Agent Loop:心跳与引擎
理解Agent的核心驱动循环:ReAct模式(Reason--->Action--->Observe)
一次Agent调用背后发生了什么
想象这个场景:你在终端对 Claude Code 说"帮我把 moment 换成 dayjs",从按回车到搞定,中间涉及哪些系统?
第一件事:它得决定先做什么。
这个"想一步、做一步、看一步"的循环,就是 Agent Loop。它是 Agent 的心跳——没有这个循环,AI 就只是一个问答机器。
第二件事:它得能读文件、跑命令。
光"想"没用,得有手。Claude Code 需要调用 Read 工具读文件、调用 Bash 工具跑 pnpm add dayjs、调用 Edit 工具改代码。
这些工具的定义、调度、权限管理、并发控制,组成了 Tool System。它是 Agent 的手脚——没有工具,Agent 就是个只会说不会做的嘴炮。
第三件事:它得记住前面做了什么。
这就是 Context Engineering,上下文工程。它是 Agent 的大脑供血系统——决定 Agent 能"看到"多少、"记住"多少。
第四件事:它得记住你是谁。
这是 Memory 系统——跨会话的长期记忆。和 Context Engineering 不同,Context 管的是单次会话内的信息,Memory 管的是跨会话的持久化。
第五件事:复杂任务,一个 Agent 搞不定。
这就是 Multi-Agent——不是为了"分角色"搞什么 PM + 设计师 + 开发者的 cosplay,而是为了分隔上下文。
第六件事:权限、Hook、重试、优雅退出……
这些"包裹在模型外面"的工程系统,就是 Harness Engineering。它是 Agent 的骨架——模型再强,没有一个好的骨架,也跑不起来。
看看一次 Agent 的工具调用到底经历了什么:
Tokenize:你的 prompt(system prompt + 对话历史 + 用户指令)被拆成一串 token 数字
Attention 计算:模型回看所有 token,给每个 token 分配注意力权重,综合所有信息
KV Cache:前面轮次已经算过的 token 直接复用缓存,只算新增的部分
生成 token:模型输出第一个 token 的 logits → softmax → 采样,得到第一个 token
自回归循环:把新 token 加入上下文,回到第 2 步,重复直到输出完整的工具调用 JSON
约束解码(如果用了的话):在第 4 步的采样阶段,通过 logit mask 限制模型只能输出合法的 token

六大支柱
这一次看似简单的工具调用,背后牵扯了六个大的系统:

支柱 | 一句话 | 人体类比 |
|---|---|---|
Agent Loop | 想一步、做一步、看一步的循环 | 心跳 |
Tool System | 读文件、跑命令、调 API | 手脚 |
Context Engineering | 管理有限的上下文窗口 | 大脑供血 |
Memory | 跨会话的长期记忆 | 长期记忆 |
Multi-Agent | 拆任务、分上下文 | 团队协作 |
Harness Engineering | 权限、重试、Hook、生命周期 | 骨架 |
记住这六个词。 后面不管出什么新的 Agent 产品、新的框架、新的论文,你都可以用这六个维度去拆解它。它在 Agent Loop 上做了什么创新?Context Engineering 怎么处理的?工具系统是什么设计?
这六个支柱不是平行的,它们之间有依赖关系。我建议的学习路径是从内到外:
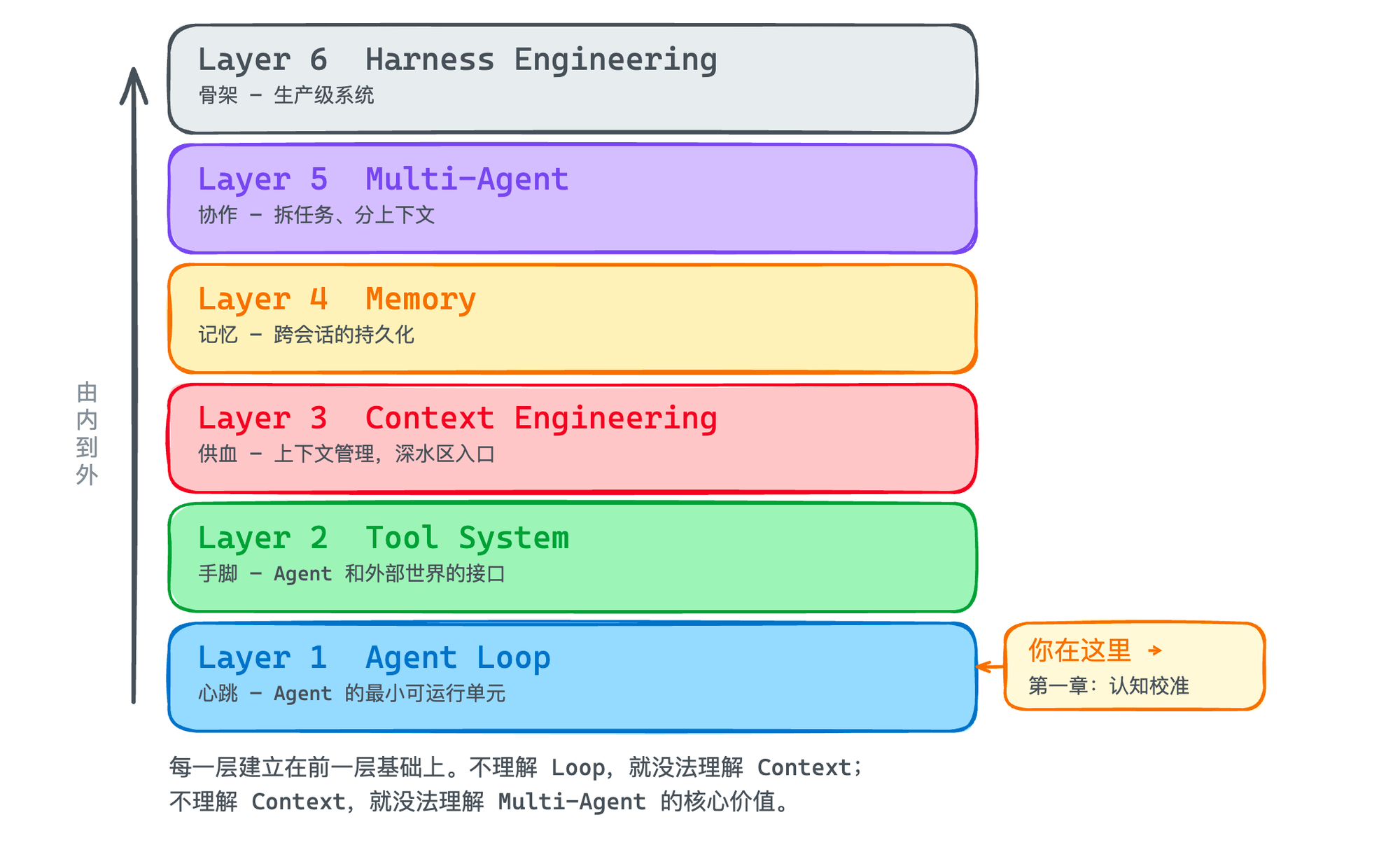
Agent Loop(心跳):先理解 Agent 的最小可运行单元
Tool System(手脚):Agent 能"做事"了,你才能观察后面的问题
Context Engineering(供血):Agent 跑起来之后,上下文爆了怎么办?这是深水区的入口。
Memory(记忆):单次会话、跨会话,上下文记忆怎么来管理?
Multi-Agent(协作):一个 Agent 不够用,怎么拆成多个?
Harness Engineering(骨架):上面都搞定了,怎么包成一个生产级系统?
Agent Loop 的作用——它是整个 Agent 的"心跳"和"引擎",负责驱动整个决策循环。
让我用一个简单的图来说明这个过程:
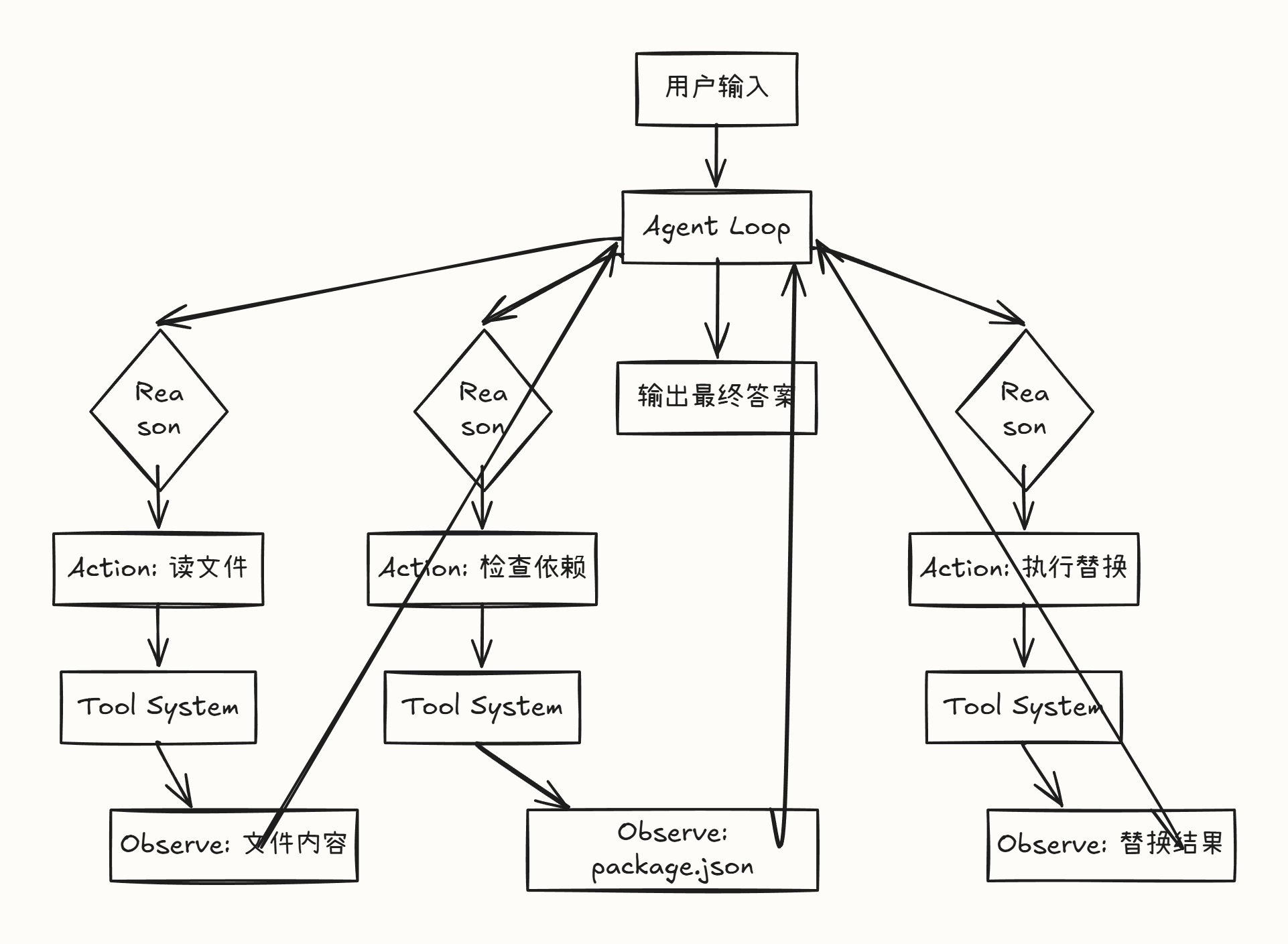
看到了吗?Agent Loop 在不停地循环:Reason(思考)→ Action(行动)→ Observe(观察),这个循环就是著名的 ReAct 模式。
Tool System:手脚与能力
掌握工具系统的设计模式:统一接口、中央注册表、权限控制
Agent Loop 这个"心跳"已经搭建好了,但光有心跳还不够——Agent 需要实际做事的能力。
想象一下:你的 Agent 想"帮用户把 moment 换成 dayjs",它需要在心里想多少遍"我要读文件、我要写文件",都做不到。它需要真正的'手脚'去执行这些动作。这就是 Tool System 的作用。
工具的本质
如果让你设计一个工具系统,让 Agent 能够调用各种能力(读文件、写文件、运行命令、搜索网络...),你会怎么设计?
关键问题:如何保证所有工具都有一个统一的接口?
提示:想象你是 React 开发者,你在设计一个组件库。你会希望每个组件都有相似的 props 结构,对吧?工具系统也是类似的思路。统一结构的入参和出参正是工具系统的核心设计原则。
第一个问题:如何设计统一接口?
一个标准的 Tool 接口通常长这样:
TYPESCRIPT
// 入参(Agent → Tool)
interface ToolCall {
name: string; // "read_file", "write_file", "bash" ...
arguments: object; // 具体的参数,如 { path: "package.json" }
}
// 出参(Tool → Agent)
interface ToolResult {
success: boolean; // 执行是否成功
result?: any; // 执行结果(成功时)
error?: string; // 错误信息(失败时)
}第二个问题:中央注册表模式
现在我们有统一的接口了,但还有一个问题:Agent 怎么知道有哪些工具可用?这类似于 React 中的组件注册机制——你如何让整个应用知道有哪些组件可以用?全局位置——这就是 Tool Registry(工具注册表) 的概念。
Tool Registry:工具注册表
让我用代码展示这个设计:
TYPESCRIPT
// 全局工具注册表
class ToolRegistry {
private tools: Map<string, Tool> = new Map();
// 注册工具
register(tool: Tool) {
this.tools.set(tool.name, tool);
}
// 获取工具
get(name: string): Tool | undefined {
return this.tools.get(name);
}
// 列出所有可用工具(给模型看的)
listTools(): ToolDefinition[] {
return Array.from(this.tools.values()).map(t => t.definition);
}
}第三个问题:Tool Definition:工具使用说明书
当 Agent 启动时,它需要告诉 LLM"你可以使用这些工具"。但 LLM 不需要知道工具的实现代码,它只需要知道什么?LLM 需要知道的是工具的定义(Definition),而不是实现。
每个工具在注册时,除了提供实现代码,还需要提供一个定义,告诉 LLM 这个工具是干什么的、怎么用:
TYPESCRIPT
interface ToolDefinition {
name: string; // "read_file"
description: string; // "Read the contents of a file at the given path"
parameters: { // JSON Schema 格式的入参定义
type: "object",
properties: {
path: {
type: "string",
description: "The path to the file to read"
}
},
required: ["path"]
};
}你可能注意到了,parameters 字段用的是 JSON Schema 格式。这是有原因的:
LLM 能理解:JSON Schema 是一种标准化的格式,模型训练时见过大量类似结构
机器可验证:可以用它来校验 Agent 传进来的参数是否合法
自描述性:不需要额外文档,Schema 本身就是文档
这就像 TypeScript 的类型定义——既给人看,也给编译器看。
第四个问题:工具调用的完整流程
让我用一张图来可视化这个流程:
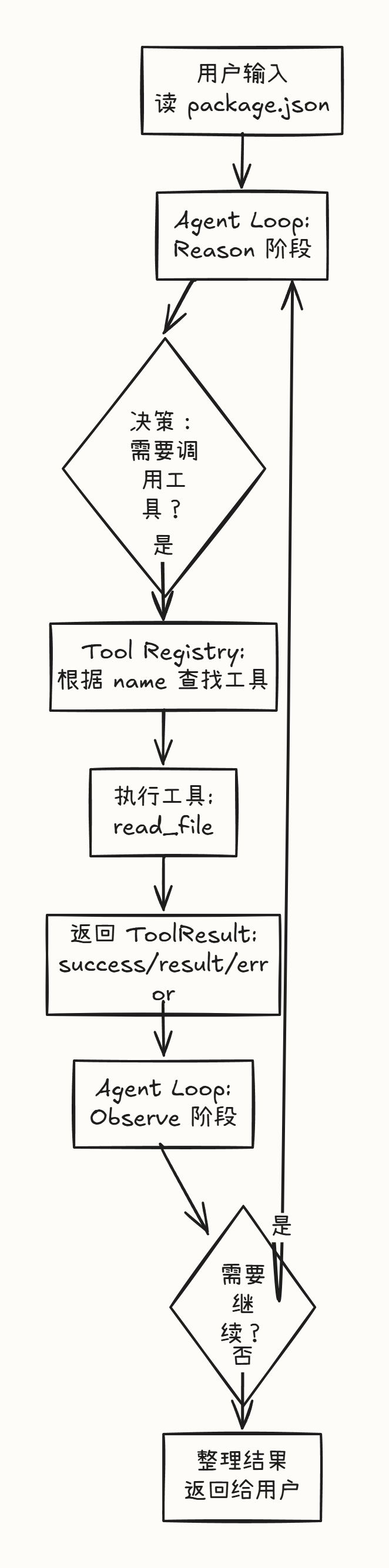
第五个问题:权限与安全模型
假设用户说:"帮我删除整个项目文件夹 rm -rf /"。你的 Agent 有一个 bash 工具可以执行任意命令。问题来了:这个请求应该直接执行吗?
权限分层:三层模型
生产级的 Tool System 通常采用 三层权限模型:
TYPESCRIPT
enum PermissionLevel {
ALLOW = "allow", // 直接执行,无需询问
ASK = "ask", // 需要用户确认
DENY = "deny" // 直接拒绝
}关键问题:权限判断放在哪?
生产级系统通常选择 放在 Tool Registry 和具体工具之间,作为一个独立的 Permission Layer(权限层)。让我用代码展示:
TYPESCRIPT
class ToolRegistry {
async execute(toolName: string, args: object, context: Context) {
// 1. 先查权限
const permission = await this.permissionChecker.check(toolName, args, context);
if (permission === 'deny') {
return { success: false, error: 'Permission denied' };
}
if (permission === 'ask') {
const confirmed = await this.askUser(toolName, args);
if (!confirmed) {
return { success: false, error: 'User cancelled' };
}
}
// 2. 权限通过,执行工具
const tool = this.tools.get(toolName);
return tool.execute(args);
}
}第六个问题:工具管线(Tool Pipeline)
每个中间件做一件事,然后调用 next() 传递给下一个。这就是 责任链模式(Chain of Responsibility)。Tool System 也用同样的模式:
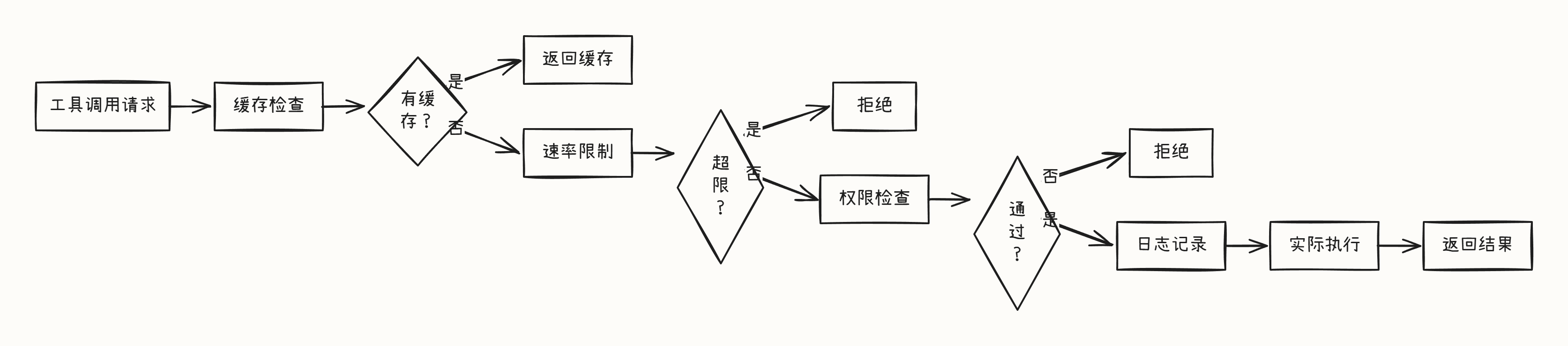
核心设计:Pipeline 结构
TYPESCRIPT
interface ToolMiddleware {
name: string;
execute: (call: ToolCall, context: Context, next: () => Promise<ToolResult>) => Promise<ToolResult>;
}
class ToolPipeline {
private middlewares: ToolMiddleware[] = [];
use(middleware: ToolMiddleware) {
this.middlewares.push(middleware);
}
async execute(call: ToolCall, context: Context): Promise<ToolResult> {
// 递归执行中间件链
const run = async (index: number): Promise<ToolResult> => {
if (index >= this.middlewares.length) {
return this.executeTool(call); // 最后执行实际工具
}
const middleware = this.middlewares[index];
return middleware.execute(call, context, () => run(index + 1));
};
return run(0);
}
}关键理解:每个中间件都有"决定权"
缓存中间件:如果有缓存,直接返回,不调用
next()限流中间件:如果超限,直接拒绝,不调用
next()权限中间件:如果拒绝,直接返回错误
日志中间件:记录后调用
next(),让流程继续。
假设你要实现一个 缓存中间件,缓存的 Key 应该如何生成?缓存 Key 应该基于入参来生成:
TYPESCRIPT
function generateCacheKey(toolCall: ToolCall): string {
// 1. 组合工具名 + 参数
const keyString = JSON.stringify({
name: toolCall.name,
arguments: toolCall.arguments
});
// 2. 生成哈希值(避免 Key 太长)
return sha256(keyString);
}
// 示例:
// read_file({ path: "package.json" })
// → "a3f5c8d9e2b1..."
// read_file({ path: "tsconfig.json" })
// → "b7e4f1a6c3d2..."
关键洞察:为什么不用时间戳?
你可能会想:如果两次调用时间不同,是不是应该算不同的 Key?
答案是:不应该。缓存的目的就是"相同的请求返回相同的结果"。如果 read_file("package.json") 在 1 分钟前和现在调用,文件内容没变,就应该命中缓存。
第七个问题:动态工具集
场景:你的 Agent 有一个 database_query 工具,可以执行 SQL 查询。但这个工具很危险——如果用户乱写 SQL,可能会删库跑路。
所以你设计了一个规则:只有当用户明确说"查询数据库"时,才注册这个工具;否则根本不告诉 LLM 有这个工具。
问题:这种"动态注册/注销工具"的机制,有什么好处?
动态工具集的两个核心价值:
✅ 安全性:工具越少,攻击面越小(Attack Surface)
✅ Token 效率:工具定义本身占用上下文,动态注册可以节省 Token。
让我用代码展示这个模式:
TYPESCRIPT
class DynamicToolRegistry {
private baseTools: Tool[] = [...]; // 基础工具(总是可用)
private contextTools: Map<string, Tool[]> = new Map(); // 按场景激活的工具
// 根据当前上下文激活特定工具
activateToolsForContext(context: string): void {
const tools = this.contextTools.get(context);
if (tools) {
tools.forEach(tool => this.register(tool));
}
}
// 示例场景
activateDatabaseTools() {
this.register(databaseQueryTool);
this.register(databaseSchemaTool);
}
deactivateDatabaseTools() {
this.unregister('database_query');
this.unregister('database_schema');
}
}小结
今天掌握了 Tool System 的完整架构:
概念 | 核心思想 | 类比 |
|---|---|---|
统一接口 | 所有工具都有 | React 组件的统一 props 结构 |
Tool Registry | 中央注册表,管理所有可用工具 | 组件库的索引文件 |
Tool Definition | 工具的"使用说明书",用 JSON Schema 定义 | TypeScript 类型定义 |
Permission Layer | 三层权限模型(ALLOW/ASK/DENY) | React 的 WithPermission 包装器 |
Tool Pipeline | 中间件链模式,支持缓存/限流/日志 | Express 中间件链 |
Dynamic Tools | 按场景动态注册/注销工具 | 按需加载的组件 |
Context Engineering:大脑供血
理解上下文管理的核心:System Prompt、压缩策略、注意力分散问题
现在 Agent 有了心跳(Agent Loop)和手脚(Tool System),但它还缺一个关键的东西:大脑的供血系统。上下文的大小和管理策略是由 Agent Loop 的执行模式决定的。因为 Context Engineering 的核心问题都源于 Agent Loop 的运行机制:

while循环改变了什么?
Agent的最小模型:while(true)
如果让你用代码来表达 Agent 的核心逻辑,最简单的版本长这样:
TYPESCRIPT
while (true) {
const response = await llm.chat(messages) // 想:让模型决定下一步
if (response.toolCalls.length === 0) {
break // 模型认为任务完成了,没有工具要调
}
for (const toolCall of response.toolCalls) {
const result = await executeTool(toolCall) // 做:执行工具
messages.push(result) // 看:把结果加入上下文
}
}简单版是"想-做-看"三步,Claude Code 的实际流程是这样的:
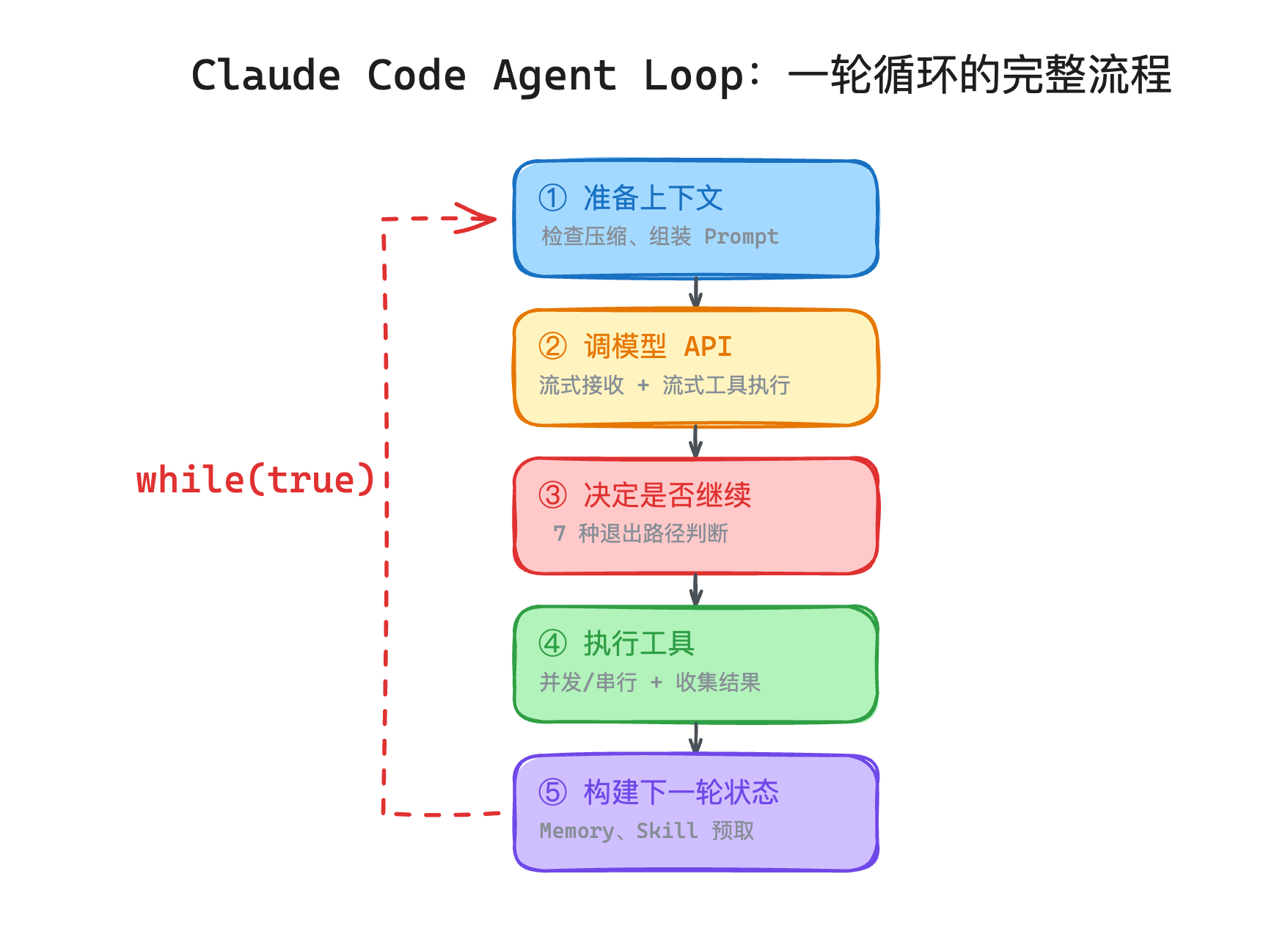
第一步:准备上下文
在调 API 之前,先检查上下文是不是快爆了。如果快到上限了,触发压缩——先试轻量级的 Snip(删掉老消息),不行就 Microcompact(局部摘要),再不行就 Auto-compact(全局摘要)。
第二步:调模型 API
哪些操作可以并发、哪些必须串行——是 Agent 工具系统里一个很重要的设计点。
第三步:决定是否继续
Claude Code 有 7 种退出路径:
退出原因 | 什么时候触发 |
|---|---|
| 模型没有调用工具,认为任务完成了 |
| 流式传输过程中被中断 |
| 工具执行过程中被中断 |
| Hook 阻止了继续执行 |
| 超过了最大轮次限制 |
| 上下文太长,API 拒绝了 |
| 压缩后还是太长,无法恢复 |
第四步:执行工具,收集结果
第五步:处理附加任务
Prompt被拆成了什么?
简单说,模型不认识"文字",它只认识数字。所以你输入的任何内容——中文、英文、代码、标点符号——都会先被切成一小块一小块的"token",每个 token 对应一个数字编号。

大部分大模型用的分词算法叫 BPE(Byte Pair Encoding)。简单理解就是:模型在训练之前,先统计大量文本中哪些字符组合出现频率最高,把高频组合合并成一个 token。英文训练数据比中文多得多,所以英文的合并更充分,一个词一个 token;中文经常要拆开来编码。
这直接导致了一个实际问题:同样的语义内容,中文比英文消耗更多的 token。
好,现在你的 prompt 已经变成了一串 token 数字,喂给模型了。接下来模型要开始生成回复。大模型不是"想好了再说"的,它是"边说边想"的。什么意思呢?模型生成文本的过程,是一个 token 接一个 token 往后蹦的。它先生成第 1 个 token,然后把第 1 个 token 加入输入,再生成第 2 个 token,然后把前 2 个 token 加入输入,再生成第 3 个……如此循环,直到生成一个"结束"标记。这个过程叫自回归生成(Autoregressive Generation)。

Attention和KV Cache:为什么上下文不是越长越好
ransformer 架构里最核心的东西:Attention(注意力机制)。最核心的三个角色:Query、Key、Value。
Q、K、V:搜索引擎的比喻
你在 Google 搜索的时候,发生了什么?
你输入一个搜索词——"KV Cache 是什么"
Google 拿你的搜索词去匹配所有网页的标签和关键词
匹配度高的网页,把它的内容返回给你
Attention 做的事情完全一样:
Query(查询):当前正在生成的 token 会问一个问题——"我需要什么信息来决定下一个词?"
Key(索引):前面每一个 token 都有一个标签——"我包含什么类型的信息?"
Value(内容):前面每一个 token 的实际内容——"这是我的具体信息。"
生成新 token 的时候,模型拿当前 token 的 Query,去和前面所有 token 的 Key 做匹配。匹配度高的,就把对应的 Value 拿过来,加权混合,作为生成下一个 token 的依据。

举个具体的例子。假设上下文是"小明昨天去了北京,今天他去了",现在要生成下一个 token:
当前 token 的 Query 大概在问:"谁去了哪里?"
"小明"这个 token 的 Key 标签是"人名",匹配度高 → 它的 Value 被拉过来
"北京"的 Key 是"地名",匹配度也挺高 → Value 也被拉过来
"昨天"的 Key 是"时间词",跟当前问题关系不大 → Value 的权重就低
最终模型综合了高权重的 Value 信息,可能生成"上海"(另一个城市)。
这就是 Attention 的全部了。 没有什么神秘的,就是一个"查询-匹配-取值"的过程,只不过这个过程是可以被训练的——模型通过大量数据学会了怎么生成好的 Query、Key 和 Value。
KV Cache:已经算过的 Key 和 Value,别再算了
好,理解了 Q、K、V 之后,KV Cache 就很好理解了。
刚才说模型每生成一个新 token,都要拿 Query 去匹配前面所有 token 的 Key 和 Value。但你想想,如果模型已经生成了 100 个 token,现在要生成第 101 个,它需要用到前 100 个 token 的 Key 和 Value。等到要生成第 102 个的时候,前 101 个 token 的 Key 和 Value 又要用一遍——其中 100 个跟刚才是一模一样的。
重新计算一遍?太浪费了。
所以模型会把之前算过的每个 token 的 Key 和 Value 缓存起来,这个缓存就叫 KV Cache(Key-Value Cache)。现在你知道这个名字的由来了——缓存的就是 Attention 里面的 K 和 V。
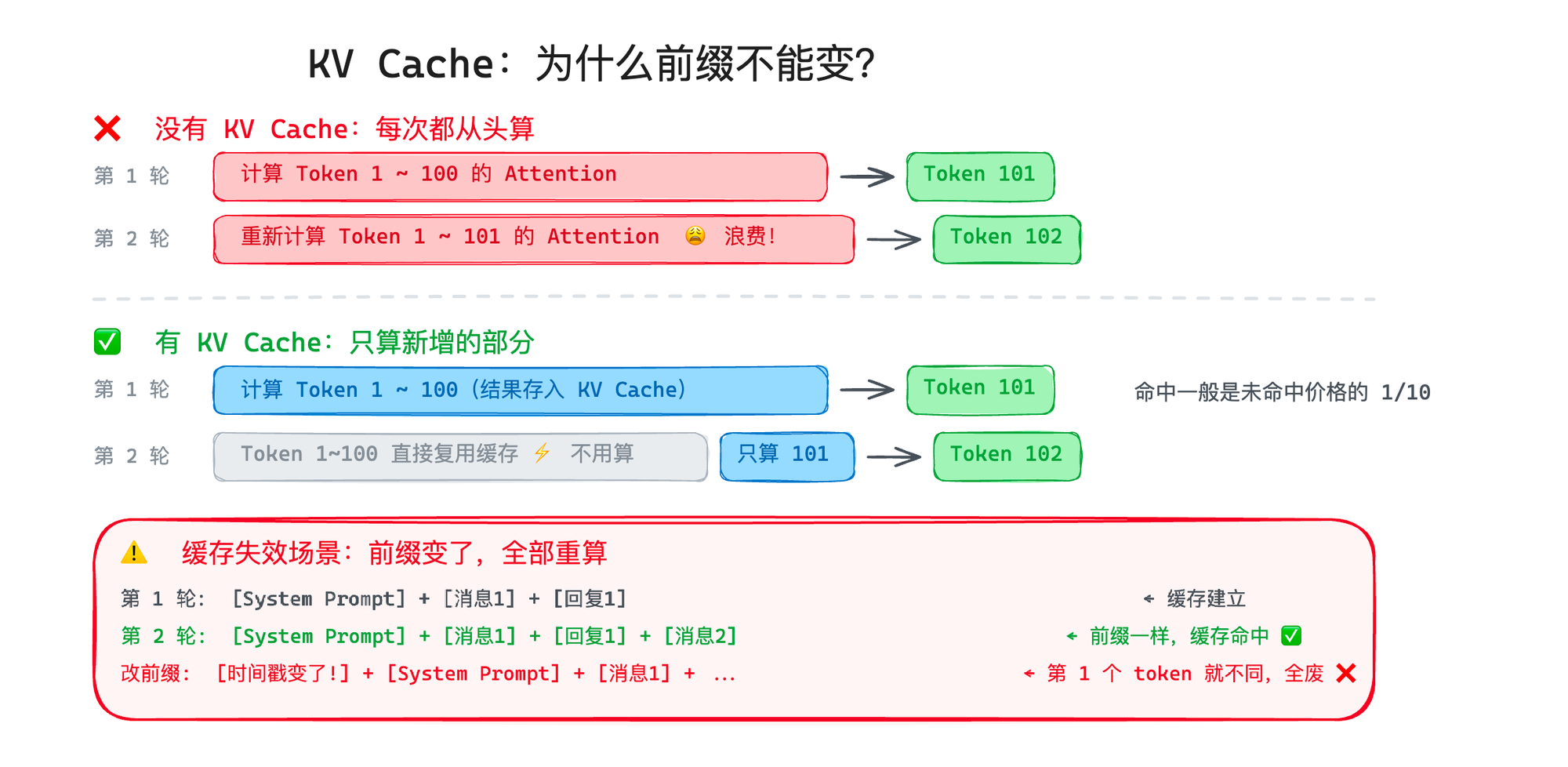
打个比方:你在考试,每道题都需要翻课本找公式。KV Cache 就像你把常用公式抄在草稿纸上——后面的题直接看草稿纸就行,不用每次都翻书。
但 KV Cache 有一个关键限制:它是基于"前缀匹配"的。
举个例子。你的 Agent 第一轮对话,发给模型的内容是:
PLAINTEXT
[System Prompt] + [用户消息1] + [模型回复1]
第二轮对话,发的是:
PLAINTEXT
[System Prompt] + [用户消息1] + [模型回复1] + [用户消息2]
因为前面的部分完全一样,只是末尾加了新内容,所以前面所有 token 的 KV Cache 都能复用。模型只需要计算新增的 [用户消息2] 的部分。
但如果你做了一件事——比如在 System Prompt 的开头加了个时间戳:
PLAINTEXT
当前时间:2026-04-02 08:00:00 ← 这个每次都变!
[其余的 System Prompt]
[用户消息1]
[模型回复1]
[用户消息2]
完蛋。第一个 token 就不一样了,后面所有的 KV Cache 全部作废,需要从头重新计算。
模型“选词”:从打分到概率
模型每生成一个 token,内部到底发生了什么?简单来说,分三步:
第一步:给所有候选词打分(Logits)
模型的词汇表里有几万个 token(Claude 大概有 10 万多个)。每生成一个新 token,模型会给词汇表里的每一个 token 打一个原始分数,表示"根据前面的上下文,这个 token 接下来出现的可能性有多大"。
这些原始分数叫 logits。
比如在"今天天气真"这个上下文后面,"好"这个 token 可能得分 5.2,"不"得分 3.1,"的"得分 1.8,而"跑步"可能只有 -2.3。
第二步:把分数变成概率(Softmax)
softmax 做的事情很简单:分数越高的词,概率越大;分数越低的词,概率越小。而且这个差距会被放大——高分词的概率会比它的原始分数暗示的还要高。
经过 softmax 之后,"好"可能变成 65% 的概率,"不"15%,"的"8%,"跑步"0.01%。
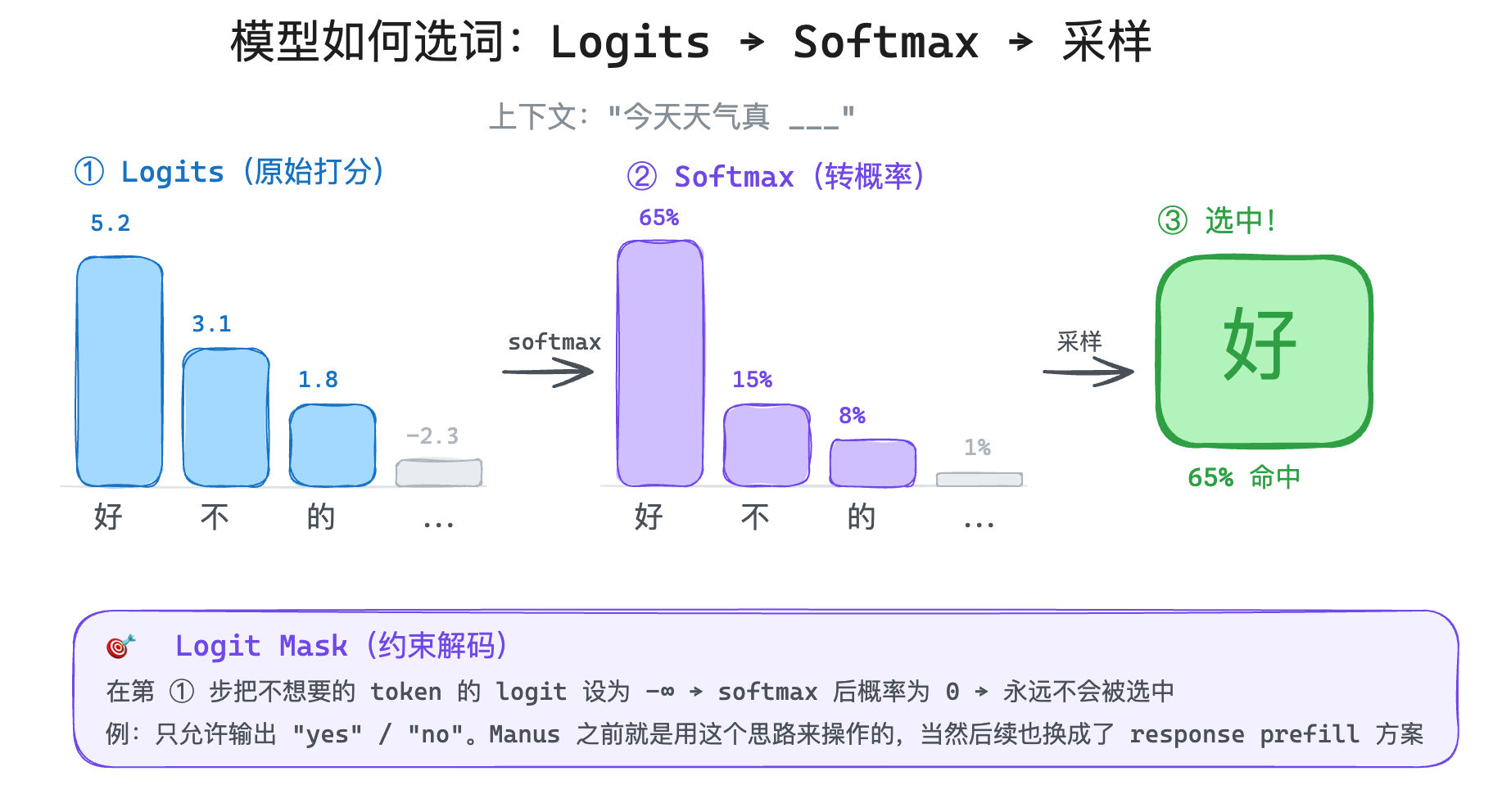
第三步:根据概率采样(Sampling)
拿到概率分布后,模型从里面"抽签"选一个 token。你可能会说了:直接拿概率最高的就可以了嘛!
但事实并非如此,概率高的只是更容易被选中,但不是确定的——这就是为什么你问模型同一个问题,有时候得到不同的回答。反过来思考,如果每次都拿概率最高了,那模型的输出基本就是那些 token 序列,就跟复读机一样,没啥智能可言了。
这里提一个你肯定用过的参数:temperature。
说个冷知识,temperature 调的是 softmax 输出的概率分布的"尖锐程度":
temperature 接近 0:概率分布变得非常尖锐,高的特别高,低的也很低,最高分的那个 token 几乎 100% 被选中。模型输出变得确定、保守。
temperature = 1:正常的概率分布,有一定的随机性。
temperature > 1:概率分布变得更平坦(或者更平均),低分 token 也有机会被选中。模型输出变得更有创意,但也更容易胡说八道。
做 Agent 的时候,一般用比较低的 temperature(0 或者接近 0),因为你希望模型做可靠的决策,而不是来一段"创意写作"。
这个"打分 → 概率 → 采样"的过程,你就能理解两个在 Agent 里非常关键的技术:
Logit Mask(约束解码)
比如我只希望模型输出 "yes" 或 "no",那我就把除了 "yes" 和 "no" 之外的所有 token 的 logit 设为负无穷(经过 softmax 后概率就是 0 了)。模型只能在 "yes" 和 "no" 之间选。
这就叫 logit mask,也叫约束解码。
Manus 在多 Agent 架构里用这个技术来确保子 Agent 的输出格式严格可控——不管模型"想"说什么,logit mask 保证它只能按规定的格式输出。
Structured Output(结构化输出)
同理,当你让模型输出一个 JSON 格式的工具调用时,模型怎么保证输出的 JSON 是合法的?
一种方式就是在每一步生成的时候,用 logit mask 只允许当前上下文下语法合法的 token。比如刚输出了 {"name": 之后,下一个 token 只能是引号 " 开头的字符串。
这就是为什么现在的模型能比较可靠地输出结构化的工具调用参数——不是它"理解"了 JSON 语法,而是在解码阶段被约束了。
Memory:长期记忆系统
掌握记忆系统的三层架构:短期工作记忆、中期对话记忆、长期向量记忆
Context Engineering 管理的是"当前对话的上下文",但如何让 Agent 记住跨对话的信息(比如昨天、上周做过的事)?
这就是 Memory(长期记忆系统) 要解决的问题。
短期记忆 → Context Engineering(当前对话的上下文,就像你的工作记忆)
长期记忆 → Memory(跨对话的持久化信息,就像大脑的海马体 + 皮层存储)
Memory 系统核心设计总结
到现在为止,你已经掌握了 Memory 系统的 4 个核心挑战:
挑战 | 解决方案 |
|---|---|
存什么? | 核心信息(用户偏好、技术栈、明确确认的配置) |
什么时候用? | 相关性检索(只召回与当前任务相关的记忆) |
怎么组织? | 向量相似度检索(Embedding + 语义搜索) |
生命周期? | 分级存储策略(高频/明确→长期,临时/一次性→短期) |
Multi-Agent:协作与隔离
理解多Agent的核心价值:上下文隔离而非角色分工
现在你的 Agent 已经拥有了:
❤️ 心跳(Agent Loop)
🦾 手脚(Tool System)
🧠 供血系统(Context Engineering)
💾 长期记忆(Memory)
但它还是单兵作战——所有任务都挤在一个上下文窗口里。
关键洞察:还记得 Manus 联合创始人说的话吗?
"人类按角色组织是因为认知限制,LLM 不一定有这些限制。"
那 Multi-Agent 的核心价值到底是什么?是角色扮演吗?Multi-Agent 的本质:上下文隔离,而不是角色扮演。
让我用一个图来强化这个认知:
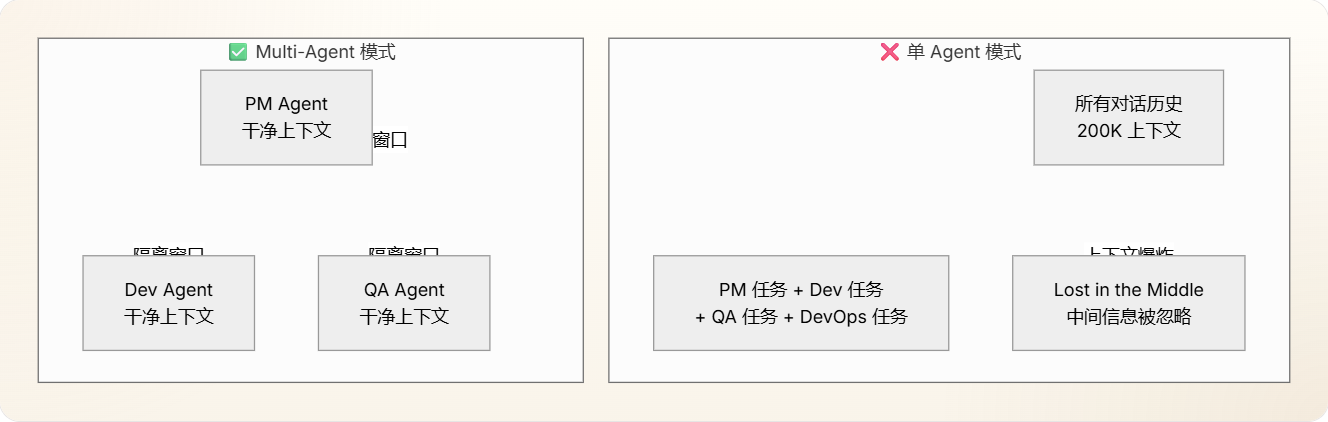
关键对比:
维度 | 单 Agent | Multi-Agent |
|---|---|---|
上下文内容 | PM 需求 + 代码 + 测试 + 部署日志 = 混乱 | 每个 Agent 只看到相关上下文 |
注意力质量 | Lost in the Middle 严重 | 每个窗口都保持高注意力 |
记忆检索 | 向量搜索范围太大,噪声多 | 每个 Agent 有独立的记忆空间 |
Multi-Agent 系统的核心设计模式,让我用一个完整的流程图来展示这个协作机制:
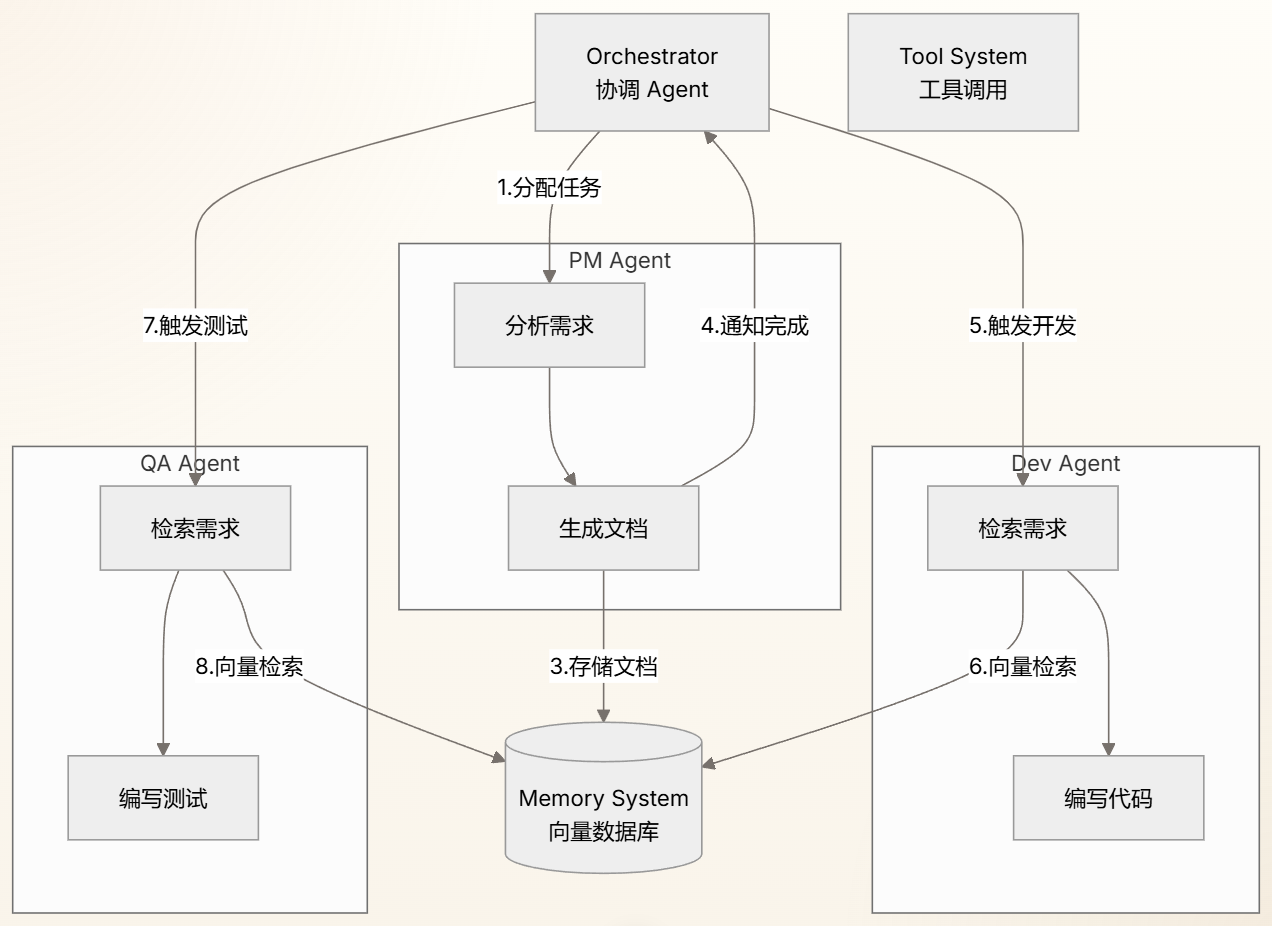
总结 Multi-Agent 的核心
你现在掌握了:
概念 | 核心认知 |
|---|---|
核心价值 | 上下文隔离,而非角色扮演 |
协作机制 | Orchestrator + Memory + Tool System |
信息传递 | 大文档存 Memory,元数据走 Tool Call |
变更传播 | 事件驱动,由 Orchestrator 协调 |
与之前知识的关联 | 依赖 Context Engineering(理解上下文管理)、Memory(向量检索)、Tool System(工具调用) |
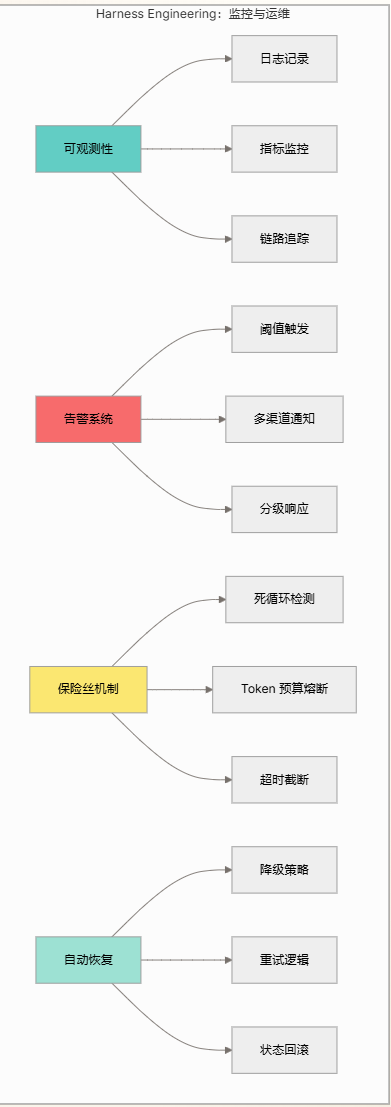
Harness Engineering:监控与运维
掌握生产级Agent的监控、日志、评估和持续改进机制
Harness Engineering 要解决的核心问题之一。
让我先画个图,展示没有监控运维系统时会发生什么:
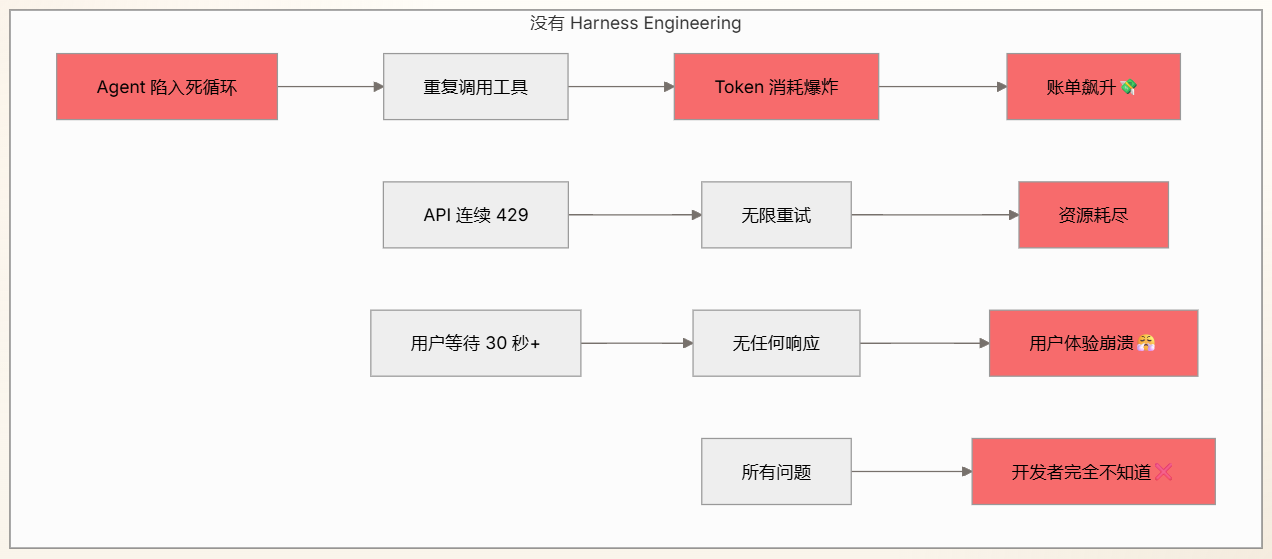
Harness Engineering 核心组件