
什么是RAG?
假设你让 Agent 帮你写一段代码,用到了公司内部的一个 SDK。这个 SDK 的文档在公司 wiki 上,模型训练数据里当然没有。Agent 不知道这个 SDK 的 API 长什么样,它只能瞎猜——猜出来的代码看起来像那么回事,但跑不起来。
再比如,你问 Agent "我们上个季度的 ARR 是多少"。这个数据在一份内部报告的 PDF 里,模型不可能知道。
这类问题的共同点是:信息存在,但不在模型的训练数据里,也不在 Agent 的记忆里。
RAG(Retrieval-Augmented Generation,检索增强生成)就是解决这个问题的。核心思路很朴素:在模型生成回答之前,先去"查资料",把相关内容塞进上下文,让模型有据可依。
Forrester Research 2026 年的一项研究发现,67% 的 RAG 失败可以追溯到数据质量问题——不是模型不够聪明,是你喂给它的"参考资料"本身就有问题。
所以先不说"用什么框架搭 RAG",而是把 RAG 管线里每一步拆开看:哪些地方容易出错,为什么会错,怎么避免。
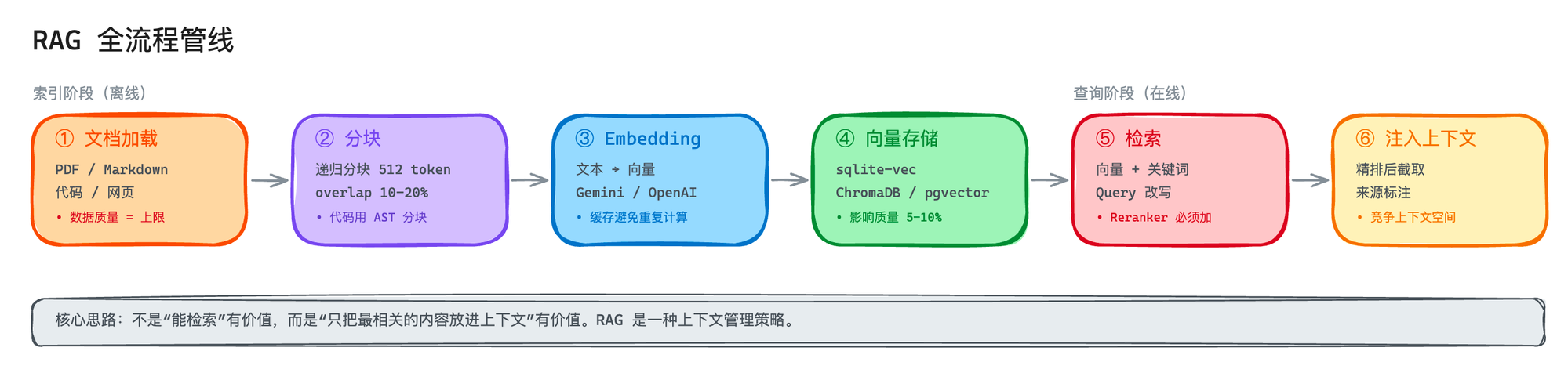
第一步:文档加载
RAG 的第一步是把你的文档变成可检索的文本。听起来简单,但不同格式的处理差异非常大。
Markdown 是最友好的格式。 它本身就是纯文本,有标题层级、有列表、有代码块——结构信息天然就在那里。基本上读进来就能用,不需要太多处理。
PDF 是最头疼的格式。 同样一份 PDF,用纯文本提取可能把表格拆成一行行的乱码,把多栏排版混在一起,页眉页脚跟正文混在一起。结构化提取(比如用 Adobe Extract API 或者开源的 docling)效果好很多,但成本也高。
如果你在 Node.js 生态里做 PDF 解析,几个选择供参考:简单文本提取用 pdf-parse 或者更现代的 unpdf(unjs 团队出品,TypeScript 原生)就够了。需要保留表格和标题结构的,pdfjs-dist(Mozilla 维护,能拿到字形位置信息)或者 IBM 的 Docling(表格准确率 97.9%,中文支持也好)更靠谱。如果不想自己折腾,LlamaParse 和 Claude API 都支持直接处理 PDF,靠模型来理解结构。
代码文件更特殊。 代码不是"文章",它有函数、类、模块这些结构单元。把一个函数从中间劈开分成两个 chunk,两个 chunk 单独看都没有意义。
网页需要去噪。 导航栏、侧边栏、广告、cookie 提示、footer——这些占了页面内容的一大半,但对你的检索来说全是噪音。Firecrawl、Jina Reader 这类工具可以帮你只提取正文。
总结一句话:数据质量决定了 RAG 的上限。 后面的分块策略再精妙、embedding 模型再强大,也救不了一份解析乱了的 PDF 内容。
第二步:分块——切得好不好,直接决定检索质量
文档加载进来了,下一步要把它切成小块(chunk)。为什么要切?因为上下文窗口有限,你不可能把一整份 50 页的文档塞进去。你需要找到最相关的那几段,只把它们塞进去。
但问题来了:怎么切?
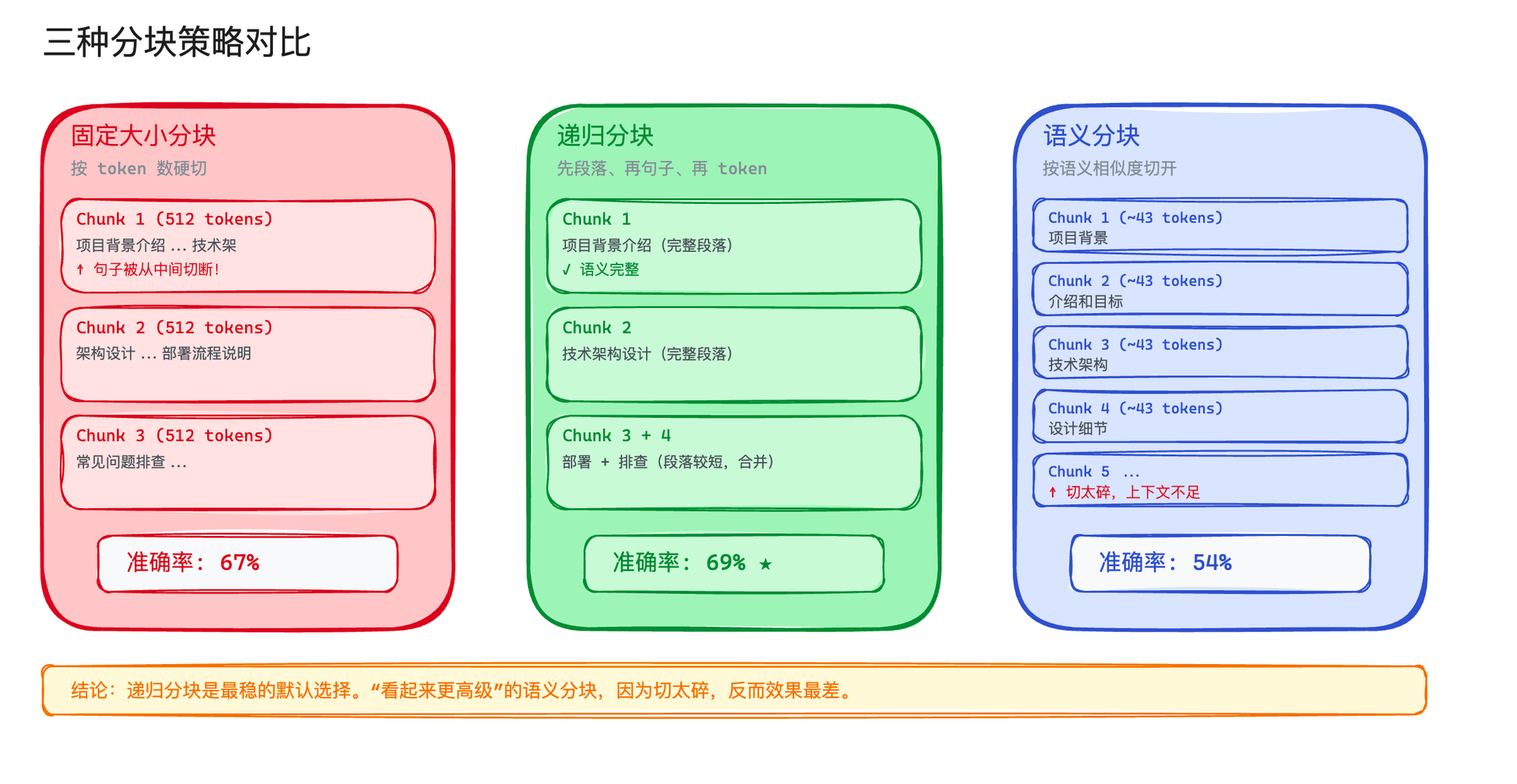
三种主流策略
固定大小分块:按 token 数量硬切,比如每 512 个 token 切一块。简单粗暴,但可能把一句话从中间劈开。
递归分块:先按段落分,段落太长了再按句子分,句子还太长了再按 token 分。LangChain 的 RecursiveCharacterTextSplitter 就是这个思路。它会依次尝试用 \n\n、\n、. 、 来分割,尽量保留语义完整性。
语义分块:用 embedding 模型判断相邻段落的语义相似度,在语义变化较大的地方切开。听起来最"智能",但实际效果可能让你失望。
除了这三种,还有按句子切的句子级分块、按页面/标题层级切的结构化分块、让 LLM 来决定怎么切的 LLM-Based 分块(质量最高但成本极高)、基于 embedding 语义分块等等,五花八门的,但我们接下来来看看应该选择哪一种比较好。
一个反直觉的发现
2026 年 2 月,PremAI 团队做了一个跨 50 篇学术论文的分块策略基准测试,结果挺出人意料的:
策略 | 端到端准确率 |
|---|---|
递归分块 512 token | 69% |
固定大小 512 token | 67% |
按页分块 | 64.8% |
语义分块 | 54% |
语义分块排最后到了最后。
因为语义分块切出来的 chunk 平均只有 43 个 token——太碎了。每个 chunk 包含的上下文信息太少,模型拿到之后没法做出准确的回答。
这些结果告诉我们一个反直觉的结论:不要被"看起来更高级"的方案迷惑。 递归分块这种"土方法",在大多数场景下就是最好的选择。Chunk Size 设为 256-512 token 这个区间,OpenClaw 的默认配置是 400 token/chunk,可以在实际场景里面直接采用这个配置。
代码文件怎么切?
代码不能按 token 硬切,原因很直觉:一个函数被从中间切开,两半各自都没有意义。
更好的做法是 AST-based chunking——用 AST(抽象语法树)解析代码,按函数、类、模块这些语义单元来切分。
不过说实话,在 coding agent 的场景里,现在越来越多的产品根本不用 RAG 来检索代码。Claude Code 就是一个典型例子——它直接用 grep、glob、选择性读文件来找代码,没有任何 RAG 基础设施。为什么?因为代码有明确的结构(import、类型、调用链),用确定性的工具去导航比用向量搜索更准确。
Anthropic 的工程师 Boris 在 Latent Space 播客上说过:"我们早期试过本地向量数据库做代码 RAG,后来放弃了。Agentic search 的效果碾压向量搜索。"
RAG 更适合的是文档类内容——技术文档、产品文档、知识库、报告。 代码检索,让模型用工具就好。
第三步:Embedding——把文字变成向量
分好块之后,需要把每个 chunk 变成一个向量(一串数字),这样才能做相似度搜索。这个过程叫 embedding。
Embedding 到底在做什么?
一个简单的类比:想象一个巨大的多维空间,每一篇文档在这个空间里有一个位置。语义相近的文档,位置就靠近;语义不相关的,位置就远。
举个例子,"怎么部署应用"和"部署流程指南"在这个空间里应该靠得很近。而"怎么部署应用"和"今天天气不错"就应该离得很远。
Embedding 模型做的就是帮你算出每个 chunk 在这个空间里的坐标。查询的时候,把用户的问题也算一个坐标,然后找跟它最近的那些 chunk——这就是向量搜索。
那么你可能会好奇,Embedding模型底层到底是如何计算每个chunk的空间坐标的?
大白话就是:Embedding 模型做的事情,就是给每段文字拍一张"身份证照片"——这张照片是一串数字,数字越像的文字,在"语义空间"里离得越近。
具体怎么算的呢?分三步来看:
第一步:把文字拆成模型能读懂的零件
模型会把你的 chunk 先拆成更小的单位(叫 token),比如"怎么部署应用"可能被拆成"怎么"、"部署"、"应用"这三个 token。每个 token 在模型内部都有一个初始的"编号"(就是个随机的向量)。这一步就像把一句话拆成一堆积木块,每个积木块上刻着一个初始的编号。
第二步:让这些零件互相"聊天"
模型的核心是一个叫 Transformer 的神经网络(你可以理解成一个超复杂的计算网络)。它会让你 chunk 里的每个 token 都去"看"其他所有 token,互相传递信息。比如"部署"这个词,在"怎么部署应用"里,它跟"应用"的关系很近;但在"部署架构图"里,它跟"架构"的关系更近。
这个过程叫做 注意力机制(Attention)——每个 token 通过计算"跟其他 token 的关系有多强",不断调整自己的"编号"。经过很多层这样的计算后,每个 token 的编号已经不再是随机数,而是包含了它在整个 chunk 里的语义信息。
第三步:把整段文字揉成一个坐标
最后一步,模型会把所有 token 的"成熟的编号"做一个综合计算(通常是取平均或者拼接),最终输出一个固定长度的向量。比如 OpenAI 的 text-embedding-3-small 输出 1536 个数字,Gemini Embedding 2 输出 768 个数字。
这 768 或 1536 个数字,就是你说的"坐标"。这串数字就是这段文字在高维空间里的地址。
一个具体的例子帮你理解:
假设有两个 chunk:
Chunk A:"今天天气真好,适合出去玩"
Chunk B:"外面阳光明媚,我们去散步吧"
模型算出来的坐标可能是:
Chunk A:[0.8, 0.6, 0.2, -0.1, ...](共 768 个数字)
Chunk B:[0.79, 0.61, 0.18, -0.08, ...]
你看,这两串数字的数值非常接近——因为这两句话语义相近。而"我的银行账户余额是多少"算出来的坐标数值就会跟它们差得很远。
总结:Embedding 模型不"理解"文字,它只是通过神经网络的多层计算,把文字映射到一组数字上,让语义相近的文字得到相近的数字组合。 这组数字就是你说的"坐标"。
第四步:存储——向量数据库选型
embedding 算出来了,需要存到一个支持向量搜索的数据库里。
这里有一个先说清楚的前提:向量数据库的选择对 RAG 系统质量的影响很小。真正决定质量的是前面的数据处理、分块策略和 embedding 模型。所以不要在数据库选型上花太多纠结的时间。
下面有几个主流选择,你选择一个即可:
sqlite-vec——如果你在做本地应用或者边缘部署,它就是最合适的。零依赖,单文件,不需要额外的服务进程。OpenClaw 就是用的这个。缺点是单线程写锁,并发高了会有瓶颈。
ChromaDB——大部分项目的务实选择。轻量,几分钟就能跑起来原型。2025 年用 Rust 重写之后性能提升了 4 倍。底层其实也是 SQLite。
pgvector——如果你的项目已经在用 PostgreSQL,直接加个扩展就行了,不需要引入新的基础设施。50-100M 向量以下都能扛得住。比如 Supabase 这种基于 PostgreSQL 的数据库服务,可以直接用这个方案,很方便。
Qdrant / Pinecone——大规模生产环境用。Qdrant 是 Rust 写的,过滤能力强;Pinecone 是全托管的,不用操心运维。但长期使用的经济成本也相对高。
Milvus——如果你的向量数据量在百万到亿级别,Milvus 是目前最成熟的分布式向量数据库之一。它支持多种索引类型(IVF、HNSW、DiskANN 等),可以根据数据规模和延迟要求灵活选择。背后的 Zilliz 也推了全托管的云服务。在国内企业级 RAG 场景用得非常多,生态和中文社区也比较活跃。轻量级场景可以用它的嵌入式版本 Milvus Lite,一行代码就能跑起来。
一个简单的决策路径:本地/边缘用 sqlite-vec,原型验证用 ChromaDB,已有 Postgres 就用 pgvector,大规模生产环境直接上 Qdrant、Pinecone 或 Milvus 三者任选其一。
第五步:检索——这里的坑最多
存储做好了,现在用户来提问了。你需要把问题转成向量,去数据库里找最相关的 chunk。
这一步听起来简单,但实际上是 RAG 管线里最容易翻车的地方。
有一个最核心的问题:语义相似不等于任务相关。
用户搜"怎么部署",向量搜索可能返回"部署架构图"(语义近)而不是"部署命令清单"(用户真正需要的)。因为 embedding 模型对操作性和描述性内容的区分能力有限。
纯向量搜索在生产环境里是不够用的。混合检索(向量 + 关键词)、Query 改写、Reranker 精排——这些优化手段能把检索质量提升一个台阶。但每一种都有自己的原理、适用场景和成本代价。
索引更新:文档变了怎么办?
最后还有一个很实际但经常被忽略的问题:你的文档不是一成不变的。API 文档更新了,知识库加了新文章,旧的条目被删了——索引需要跟着更新。
两种策略:
全量重建:把所有文档重新分块、重新 embedding、重新入库。简单暴力,但成本高。适合文档量不大或者变更量超过 10-15% 的场景。
增量更新:只处理变更的部分。用 hash 比对文件内容是否变化(OpenClaw 就是这么做的),没变的跳过,变了的重新处理。效率高,但实现复杂一些。
OpenClaw 的做法比较稳:增量更新用 hash 检测变化,但全量重建的时候用临时数据库 + 原子交换——先在一个临时 SQLite 文件里建好新索引,确认没问题后一次性替换旧的。
还有一个需要注意的场景:embedding 模型升级了。 新模型生成的向量和旧模型的不在同一个空间里,不能混用。这时候必须做全量重建。
从 RAG 到 Agentic RAG:当检索变成循环
前面讲的整套管线——分块、Embedding、检索、注入——本质上是一条直线:用户问一个问题,系统检索一次,把结果塞进 prompt,模型生成回答。一次检索定生死。
这在简单问答场景下没问题。但你试过问更复杂的问题吗?"我们的用户增长放缓是不是跟上个月改的定价策略有关?"——这个问题需要先查用户增长数据,再查定价策略变更记录,然后对比时间线,可能还要看看竞品同期的数据。一次检索根本不够。
Agentic RAG 就是把检索从一条直线变成一个循环。 你可能在社区里听过这个词,它其实就是我们课程里两个概念的组合——Agent Loop + RAG 管线。
传统 RAG 的流程是:
PLAINTEXT
用户提问 → 检索 top-k → 注入上下文 → 生成回答
Agentic RAG 的流程是:
PLAINTEXT
用户提问 → Agent 决定要不要搜 → 搜了看看够不够
→ 不够就换个 query 再搜 → 或者调个工具补充数据
→ 够了再生成回答
实际上你如果用了 Agent Loop + 把向量检索包装成一个工具,你已经在做 Agentic RAG 了——Agent 在循环里自主调用搜索工具,搜到不满意就换个 query 再搜,搜到够了才开始回答。Claude Code 的 Grep + Glob + Read 组合本质上就是一种 Agentic RAG:模型自己决定搜什么文件、读哪些内容、读完够不够,只是没有用到语义向量化的方式。
所以 Agentic RAG 不是什么新范式,它就是 Agent 能力和 RAG 管线的自然融合。你只需要:把这篇讲的向量检索包装成一个工具,交给 Agent Loop 去调用,剩下的事情模型自己会做。
