
三个"Cache",三个层次
但很多人搞不清楚"Cache"到底指什么。你去搜这个话题,会看到 KV Cache、Prompt Cache、Context Collapse、cache_control、ephemeral……一堆概念混在一起。先把概念分清楚。这三个 Cache 在完全不同的层次上工作:

KV Cache:模型推理层
这是最底层的 cache,在模型推理引擎内部做的事。
你每次给模型发一条消息,模型要对整个输入做 Attention 计算——算出每个 token 和其他所有 token 的关系。这个计算非常昂贵。
KV Cache 做的事情是:如果你这次发的输入和上次有一段共同的前缀,那这段前缀的 Attention 计算结果可以直接复用,不用重新算。
举个例子。你的第一轮对话发了 system prompt(5K token)+ 用户消息(100 token)。模型对这 5100 token 做了完整的 Attention 计算。第二轮你发了 system prompt(还是那 5K)+ 第一轮历史 + 新消息。因为前面那 5K 的 system prompt 没变,KV Cache 就能复用第一轮算过的结果,只需要对新增的部分做计算。
开发者能控制 KV Cache 吗? 不能直接控制。它由模型提供商的推理引擎管理。但你能间接影响它——让你的输入前缀尽可能稳定。这就是为什么第 14 篇讲的"静态/动态分界线"那么重要:静态部分放前面当前缀,前缀不变,KV Cache 就能命中,推理速度更快。
Prompt Cache:API 层
这是你作为开发者能直接控制、ROI 最高的一层。
Prompt Cache 是 API 提供商提供的一个计费优化。它的逻辑是:如果你的请求里有一段内容之前发过,API 只会收一个大幅折扣的"缓存读取"价格。
先用一个具体的 API 请求来看看 Prompt Cache 到底是什么样的。以 Anthropic 的 API 为例:
JSON
{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": "你是一个代码助手。以下是行为规则……(几千 token 的规则)",
"cache_control": { "type": "ephemeral" } // 👈 关键:标记缓存断点
}
],
"messages": [
{ "role": "user", "content": "帮我看看 auth.ts" }
]
}
cache_control: { type: "ephemeral" } 这个标记告诉 API:把这个 block 及之前的所有内容缓存起来。下次请求如果这段前缀没变,直接复用缓存,不收全价。
效果有多大?看一下各家的定价和缓存模式:
提供商 | 缓存模式 | 命中折扣 | TTL |
|---|---|---|---|
Claude (Sonnet/Opus) | 显式标记 | 90% off | 5min / 1h |
OpenAI (GPT-5/GPT-5.5) | 隐式缓存 | 75~90% off | 5-10min |
DeepSeek V4 | 隐式缓存 | 99% off | 数小时~数天 |
Gemini 3 | 双模式支持 | 75% off(含存储费) | 1h |
Qwen 3.6 | 双模式支持 | 80~90% off | 5min |
MiniMax M2 | 隐式缓存 | ~80% off | 未公开 |
豆包 2.0 | 显式创建对象 | 80% off | 1h~7d |
智谱 GLM-4.6/5.x | 隐式缓存 | ~80% off | — |
注意各家的缓存方式不一样。归纳起来其实就三种模式:
隐式缓存(OpenAI、DeepSeek、MiniMax、智谱)——代码什么都不用改,API 自动检测前缀匹配。OpenAI 要求前缀至少 1024 token,DeepSeek 最小单元只有 64 token。好处是零代码改动。DeepSeek V4 最近把缓存折扣直接做到了 99% off(详情文档),让缓存 token 的费用几乎为零。
但要注意一个容易忽略的点:隐式缓存的命中率是概率性的,不是 100% 确定的。同一份请求被路由到哪台机器(缓存是按节点的,不是全局共享)、缓存有没有在 LRU 中被新请求挤掉、TTL 有没有过期——这些因素都会影响命中。生产环境下 60-90% 的命中率算正常。
显式标记缓存(Anthropic、Qwen)——你要自己在请求里标记 cache_control,告诉 API 哪些内容要缓存。好处是缓存命中是确定的(因为绑定了 cache_control 标记),坏处是需要改代码。Anthropic 首次缓存写入要多付 25% 费用,但后续每次读取只要 1/10。Qwen 的显式模式直接复用了 Anthropic 的 cache_control 字段名,代码几乎不用改。
显式创建对象缓存(Gemini、豆包)——先调 API 创建一个 cache 对象拿到 ID,后续请求带这个 ID。适合大段固定知识库的场景,但额外收存储费。
接下来看一下 Gemini 显式缓存的用法,跟 Anthropic 的"标记在消息里"不太一样:
TYPESCRIPT
import { GoogleGenAI } from '@google/genai'
const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY })
// Gemini 的显式缓存:先创建一个 cache 对象
const cache = await ai.caches.create({
model: 'gemini-2.5-flash',
contents: [{
role: 'user',
parts: [{ text: '这是一本 10 万字的技术文档……' }]
}],
ttl: '3600s' // 缓存 1 小时
})
// 后续请求引用这个 cache
const response = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: '基于上面的文档,帮我总结第三章的核心观点',
cachedContent: cache.name // 👈 引用缓存
})
Gemini 的显式缓存有一个独特之处:它有存储费用。而且这个价也不低,Pro 模型 $4.50/M token/小时,Flash 模型 $1.00/M token/小时。所以有一笔账你要算清楚:缓存一个大文档 1 小时,省下来的计算费用够不够覆盖存储费。如果你的文档会被反复查询几十次,肯定划算。如果只查一两次,可能不如直接发。
再看 DeepSeek,完全自动化缓存:
TYPESCRIPT
import OpenAI from 'openai'
const client = new OpenAI({
baseURL: 'https://api.deepseek.com',
apiKey: process.env.DEEPSEEK_API_KEY
})
// DeepSeek:什么都不用改,自动缓存
const response = await client.chat.completions.create({
model: 'deepseek-chat',
messages: [
{ role: 'system', content: '你是一个代码助手……(长 prompt)' },
{ role: 'user', content: '帮我看看这个 bug' }
]
})
// 返回里会告诉你命中了多少缓存
// usage.prompt_cache_hit_tokens: 12800
// usage.prompt_cache_miss_tokens: 245
DeepSeek 的自动缓存不需要改代码,缓存命中后省 99%——这个折扣力度在业内几乎是最大的。而且缓存存储免费,这一点比 Gemini 友好。
说了这么多,我们来小结一下Agent 场景下的最佳实践:
不管你用哪家 API,Prompt Cache 的核心原则是一样的:让前缀尽可能稳定和长。
对于显式缓存(Anthropic/Qwen),最有效的做法是在两个地方打缓存标记:
system prompt 的最后一个 block——缓存所有静态规则
最后一条用户消息的最后一个 block——缓存整个对话历史
这样每一轮新对话,只有最新的那一条消息是 cache miss,前面全部命中。
对于自动缓存(OpenAI/DeepSeek),你要做的就是保持前缀稳定——不要在开头放变化的内容,API 会自动帮你处理剩下的工作。
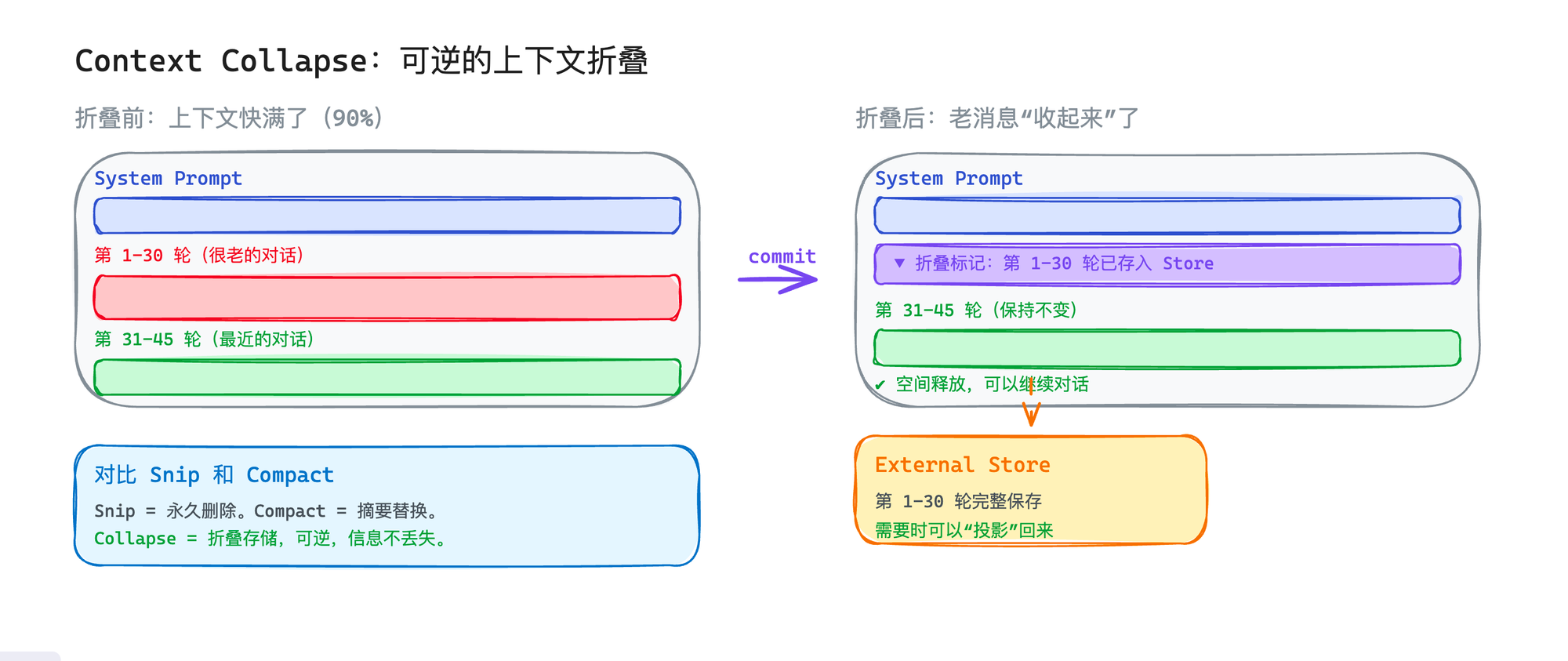
Context Collapse:应用层
这是最上层的,完全由你自己的应用代码控制。
Context Collapse 的思路是:与其真的把老消息删掉或压缩,比如把它们"折叠"起来。 老消息存到一个外部存储里,上下文里只保留一个折叠标记。需要的时候可以"展开"恢复。
跟 Snip(永久删除老消息)和 Compact(用摘要替换老消息)的区别是:Collapse 是可逆的。 信息没有真正丢失,只是暂时不在模型的视野里。
Claude Code 内部在实验这个特性(Context Collapse)。它的工作方式是:当上下文达到一定阈值(大约 90%),把较老的消息"commit"到一个 store 里,上下文里只留最近的部分。如果后续需要老消息里的信息,可以从 store 里"投影"回来。
这三层的关系现在比较清楚了:
KV Cache:你管不了,但要理解它的规则(前缀稳定 = 命中)
Prompt Cache:你能直接优化,ROI 最高(输入 token 省钱十倍)
Context Collapse:你可以自己实现,灵活性最高(可逆压缩)
常见的 Bad Case:这些写法在悄悄烧你的钱
理解了 Cache 的原理,下面来看几个实际开发中非常容易踩的坑。每个都附上错误写法和正确写法的对比。
Bad Case 1:动态内容破坏前缀稳定性
Prompt Cache 的命中靠的是前缀匹配——从第一个字节开始,只要有一个字符不一样,后面全部 cache miss。所以动态内容放在哪里,直接决定了你的缓存能覆盖多少。
最常见的错误是把时间戳放在 system prompt 开头:
TYPESCRIPT
// ❌ 错误:时间戳在最前面,每次请求都不一样
const systemPrompt = [
{
type: "text",
text: `当前时间:${new Date().toISOString()}。你是一个代码助手。
请帮用户完成编程任务……(后面 4000 token 的规则)`,
cache_control: { type: "ephemeral" }
}
]
你以为你只加了十几个字符的时间戳,实际上你让后面几千 token 的缓存全部失效了。
更隐蔽的变体是把动态内容插在中间——比如用户的 CLAUDE.md 放在静态规则和工具指南之间,用户一编辑,后面的工具指南缓存也跟着废了。
修复原则就一句话:按稳定性从高到低排列。
TYPESCRIPT
// ✅ 正确:静态内容在前面打缓存,动态信息放最后
const systemPrompt = [
{
type: "text",
text: `你是一个代码助手。以下是行为规则……(2000 token)`,
},
{
type: "text",
text: "以下是工具使用指南……(3000 token)",
cache_control: { type: "ephemeral" } // 这 5000 token 稳定命中
},
{
type: "text",
text: `当前时间:${new Date().toISOString()}\n\n${userClaudeMd}`
// 所有会变的东西集中放最后,不影响前面的缓存
}
]
最稳定的(通用规则、工具指南)放最前面打缓存,会变的(时间戳、用户配置、项目上下文)放最后面。这跟我们在 System Prompt 那篇讲的"静态层在前、动态层在后"是同一个思路——那篇是从 Context Rot 的角度讲的,这里是从 Cache 命中率的角度讲的,结论一样。
Bad Case 2:cache_control 标记位置不对
TYPESCRIPT
// ❌ 错误:只在 system prompt 上打了标记,消息历史没有
const request = {
system: [{
type: "text",
text: "你是代码助手……",
cache_control: { type: "ephemeral" } // 只缓存了 system prompt
}],
messages: [
{ role: "user", content: "第一轮问题" },
{ role: "assistant", content: "第一轮回答" },
{ role: "user", content: "第二轮问题" },
{ role: "assistant", content: "第二轮回答" },
// ... 40 轮对话,每轮 2K token,总共 80K token
{ role: "user", content: "第 50 轮问题" } // 没有 cache_control
]
}
system prompt 缓存了,但 80K token 的对话历史每次都全价计费。
TYPESCRIPT
// ✅ 正确:在最后一条用户消息上也打缓存标记
const messages = buildMessages(history)
const lastMessage = messages[messages.length - 1]
// 在最后一条消息上打 cache_control
if (typeof lastMessage.content === 'string') {
lastMessage.content = [{
type: "text",
text: lastMessage.content,
cache_control: { type: "ephemeral" }
}]
} else {
// content 是数组,在最后一个 block 上打标记
const lastBlock = lastMessage.content[lastMessage.content.length - 1]
lastBlock.cache_control = { type: "ephemeral" }
}
这样,下一轮对话时,之前所有的对话历史都能命中缓存,只有新加的那一条消息是 cache miss。80K 的对话历史从全价变成 1/10 的价格。
模型路由:不是所有步骤都需要最贵的模型
聊完了缓存,再说一个跟成本直接相关的话题——模型路由。对于比较小的、轻量的任务,我们路由给更小的模型去做,可以有效地节省成本。
两种主流的路由策略
从行业实践来看,模型路由主要有两种做法:
按任务类型静态路由——Claude Code 用的就是这种。在代码里写死分发逻辑,比如 Explore 操作就是用稍微逊色的 Sonnet 模型。这种做法简单,确定性高,适合任务类型明确的 Agent。
按难度动态路由——Not Diamond、Azure AI Foundry Model Router 走这条路。一个轻量级分类器(延迟 < 50ms)实时判断每个 prompt 的复杂度,简单的派给便宜模型,复杂的派给贵模型。Not Diamond 靠这个帮自己省了 51% 的推理成本。还有一个项目 RouteLLM也验证了这个思路:实现了 50%+ 的成本缩减,并且保证输出质量不下降。
如果你自己做路由
对于大部分 Agent 产品,第一种(按任务类型静态路由)就够了。不需要训练分类器,不需要引入第三方路由服务,在代码里按角色分配模型就行:
Agent Loop 主推理(代码生成、Bug 修复、架构决策),走大模型
后台辅助任务(对话摘要压缩),用小模型
只读的 Sub Agent(代码搜索、文件探索),用小模型
一个 50 轮任务,全用 Opus 可能要 $5-10,混合路由可能 $1-2。成本差 3-5 倍,效果基本一样。
如果你发现静态路由还不够——比如同一类任务里有些简单有些复杂,想做更细粒度的分配——再考虑接入动态路由。OpenRouter 的 openrouter/auto API(底层用 Not Diamond)支持按成本/延迟/质量做动态选择,接入成本并不高。
最后
Cache 和成本控制,对于 Agent 产品来说不单是优化措施了,而是实实在在的生存问题。
今天我们讲了成本控制的三个层面:
KV Cache(模型层):让前缀稳定,间接提高命中率
Prompt Cache(API 层):加 cache_control 标记或者显式创建缓存
Context Collapse(应用层):可逆的上下文折叠,灵活性最高
