = (ctx: PromptContext) => string | null
// Builder:把多个 Pipe 串起来,过滤掉 null,拼成最终 prompt
class PromptBuilder {
private pipes: PromptPipe[] = []
constructor(private ctx: PromptContext) {}
pipe(fn: PromptPipe): this {
this.pipes.push(fn)
return this
}
build(): string {
return this.pipes
.map(fn => fn(this.ctx))
.filter(Boolean)
.join('\n\n')
}
}
然后每个 Pipe 就是一个独立的文件,逻辑自包含。比如一个"核心规则" Pipe,不依赖任何上下文,永远返回:
TYPESCRIPT
// prompt-pipes/core-rules.ts
export const coreRules: PromptPipe = () => `## Core Rules
1. 先读文件再修改,不要凭记忆改代码
2. 不要加没被要求做的功能
3. 三行相似代码比过早抽象好
...`
再看一个"条件返回"的 Pipe——工具配额用完了才返回内容,正常情况下返回 null,prompt 里完全不会出现这段:
TYPESCRIPT
// prompt-pipes/tool-availability.ts
export const toolAvailability: PromptPipe = (ctx) => {
const notices: string[] = []
if (ctx.webSearchEnabled === false) {
notices.push('搜索工具不可用,用户配额已满。不要尝试搜索。')
}
if (notices.length === 0) return null // 没有限制?整段消失
return `## Tool Availability\n\n${notices.join('\n')}`
}
最后组装——一行一个 Pipe,清清楚楚:
TYPESCRIPT
export function buildSystemPrompt(ctx: PromptContext): string {
return new PromptBuilder(ctx)
.pipe(coreRules) // 核心规则,永远返回
.pipe(taskGuidelines) // 做事方式,永远返回
.pipe(toolAvailability) // 工具可用性——有限制才出现
.pipe(dueReviews) // 待复习内容——没有就跳过
.pipe(userMemory) // 用户记忆——有就注入,没有就跳过
.pipe(securityRules) // 安全规则,永远返回
.build()
}这个模式灵活在哪?
第一,每个 Pipe 自己决定要不要出现。你不需要在外面写一堆 if-else 来决定哪些 section 要包含。每个 Pipe 内部自己看上下文、自己判断。条件逻辑和 prompt 内容放在一起,不会散落在各处。
那如果不用这种方式会怎么样?按照我之前的经验,一个复杂的 agent,各种条件判断,各种 prompt section,很多时候一个 prompt 文件可以堆到上千行,大量的字符串模板和三元表达式,非常混乱。
而用了 pipe 之后,各个 section 天然分离,非常好维护。
第二,加新 section 零摩擦。写一个新文件,导出一个函数,在 Builder 链条里插一行 .pipe(xxx) 就完事。不用改任何已有代码。
第三,对测试友好。每个 Pipe 是个纯函数,mock 一个 PromptContext 就能独立测试。
问题二:什么该缓存,什么不该?
你仔细想想,上面这些 section 里有两类内容:
静态内容——身份定义、行为规则、工具使用指南、输出风格。这些对所有用户、所有项目、所有会话都一样。
动态内容——当前工作目录、用户的自定义规则、语言偏好、哪些 MCP Server 连上了、Memory 里有什么。这些每个用户、每次会话都不同。
如果你把整个 system prompt 当成一个整体,任何动态内容变一个字,整个 prompt 的 KV Cache 就失效了。几千 token 的静态内容被白白重新计算。
解法是:在静态和动态之间画一条明确的分界线。
用代码来表示就是这样:
TYPESCRIPT
const systemPrompt = [
// ---- 静态部分:全局可缓存,所有用户共享 ----
identitySection(), // "你是 XX,负责 YY"
systemRulesSection(), // 环境约束
taskGuidelines(), // 做事方式
riskGuidelines(), // 行动准则
toolUsageGuide(tools), // 工具指南
outputStyle(), // 输出风格
// ======== 分界线 ========
// ---- 动态部分:每会话不同 ----
envInfo(cwd, gitStatus), // 工作目录、Git 状态
userConfig(claudeMd), // 用户自定义规则
languagePref(lang), // 语言偏好
memoryContext(memories), // Memory 内容
]
静态部分全部放前面,做全局缓存,命中率极高。动态部分放后面,变化只影响自身,不连累前面的缓存。
这个思路是通用的。不管你用什么模型、什么 API,只要支持 Prompt Cache(现在主流 API 都支持了),就把不变的部分推到前面当 cache prefix,变的部分放后面。
问题三:用户怎么自定义 Agent 行为?
你不可能把所有需求写死在代码里。用户需要一种机制来注入自己的规则——"这个项目用 pnpm 不用 npm""代码风格遵循 Airbnb 规范""这个目录下的文件不要动"。
这本质上是一个配置分层问题。核心设计原则:
越通用的配置优先级越低,越具体的优先级越高
低优先级先加载,高优先级后加载——因为模型对 prompt 末尾的注意力更强
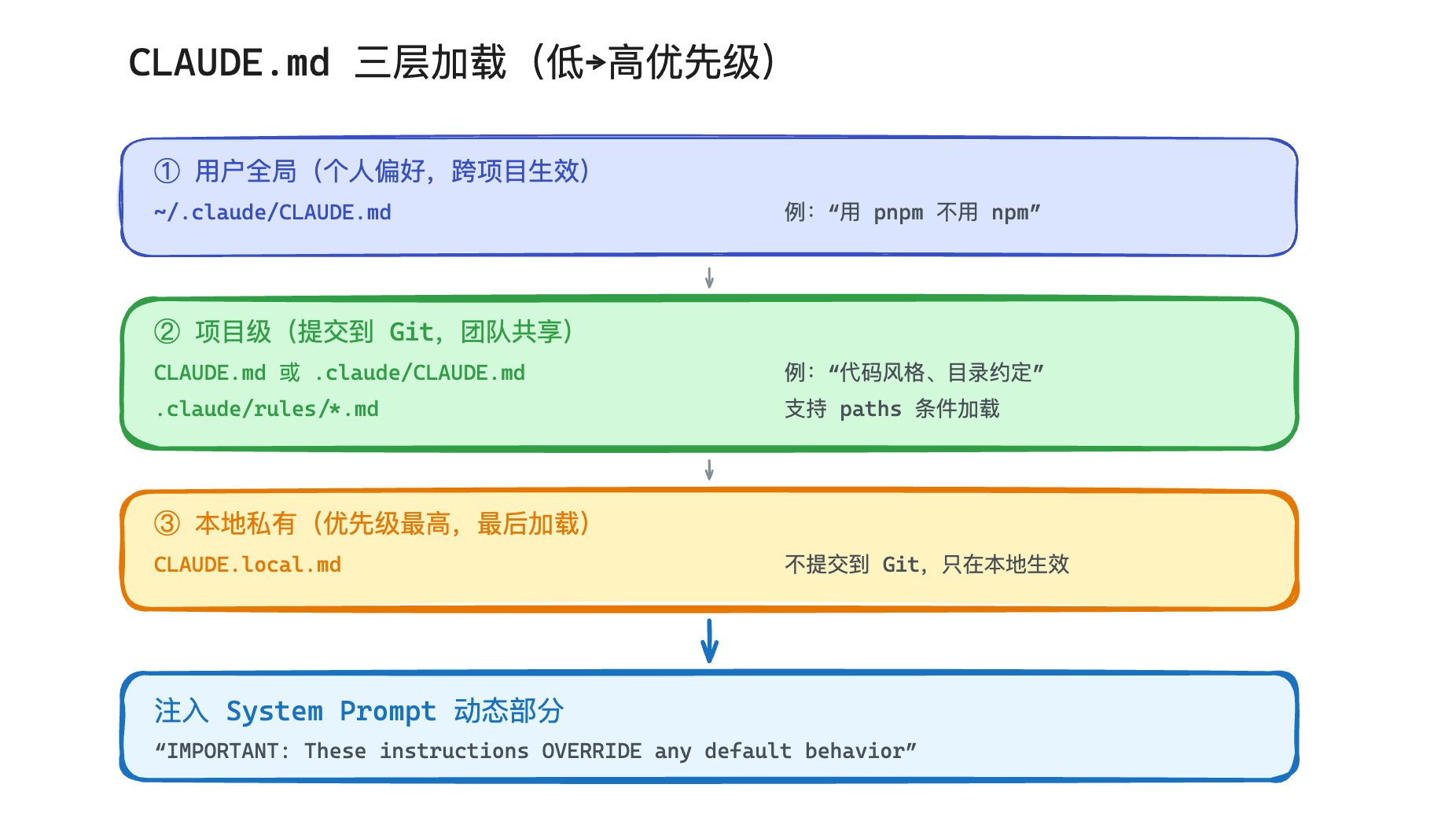
Claude Code 的 CLAUDE.md 做了三层,给你感受一下实际的用法:
MARKDOWN
# ~/.claude/CLAUDE.md(用户全局,跨项目生效)
- 用 pnpm 不用 npm
- 不要自动 git commit
- 遵循 SOLID 原则
MARKDOWN
# 项目根目录/.claude/CLAUDE.md(项目级,提交到 Git,团队共享)
- 这是一个 Next.js 项目,用 App Router
- 组件放 src/components/,页面放 src/app/
- 样式用 Tailwind,不要写 CSS 文件
- @src/docs/api-conventions.md
MARKDOWN
# CLAUDE.local.md(本地私有,不提交 Git)
- 我在重构 auth 模块,改动时要特别小心
- 调试时用 3001 端口
加载顺序从上到下,后加载的优先级更高。用户偏好打底,项目规则覆盖,本地私有最高。
这个分层逻辑是通用的——用户偏好 < 项目规则 < 本地覆盖。跟 CSS 的优先级、Git config 的 global/local 是同一个设计模式。
如果你在做自己的 Agent 产品,有一个细节特别值得注意:注入用户配置时,要明确告诉模型"这些指令覆盖默认行为"。不加这句的话,模型可能在你的默认规则和用户规则之间"精神分裂"——一会儿听这边的,一会儿听那边的。
问题四:高频变化的信息放哪?
system prompt 有一个天然限制:它是 API 调用时传进去的,一轮对话确定后就不变了。
但有些信息每一轮都在变:用户 IDE 里正在看哪个文件、哪些 Skill 跟当前任务相关、上一个工具调用触发了什么 Hook……这些如果塞进 system prompt,就会破坏缓存。
解决思路是:在对话消息流里注入,而不是在 system prompt 里注入。
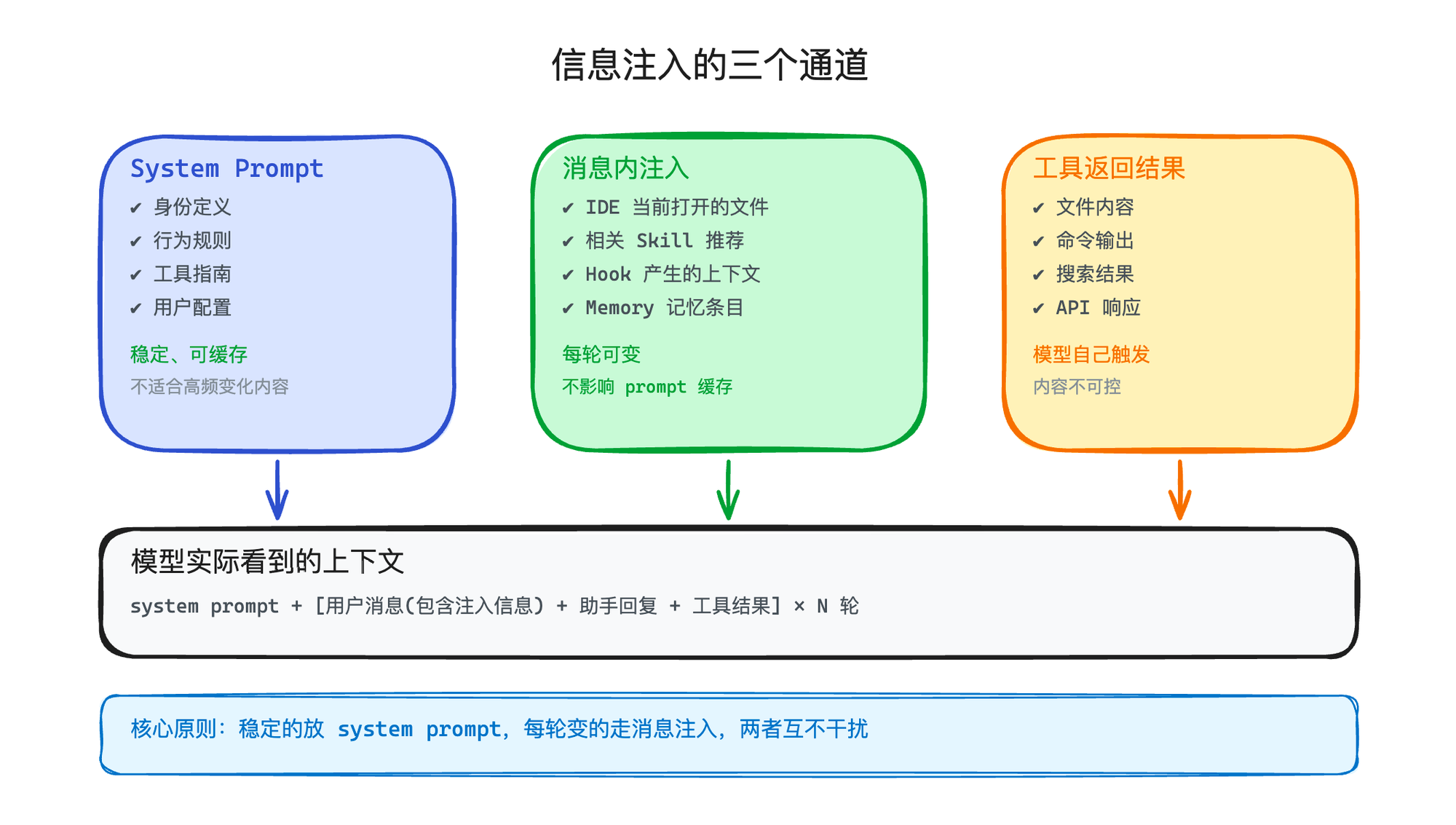
看一下实际的消息结构,你就明白了:
TYPESCRIPT
// 用户实际发送的消息
const userMessage = "帮我看看 auth.ts 有什么问题"
// 系统在发送给模型之前,会在消息里注入额外上下文
const enrichedMessage = `
<system-context>
当前 IDE 打开的文件:src/auth.ts (第 42 行)
相关 Skill:@security-review(安全审查最佳实践)
今天日期:2026-04-07
</system-context>
帮我看看 auth.ts 有什么问题
`
模型会理解 <system-context> 里的内容是辅助信息,不是用户说的话。你可以用任何 XML 标签,只要在 system prompt 里提前告知模型这些标签的含义就行。
这种"消息内注入"有三个好处:
不影响 system prompt 缓存——根本没动 system prompt
每轮可以不同——跟随当前上下文动态变化
不额外增加 turn——附加在已有的用户消息里,不打乱对话结构
典型的注入内容:
延迟加载工具的元信息
相关 Skill
Memory 系统推荐的记忆内容
更进一步:可插拔的上下文引擎
上面讲的都是"怎么组装 prompt"。但还有一个更宏观的问题:整个上下文管理策略能不能替换?
如果你在做平台型产品,不同场景可能需要完全不同的上下文策略——有的需要 RAG 检索历史对话,有的需要激进压缩,有的需要多会话共享上下文。
OpenClaw 的做法是把整个上下文管理抽象成一个可插拔接口,这个设计比较好,给大家看下接口内容:
TYPESCRIPT
interface ContextEngine {
// 会话开始:导入历史上下文
bootstrap(sessionId: string): Promise<void>
// 每条消息进来:存入引擎
ingest(message: Message): Promise<void>
// 组装上下文:在 token 预算内选最相关的内容
assemble(messages: Message[], tokenBudget: number): Promise<{
messages: Message[] // 组装好的消息列表
systemPromptAddition?: string // 可选:动态追加到 system prompt
}>
// 超限时压缩
compact(tokenBudget: number): Promise<void>
// 每轮结束后清理
afterTurn(): Promise<void>
}
默认实现就是简单透传——消息列表原样给模型。但你可以替换成任何策略,比如做一下 RAG 召回:
TYPESCRIPT
// 用向量数据库做 RAG 检索
class RAGContextEngine implements ContextEngine {
async assemble(messages, budget) {
// 不是把所有历史消息都塞进去
// 而是用语义检索找出最相关的历史片段
const relevant = await this.vectorDB.search(
messages[messages.length - 1].content,
{ topK: 10, budget }
)
return { messages: [...relevant, ...recentMessages(messages, 5)] }
}
}
而且 assemble 返回的 systemPromptAddition 意味着上下文引擎不只管消息历史,还能动态影响模型的行为指令,非常灵活。
聊聊 Context Rot
上面讲了怎么组装 prompt、怎么缓存、怎么注入。你可能觉得:有必要搞这么复杂吗?
有必要。因为 Agent 面临一个聊天机器人不会遇到的问题——Context Rot(上下文腐化)。
你的 Agent 跑着跑着就"失忆"了
用过 Claude Code 或 Cursor 的同学应该有体感:Agent 在前 10 轮特别灵,到了第 30 轮开始变迟钝,第 50 轮有时候会做出莫名其妙的决策——忘了之前读过的代码,重复之前已经做过的操作,甚至开始编造信息。
这不是模型变笨了,而是上下文变脏了。
学术界管这个叫 "Lost in the Middle"——模型对上下文头部和尾部的信息注意力最强,中间的内容会被逐渐忽略。上下文越长,中间的"盲区"越大。
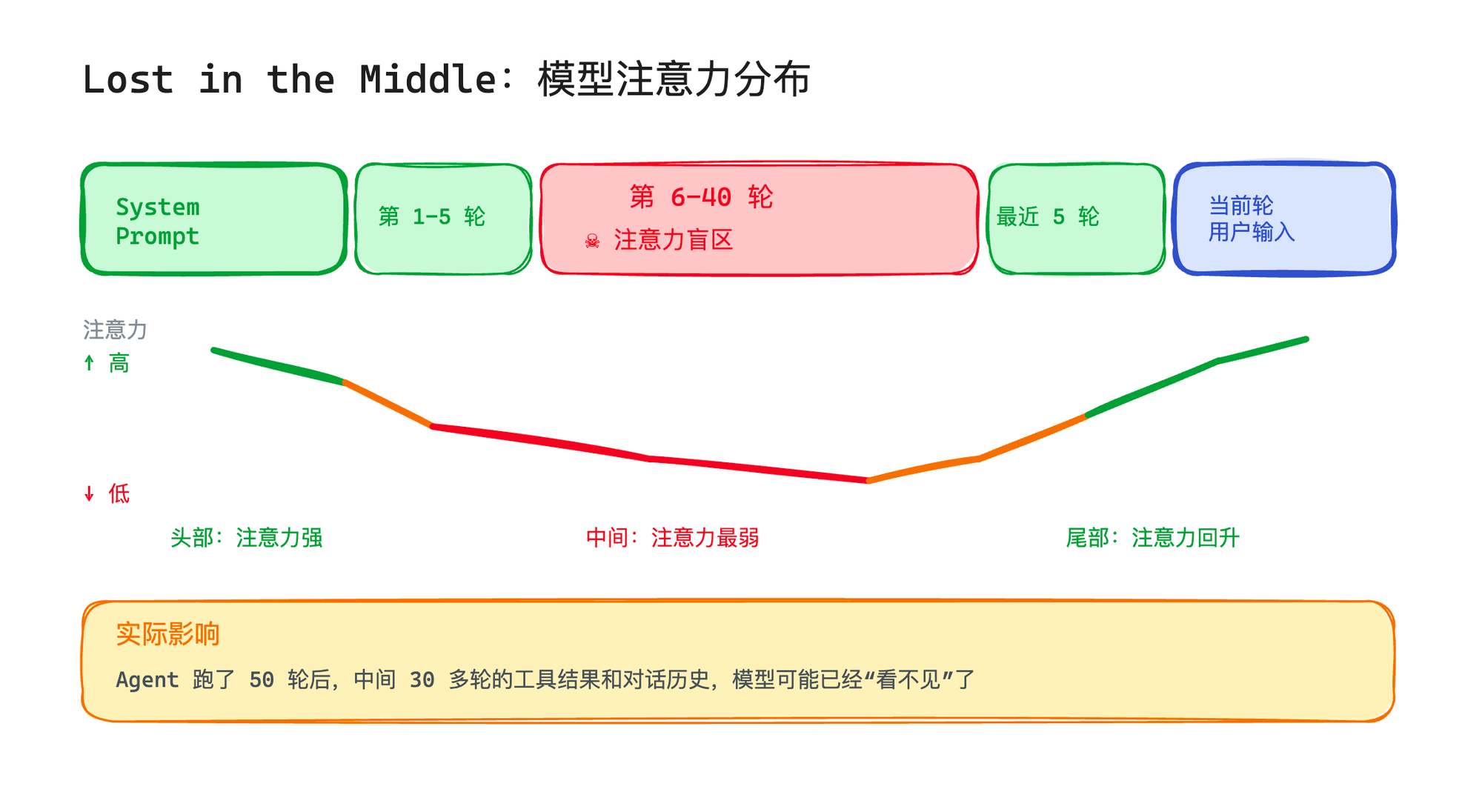
这意味着什么?你的 Agent 跑了 50 轮之后,中间那 30 多轮的工具结果、对话历史,模型可能已经"看不见"了。它还在正常运转,但做决策的依据只剩下最开始的 system prompt 和最近几轮的内容。
最好的压缩是不需要压缩
所以现在你理解了,前面讲的那些设计——模块化、缓存分层、消息注入——本质上都是在做一件事:控制入口,减少不必要的上下文消耗。
Prompt Pipe 模式里,没用的 section 返回 null 自动消失——这就是入口管理。
静态/动态分界线,让静态部分走缓存——不光是为了省钱,也是为了把宝贵的"活"上下文空间留给真正有用的信息。
消息内注入只附带当前轮相关的信息——不是上来就把所有 Skill、所有 Memory 都塞进去。
这个思路跟我们之前讲过的工具系统是一脉相承的:
Deferred Tool Loading:不是一开始就把 50 个工具的完整 Schema 塞进去,而是只放名字和提示,按需加载。这就是工具层面的入口管理。
Tool Profile:不同场景只暴露该场景需要的工具子集。也是入口管理。
Progressive Disclosure:Skills 分三层渐进加载——frontmatter、完整内容、引用文件。还是入口管理。
与其等上下文爆了再去压缩,不如一开始就少放东西。 这是 Context Engineering 的第一性原理。
